
CSP:面向非线性电路仿真的完全稀疏化预条件子
中文题目:CSP:面向非线性电路仿真的完全稀疏化预条件子
论文题目:CSP: Comprehensively-Sparsified Preconditioner for Efficient Non-linear Circuit Simulation
录用期刊/会议:2024 ACM/IEEE International Conference on Computer-Aided Design (ICCAD) (CCF-B类会议)
原文链接:https://www.ssslab.cn/assets/papers/2024-zhao-csp.pdf
doi:10.1145/3676536.3676794
录用/见刊时间:2024-10-27
作者列表:
1) 赵雨轩 中国石油大学(北京) 人工智能学院 研22
2) 杨晓宇 中国石油大学(北京) 人工智能学院 研24
3) 柏一诺 中国石油大学(北京) 人工智能学院 本19
4) 曾礼杰 中国石油大学(北京) 人工智能学院 研24
5) 牛 丹 东南大学 自动化学院 教师
6) 刘伟峰 中国石油大学(北京) 人工智能学院 计算机系教师
7) 金 洲 中国石油大学(北京) 人工智能学院 计算机系教师
背景与动机:
求解稀疏线性系统是非线性电路仿真中最重要的性能瓶颈。在求解大规模电路矩阵时,高效的预条件子对于迭代法解法器的加速至关重要,但目前这仍然是一项极具挑战性的任务。在本文中,我们提出了一种高效的谱图稀疏化预处理方法,该方法将非线性电路元器件形成的矩阵转换为对称的拉普拉斯矩阵,使非线性和线性元件都能包含在稀疏化过程中。然后,我们将生成的稀疏子图与原始的改进节点分析(MNA)法生成的矩阵做相交操作,以进一步降低预条件子的稀疏性,从而减少预条件子的分解时间,并显著减少迭代法解法器所需的迭代次数。
设计与实现:
(1)面向非线性电路仿真的谱图稀疏化算法
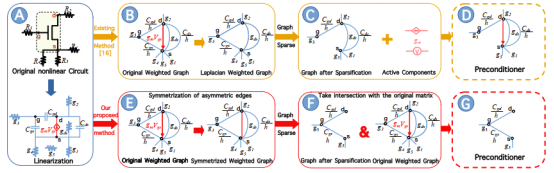
图1:利用谱图稀疏化为非线性电路生成预条件子的SOTA方法GPSCP与我们提出方法CSP的对比示意图
如图1所示,现有利用谱图稀疏化来处理非线性电路矩阵的方法,在处理非对称矩阵时,会去除非对称边,得到一个完全由线性元器件构成的对称矩阵,进而使用谱图稀疏化算法处理对称矩阵。在得到预条件子之后再将非对称边(即非线性元器件部分的元素)恢复到矩阵中。上述的方法中存在一些问题,首先是对于存在大量非对称边的矩阵(即非线性器件较多的电路),得到的预条件子的稠密度会大大增加,导致迭代求解时间开销的增加。其次是进行谱图稀疏化时忽略了非对称边信息,影响预条件子的质量。
(2)全面稀疏化预条件子算法
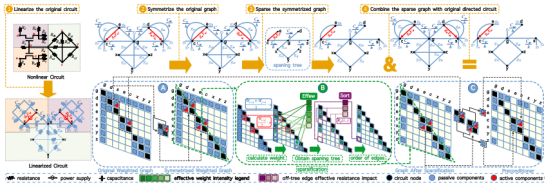
图2:CSP方法的流程展示
与现有工作不同,CSP的核心思想是在非线性元器件线性化后,将非对称边对称化,进而得到包含所有元器件的对称图,对其进行谱图稀疏化。之后,将得到的稀疏子图与原始MNA矩阵进行相交的“与”操作,仅保留原始图中的非对称边,去掉人为引入的非对称边,进一步降低预条件子的稀疏度。
大边对称策略
基于原始矩阵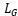 、对称化后的矩阵
、对称化后的矩阵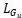 和稀疏化后的矩阵
和稀疏化后的矩阵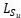 ,通过推导得到如下公式:
,通过推导得到如下公式:
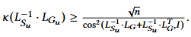
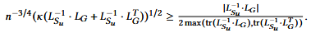
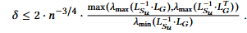
其中 代表了两个矩阵间的相对条件数,该结果表明预条件子不仅减少了
代表了两个矩阵间的相对条件数,该结果表明预条件子不仅减少了的相对条件数,还有效的减少了
的相对条件数,有利于迭代求解器减少迭代次数,减少求解时间开销。
基于以上推导的启发,我们采用大边对称的策略对原始矩阵进行对称化。我们首先将边的分布情况分为了完全对称、值不对称和位置不对称等三类,之后使用较大权重的边更新其对称位置的权重,从而对原始矩阵实现了对称化,得到对称矩阵。
非对称矩阵的谱稀疏化
为了生成质量更高的预条件子,我们在稀疏化时应该更多考虑非对称边的信息,因此我们在定义有效权重时,充分利用了非对称边的权重等信息,有效权重定义如下:
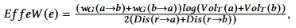
在该部分我们利用原始矩阵非对称边的权重(节点体积),和对称矩阵的节点间距离等信息,综合考虑边在非对称矩阵和对称矩阵中的重要性。
“与”操作获得预条件子
通过对非对称边和对称边的综合考虑得到稀疏子图后,我们通过“与”操作将稀疏子图和原始图进行合并处理,因此,我们得到的预条件子的稀疏度会进一步降低,并且可以进一步保留原始图中的非对称边信息。
(3)并行谱图稀疏化算法
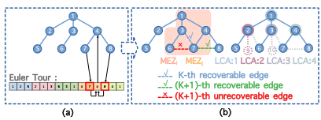
图3:并行谱图稀疏化算法示意图
块范围最大查询算法
在谱图稀疏化算法中,在构建生成树后,为了进一步降低相对条件数,需要计算所有树外边的有效电阻,并依据树外边的有效电阻和两端节点恢复一定数量的边到生成树中。在这个过程中计算有效电阻我们需要获得树外边两端节点的最近公共祖先,然而,传统的求取最近公共祖先的算法难以并行化。如图3(a)所示,本文提出了一种有效的策略,将LCA问题转化为欧拉序上的范围最大查询问题。并通过对数据块划分,我们可以对每个块进行并行操作,从而保持它们之间的最大间隔。
点独占算法
当考虑添加树外边 时,我们需要标记生成树上树其他树外边。然而,在新添加的边和其他非树边之间建立连接会带来挑战。在本文中,为了提高效率,我们创建了一个以节点和为起点的互斥区域,作用于边,这样就可以跳过具有由同一边标记的互斥端点的离树外部,如图3(b)所示。最后,为了减少内存和时间开销,我们将LCA作为一个集合对边进行分组。
时,我们需要标记生成树上树其他树外边。然而,在新添加的边和其他非树边之间建立连接会带来挑战。在本文中,为了提高效率,我们创建了一个以节点和为起点的互斥区域,作用于边,这样就可以跳过具有由同一边标记的互斥端点的离树外部,如图3(b)所示。最后,为了减少内存和时间开销,我们将LCA作为一个集合对边进行分组。
实验结果及分析:
(1)预条件子质量对比
表1:CSP、feGRASS、GPSCP等方法预条件子和迭代次数对比
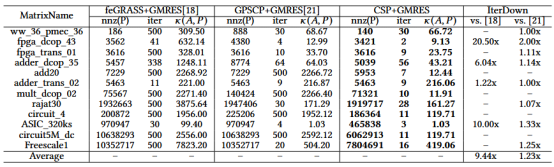
在实验中,为了展现我们CSP算法生成的预条件子质量,我们与feGRASS、GPSCP等方法进行了对比,并分别与广义最小残差法结合,统计迭代法解法器的迭代次数。实验表明,CSP算法可以生成相比feGRASS、GPSCP更稀疏的预条件子,同时相对条件数和迭代次数也更加优秀,证明了我们CSP算法的有效性。
(2)CSP算法加速矩阵求解的有效性
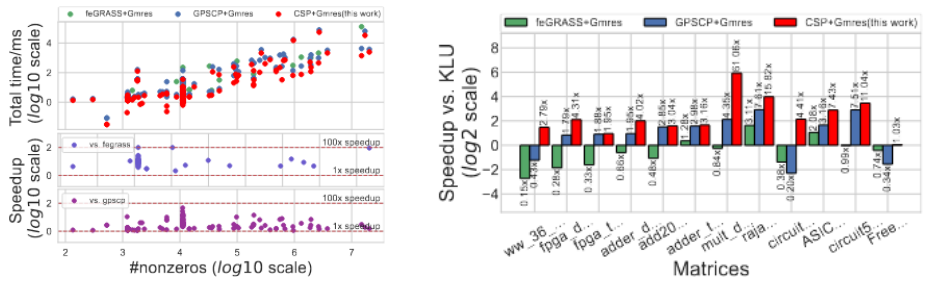
图4:(a)CSP算法相对SOTA方法加速比;(b)预条件迭代求解相对KLU求解加速比
我们对不同大小和非对称边占比的矩阵进行了测试,实验结果表明与最先进的GPSCP、feGRASS等谱图稀疏化算法生成的预条件子+GMRES迭代法解法器,以及直接法解法器KLU相比,使用CSP算法求解非线性电路矩阵时,串行平均加速比分别为2.50x、13.46x、2.18x。
(3)谱图稀疏化算法并行效率和求解器内存占用对比
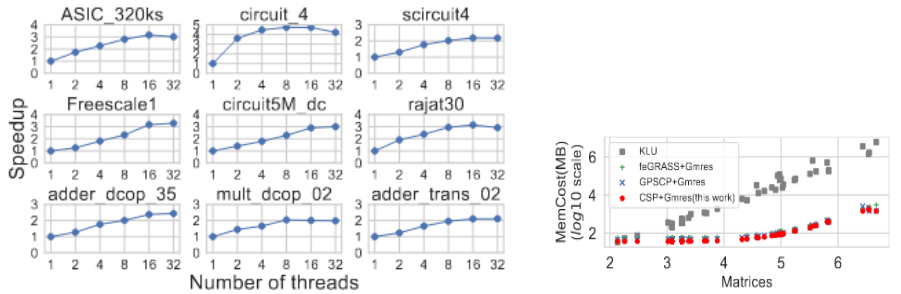
图4:(a)不同线程下并行效率 (b)不同方法的内存开销
由图可知,我们的并行策略实现了平均2.99倍的加速,并且由于我们生成的预条件子更加稀疏,CSP方法在求解时占用的内存消耗最低,且显著低于直接法解法器的内存开销。
结论:
本文提出了一种求解非线性电路仿真矩阵的预条件方法CSP。CSP通过将线性和非线性元器件矩阵都进行稀疏化生成的稀疏子图作为预条件,显著提高了迭代求解器的效率。所提出的方法增强了生成的预处理器的稀疏性,以降低预条件子分解的时间和复杂度,同时保持更好的谱相似性,以减少迭代次数并提高性能。此外,还提出了并行化技术,以进一步降低矩阵稀疏化的开销。CSP以其优越的速度和减少的内存使用提高了大型电路矩阵的求解效率。本文通过大量矩阵证明了我们算法的有效性,我们与最先进的GPSCP、feGRASS等谱图稀疏化算法+GMRES迭代法解法器,以及电路仿真中先进的直接法解法器KLU相比,在求解非线性电路矩阵时,我们的方法串行平均加速为2.50x、13.46x、2.18x,并行平均加速3.72x、24.23x、3.86x,内存平均减少21.3%、21.7%、88.0%。
通讯作者简介:
金洲,中国石油大学(北京)计算机系副教授,入选北京市科协青年人才托举工程、中国石油大学(北京)青年拔尖人才。主要从事集成电路设计自动化(EDA)、面向科学计算的DSA软硬件协同设计等方面的研究工作。主持并参与国家自然科学基金青年项目、重点项目,科技部重点研发微纳电子专项、高性能计算专项青年科学家项目,国家重点实验室开放课题、企业横向课题等二十余项。在DAC、TCAD、TODAES、SC、PPoPP、IPDPS、TCAS-II、ASP-DAC等重要国际会议和期刊上发表60余篇高水平学术论文。是DAC、SC、TCAD、TPDS等顶会顶刊的程序委员会委员和审稿人。获SC23最佳论文奖、SC24最佳论文奖提名、EDA2青年科技奖、ISEDA23荣誉论文奖、IEEJ九州支部长奖等。
联系方式:jinzhou@cup.edu.cn