
ReCG: 在ReRAM上利用存算一体加速稀疏共轭梯度解法
中文题目:ReCG: 在ReRAM上利用存算一体加速稀疏共轭梯度解法器
论文题目:ReCG: ReRAM-Accelerated Sparse Conjugate Gradient
录用期刊/会议:The 61st Design Automation Conference (DAC)(CCF-A类会议)
录用/见刊时间:2024年2月27日
原文DOI:https://doi.org/10.1145/3649329.3656515
作者列表:
1)范明嘉 中国石油大学(北京)人工智能学院 计算机技术 硕21
2)陈晓明 中国科学院计算技术研究所
3)杨德闯 中国石油大学(北京)人工智能学院 计算机技术 硕21
4)金 洲 中国石油大学(北京)人工智能学院 计算机系教师
5)刘伟峰 中国石油大学(北京)人工智能学院 计算机系教师
文章简介:
在本工作中,我们提出了一种利用电阻式随机存取存储器 (ReRAM) 来加速稀疏共轭梯度 (CG)的存算一体架构ReCG,相比于存算分离的CPU、GPU和FPGA架构,ReCG在更低能耗的情况下获得了更高的性能。
摘要:
稀疏线性系统求解在科学计算中是至关重要的。稀疏共轭梯度(CG)是最著名的迭代法解法器之一,具有效率高、存储要求低的特点。然而,在存储和计算分离的架构上实现的稀疏CG解法器,其性能受到不规则内存访问和大量数据传输的极大限制。在本工作中,我们提出了一种基于电阻式随机存取存储器(ReRAM)的存算一体(PIM)架构ReCG,用于加速稀疏CG解法器。ReCG的设计面临三大挑战:(1)如何使复杂的稀疏CG更适合使用基于ReRAM的架构进行加速;(2)如何将稀疏和不规则操作映射到更适合密集操作的规则crossbars上;(3)如何协调硬件单元之间的数据流,以尽量减少ReRAM写耐久性较差对加速CG的影响。为了解决这些挑战,我们(1)通过详细分析了算法中操作的共性来对稀疏CG的kernels进行分类,并设计一个灵活的专用架构;(2)利用内容可寻址存储器(CAM)和MAC crossbars来有效地实现稀疏和不规则的操作;(3)提出一种新的数据流调度策略。实验结果表明,与CPU和GPU上的PETSc以及FPGA上的CALLIPEPLA相比,ReCG的性能分别最高提高了3个数量级、1个数量级和1个数量级,能耗分别最高降低了2个数量级、2个数量级和1个数量级。
背景与动机:
稀疏CG是科学计算领域里最为重要的线性解法器之一。然而目前稀疏CG加速工作都是在存算分离架构上实现的,导致在处理器和内存之间的数据移动开销很大。为了突破存算分离架构的限制,快速读取访问数据,本工作提出了一个用于稀疏CG加速的基于ReRAM的PIM架构ReCG。
设计与实现:
整个CG算法是相当复杂的,涉及由标量、向量、矩阵和稀疏类型等多种算子组成的各种操作,总共超过10种(如Algorithm 1所示)。在基于ReRAM的硬件上直接实现CG需要实现所有操作。然而,这种方法需要构建10多个不同的硬件模块,并在每个模块内为不同类型的算子设计单独的组件。对于矩阵规模稍大的问题,这种架构会变得复杂且庞大,导致巨大的硬件成本。

我们注意到整个CG算法中算子的共性,将所有操作分为三类:稀疏算子计算,即SpMV;Reduction操作;向量计算。根据这三类操作,我们设计了一个专用的架构,如图1所示,其包括五个主要组件:(1)SFU、(2) VFU、(3)SPU、(4)Central Controller和(5)Global Buffer。
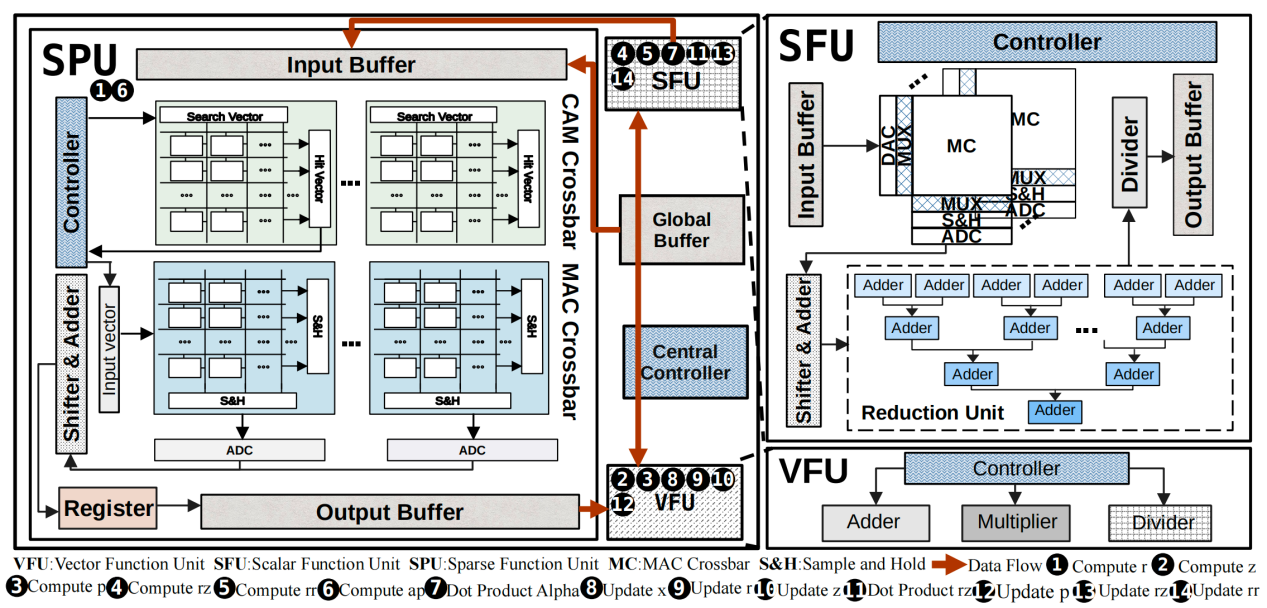
图1:架构图
其次,我们发现SpMV在加速CG过程中具有关键作用,是算法迭代中的核心步骤。我们使用图2的例子去描述用ReCG架构中的SPU模块去实现SpMV的工作流程。将实现SpMV的过程分为了四个阶段:压缩阶段,加载阶段,搜索阶段和计算阶段。这四个阶段是顺序执行的,但在同一个阶段中可以同时并行执行多组数据。
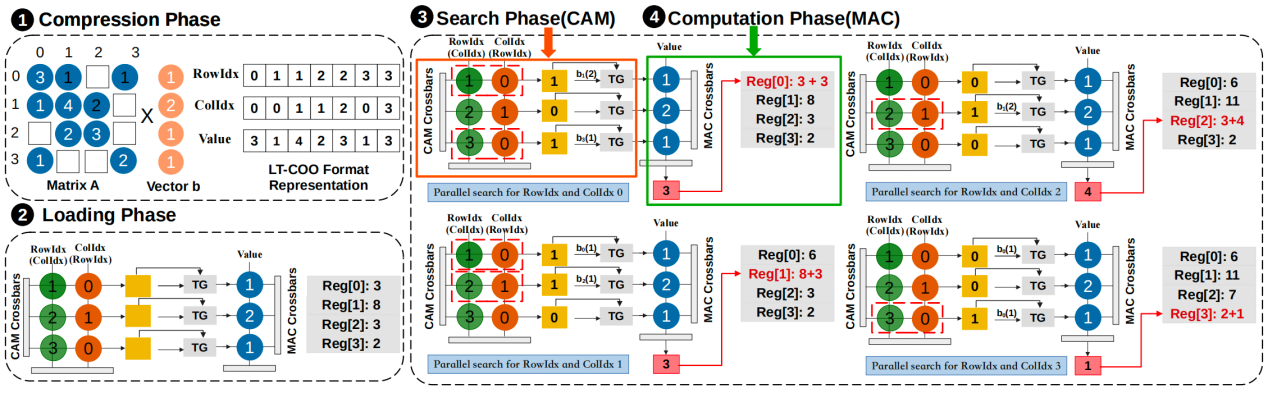
图2:SpMV过程
最后,我们对算法每个步骤中的标量、向量和矩阵依赖关系进行了详细分析,并制定了新的数据流调度策略,如图3所示。我们发现阶段内操作可以并行执行,整个架构中的模块也具备并行执行能力,从而提高了并行性,加速了算法的执行过程。同时,我们减少了数据搬运次数和写次数,尽可能地减少ReRAM写耐久性差对加速算法的影响。

图3:调度策略
实验结果及分析:
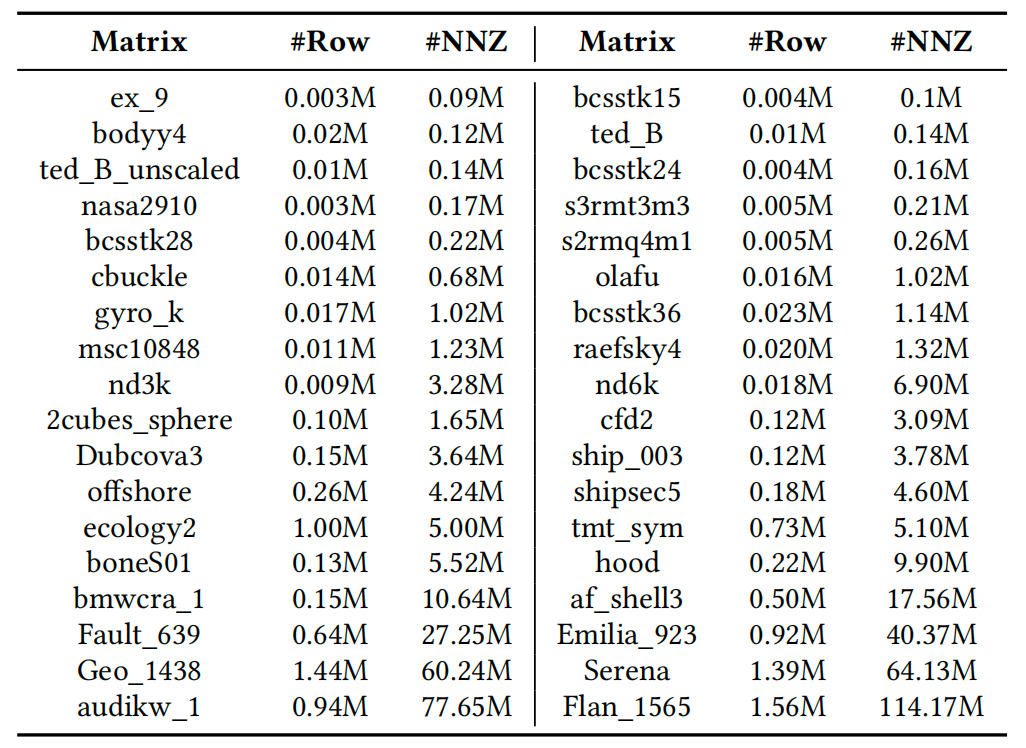
本工作评估了来自SuiteSparse Matrix Collection的36个稀疏矩阵,它们来自计算流体力学问题、电力网络问题、结构问题等不同领域,表1提供了每个矩阵的信息。我们使用NeuroSim和NVSim对ReCG的性能和能耗进行仿真,并与CPU和GPU上的PETSc以及FPGA上的CALLIPEPLA进行性能和能耗比较。
表1:矩阵信息
本工作测试了36个矩阵在四种平台(CPU、GPU、FPGA 和 ReRAM)上的求解时间,其实验结果如图4所示。通过进行分析比较后发现,对于前11个较小规模的矩阵(即从矩阵ex_9到矩阵cbuckle),ReCG 的求解时间平均比CPU上的PETSc快一个数量级,平均比GPU上的PETSc快两倍。然而,与FPGA上的加速器CALLIPEPLA相比,ReCG却需要更多的时间进行求解。对于后25个较大规模的矩阵(即从矩阵olafu到矩阵Flan_1565),ReCG展示出更好的加速。与CPU、GPU和FPGA这三种平台上加速器相比,ReCG分别达到了3个数量级、1个数量级和1个数量级的最高加速水平。此外,根据实验结果还可以看出,随着矩阵规模的增加,ReCG的加速效果越好,这表明ReCG具有良好的可扩展性。
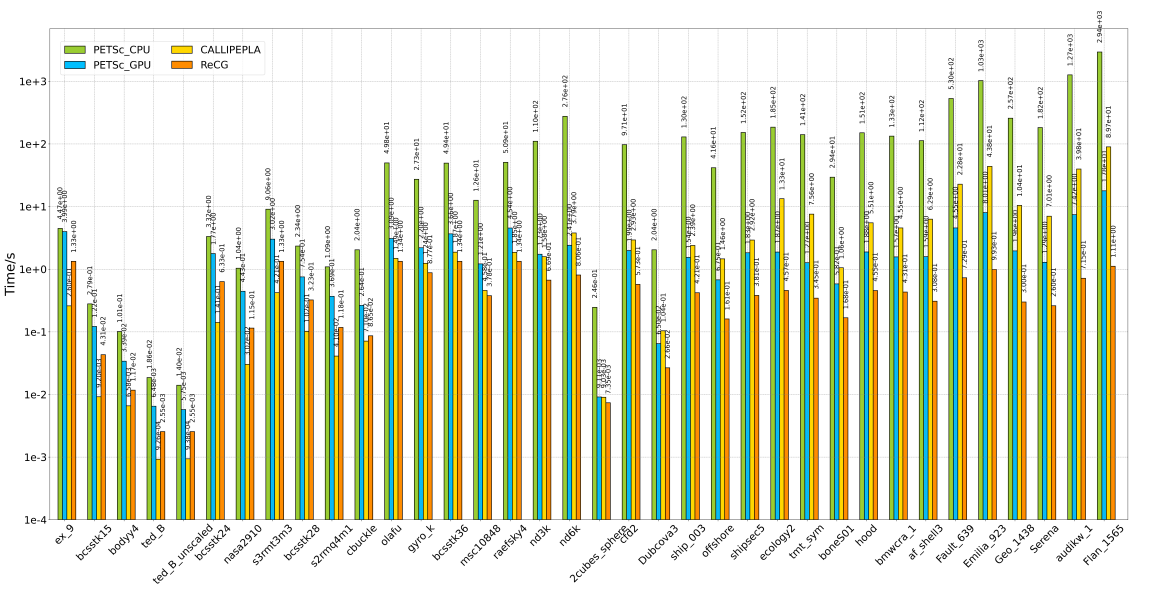
图4:四种加速器:CPU和GPU上的PETSc,CALLIPEPLA和ReCG的求解时间
图5显示了在不同平台 (CPU、GPU、FPGA 和 ReRAM)上的能耗。对于不同规模的稀疏矩阵来说,相比于在CPU、GPU和FPGA上加速JPCG,ReCG都是能耗最低的,分别最高可降低了2个数量级,2个数量级和1个数量级。

图5:四种加速器:CPU和GPU上的PETSc,CALLIPEPLA和ReCG的能耗
为了尽可能减少ReRAM写耐久性差对加速JPCG所带来的影响,我们制定了新的调度策略。在这个调度策略之下,大大减少了在ReRAM上的写时间,如图6所示。我们可以看出采用新的调度策略后,写时间减少了50%左右,验证了调度策略的有效性。
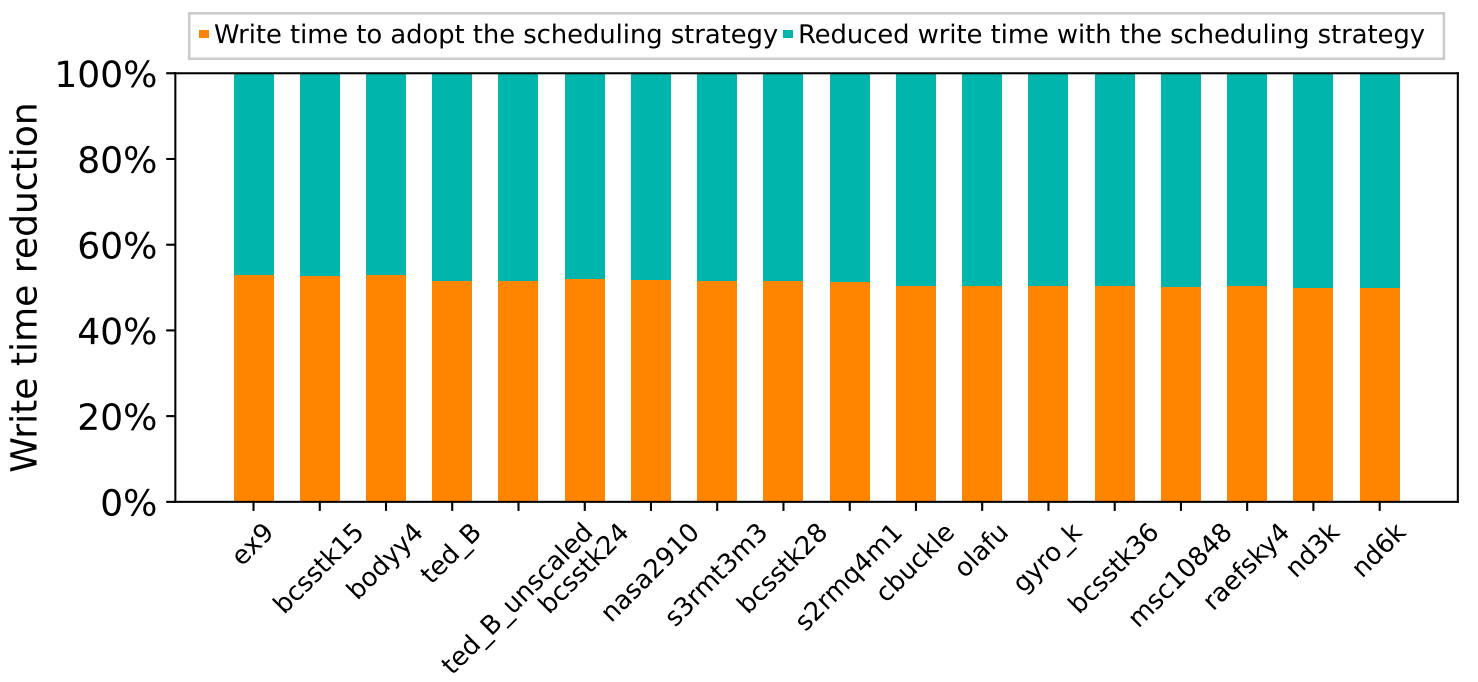
图6:采用调度策略后的写时间和减少的写时间
结论:
ReRAM crossbars支持的原位矩阵向量乘法为利用PIM硬件加速数值计算应用开辟了一个新方向。然而,当规则的crossbars遇到不规则稀疏矩阵时,必须解决工作负载映射和数据流调度等关键挑战,才能在规则的ReRAM crossbars上高效运行不规则矩阵运算。在本工作中,我们提出了一种基于ReRAM架构的加速器ReCG,它能有效加速JPCG。对于JPCG,我们设计了多个模块来实现JPCG的各种kernels。我们还提出了一种新的数据流调度策略来减少数据搬运。实验结果表明,与CPU和GPU上的PETSc以及FPGA上的CALLIPEPLA相比,ReCG的性能分别最高提高了3个数量级、1个数量级和1个数量级,能耗分别最高降低了2个数量级、2个数量级和1个数量级。
通讯作者简介:
金洲,中国石油大学(北京)计算机系副教授,入选北京市科协青年人才托举工程、校青年拔尖人才。主要从事集成电路设计自动化(EDA)、面向科学计算的DSA软硬件协同设计等方面的研究工作。主持并参与国家自然科学基金青年项目、重点项目,科技部重点研发微纳电子专项、高性能计算专项青年科学家项目,国家重点实验室开放课题、企业横向课题等。在DAC、TCAD、TODAES、SC、PPoPP、IPDPS、TCAS-II、ASP-DAC等重要国际会议和期刊上发表60余篇高水平学术论文。获EDA2青年科技奖、SC23最佳论文奖、ISEDA23荣誉论文奖、IEEJ九州支部长奖等。
联系方式:jinzhou@cup.edu.cn