
PFPMine:一种面向数据密集型云工作流的关联数据实体发现方法
论文题目:PFPMine: A parallel approach for discovering interacting data entities in data-intensive cloud workflows
录用时间:2020年7月7日
发表期刊:Future Generation Computer Systems(SCI检索,JCR:Q1)
作者列表:
(1)黄昱泽,重庆交通大学,信息科学与工程学院,讲师
(2)黄霁崴,中国石油大学(北京),信息科学与工程学院,教授
(3)刘 聪,山东理工大学,计算机科学与技术学院,教授
(4)张呈宁,新加坡Grab公司,数据工程师
DOI链接:https://doi.org/10.1016/j.future.2020.07.018
论文简介:
为了高效利用资源,需要将工作流部署于云环境之中。由于数据密集型工作流会对大量数据进行操作,本文提出了一种基于频繁模式的云工作流关联数据发现和管理方法,并基于MapReduce框架对算法进行并行化以提高效率。解决了在数据密集型工作流中发现关联数据的问题。通过使用真实数据集来评估该方法的效率,证明了我们的方法与传统方法相比可以更高效的发现云工作流中的关联数据。
背景与动机:
云计算作为一种新兴的计算模式能够将计算和存储作为一种服务提供给用户使用。云计算对资源的高效利用,可以显著提高工作流的执行效率。随着云计算的广泛应用,为了高效利用资源,越来越多的公司或机构将其工作流部署于云环境中,由于数据密集型工作流会对大量数据进行操作,因此在将数据密集型工作流部署于云环境的过程中面临着许多新的挑战。
设计与实现:
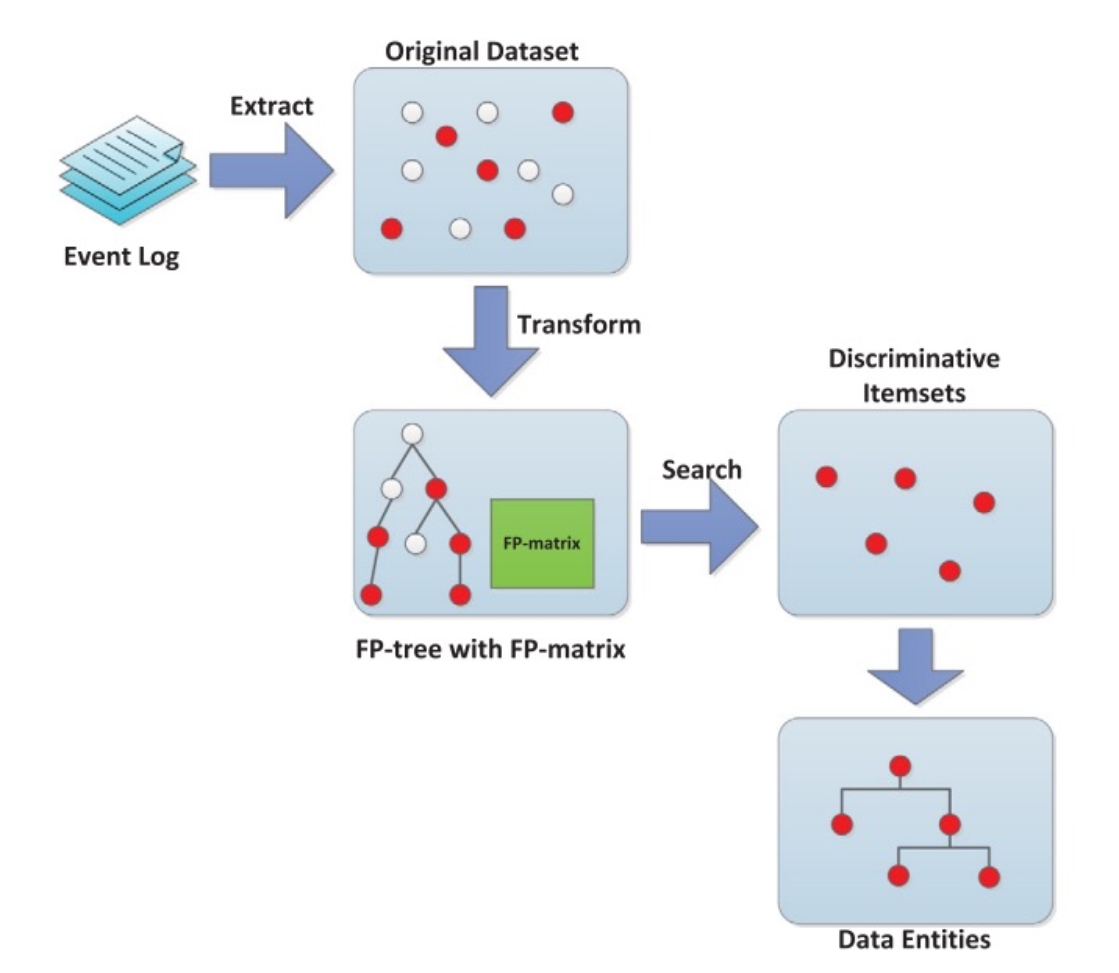
图1FPMine总体框架
图1介绍了一种基于频繁模式的关联数据发现方法的总体框架,该方法通过对工作流日志进行分析,揭示出数据中的关联关系,区分出数据间的重要程度。
频繁模式挖掘算法的基础是设定合适的支持度阈值。然而目前的频繁模式挖掘算法大多采用人为设定的方法设定最小支持度阈值,显然这存在明显的问题。虽然已经有许多研究学者设计了一些自动化设定最小支持度阈值的方法,但这些方法大多基于监督学习或穷举法,这将会导致算法的效率较为低下。为了解决这个问题,本文提出了一种自动化设定最小支持度阈值的方法,该方法基于数据项的统计分布特征,且不需要训练数据。设定最小支持度阈值的详细步骤如算法1所述。

频繁模式挖掘算法的基本思想是通过遍历FP树来查找频繁项集。为了提高算法的执行效率,本文重新设计了该算法用于查找频繁二项集,设计了一种新的数据结构,命名为FP矩阵。FP矩阵存储了每对数据项的频度信息及兴趣度度量值。算法2为FP树及FP矩阵构造算法。FP树及FP矩阵如图2(b)和(c)所示。

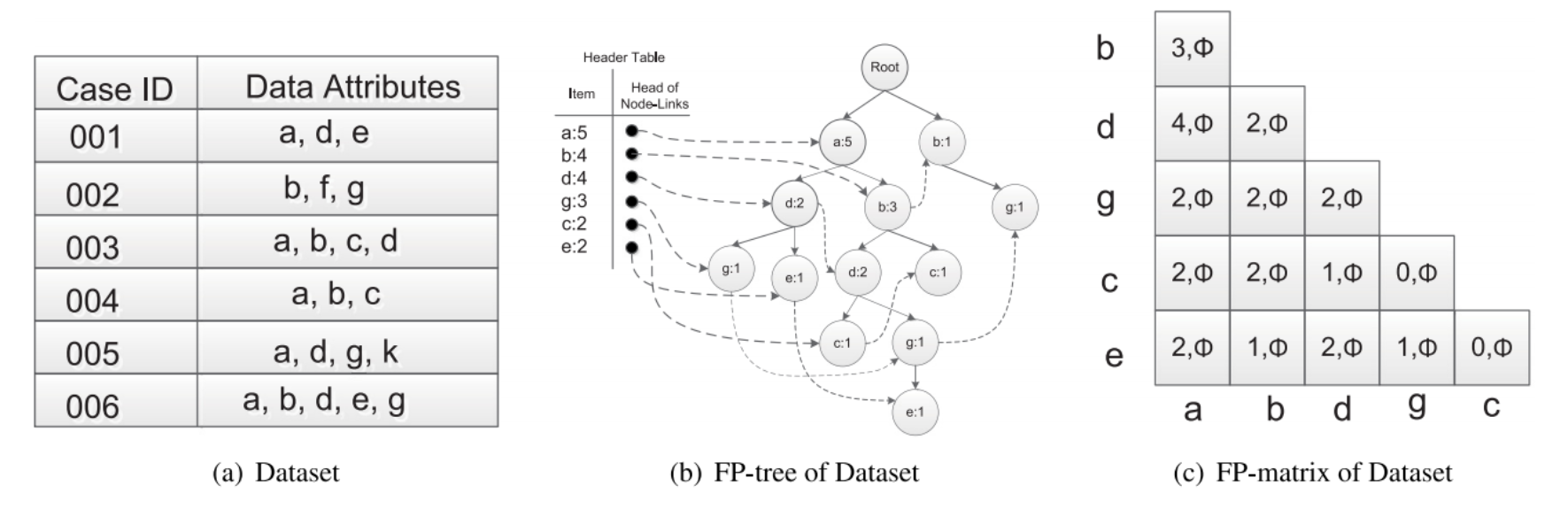
图2 FP树及FP矩阵
构建了FP树和FP矩阵,下面将直接挖掘具有区分力的频繁项集。与传统的频繁模式挖掘算法不同,本文提出一种直接挖掘具有区分力的频繁二项集的算法,关注于挖掘频繁二项集,而非频繁模式,这将消耗更少的时间和资源。详细的频繁二项集挖掘算法如算法5所示。

为了应对大规模数据集,本章提出了一种基于频繁模式的并行化挖掘算法,并将其命名为PFPMine。该算法使用MapReduce框架将前面章节中提出的FPMine算法做并行化处理。图3为相应的PFPMine总体框架图。
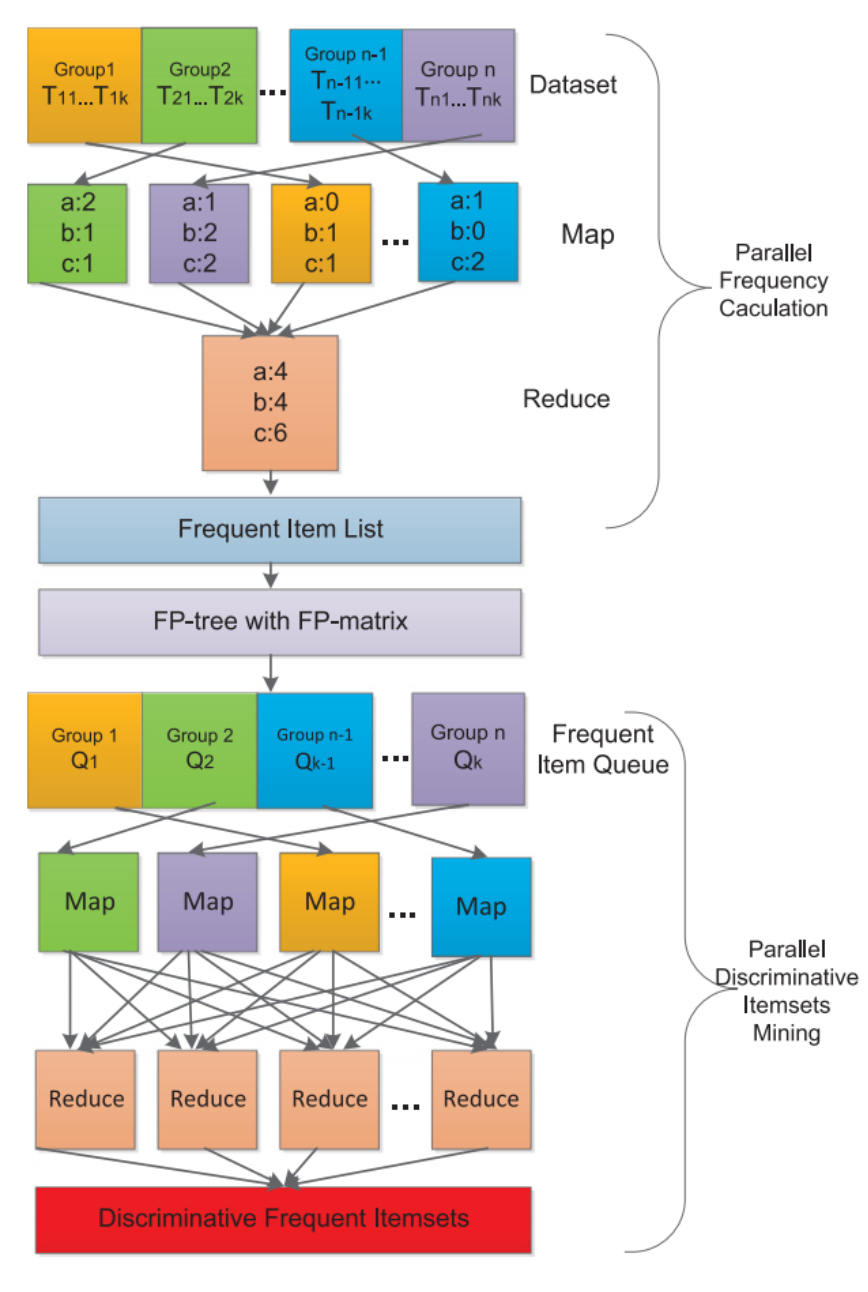
图3 PFPMine总体框架图
实验结果:
本文采用真实数据集对PFPMine算法进行功能性评估。图4(a)和图4(b)为采用PFPMine和FP-growth对三个不同的数据集进行挖掘,并采用上述两种不同的时延计算通信代价。结果表明采用PFPMine算法的通信代价明显低于采用传统的FP-growth算法所计算出的通信代价。
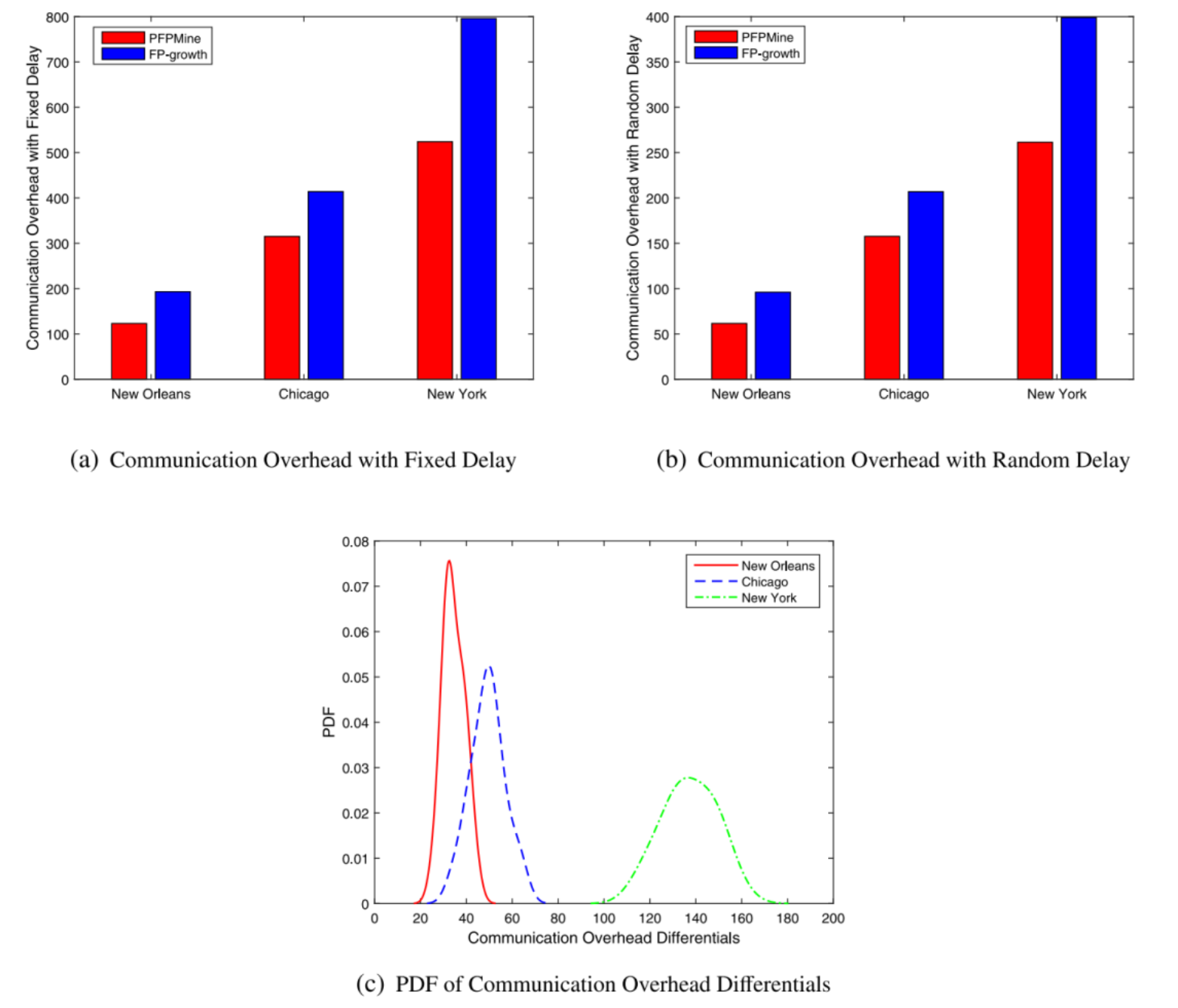
图4通信代价
作者简介
黄霁崴博士,教授,博士生导师,石油数据挖掘北京市重点实验室主任,中国石油大学(北京)计算机科学与技术系主任。2015年度北京市优秀人才,2018年度中国石油大学(北京)优秀青年学者,2020年度北京市科技新星。分别在2009年和2014年于清华大学计算机科学与技术系获得工学学士和工学博士学位,2012-2013年国家公派赴美国佐治亚理工学院联合培养。研究方向包括:系统性能评价和优化、随机模型理论和应用、服务质量测量与保障技术、服务计算和物联网等。担任中国计算机学会(CCF)服务计算专委会委员,CCF高级会员,IEEE、ACM会员。已主持国家自然科学基金、北京市自然科学基金等科研项目13项,在国内外著名期刊和会议发表论文五十余篇,出版学术专著1部,获得国家发明专利5项、软件著作权3项,担任多个国际顶级期刊和知名会议审稿人。联系邮箱:huangjw@cup.edu.cn。