
面向疫情防控领域中文事件抽取
中文题目:面向疫情防控领域中文事件抽取
论文题目:Chinese Event Extraction for Epidemic Prevention and Control Domain
录用会议:The 2024 Twentieth International Conference on Intelligent Computing (CCF C)
作者列表:
1) 李晓雪 中国石油大学(北京)人工智能学院 硕23
2) 王智广 中国石油大学(北京)人工智能学院 计算机科学与技术系 教师
3) 刘志强 中国石油大学(北京)人工智能学院 硕23
4) 祝留宇 中国石油大学(北京)人工智能学院 硕23
5) 葛赛赛 中国石油大学(北京)人工智能学院 硕19
6) 鲁 强 中国石油大学(北京)人工智能学院 智能科学与技术系 教师
摘要:
事件抽取是信息抽取的热点研究内容,本文研究疫情防控领域的事件抽取任务,该任务研究中还存在很多问题,如当前没有针对疫情防控领域事件的数据集;存在长触发词和多触发词情况导致机器出现漏抽、错抽问题;事件论元分布不平衡影响抽取结果等。针对以上问题,该文首先构建了针对重大疫情防控事件的数据集EEPCD;接着提出基于依存句法分析的事件触发词抽取算法A-DPETE,该算法通过依存句法分析技术,使得模型在长触发词和多触发词抽取准确率上有了较大提升;最后构建了触发词特征嵌入的事件论元抽取模型EM-TFEEA,该模型将事件触发词抽取与事件论元抽取结合起来,同时使用分组抽取原则,提高了事件论元抽取的准确性。实验结果表明,在 EEPCD 数据集和 ACE2005 中文数据集上,其效果优于传统技术。在事件触发词抽取方面,准确率、召回率和 F1 值最大提高了6.0%;在事件论元抽取方面,这些指标最大提高了3.0%。
设计与实现:
1、A-DPETE算法的实现
在汉语中,我们可以观察到一种普遍的语法现象,即各语言单位之间存在着支配和被支配、依存和被依存的关系。通过进行依存句法分析,我们可以更好地理解句子中各成分之间的语义修饰关系,同时获取长距离的上下文信息。因此我们将使用依存句法分析技术进行触发词抽取算法设计。
通过对含多触发词事件句的分析可得到规则如下:
规则1:从词性上看,如果核心词是动词,那么就将该触发词添加到触发词链。否则考虑与依存句法分析得到的核心词并列的动词。
规则2:如果某动词与核心词并列,但未与核心词相邻,则将该动词添加到事件触发词链中。若与核心词相邻,则可考虑是否构成长触发词问题。
规则3:从词性上看,如果核心词不是动词,同时也没有与核心词并列的动词,那么该事件句就不会生成触发词链。
针对以上3个规则,可得出触发词链生成算法,如算法1所示。

通过对含长触发词事件句的分析可得到规则如下:
规则4:依存句法分析得到的核心词如果没有相邻的动词,那么不会构成长触发词。
规则5:如果核心动词与相邻动词的句法依存关系是并列关系,那么将构成长触发词;否则,将不会构成长触发词。
规则6:如果核心词词性不是动词,那么不会构成长触发词。
根据规则可以得到算法2。

2、EM-TFEEA模型的构建
图3展示了触发词语义特征嵌入的事件论元抽取模型的总体结构图。
模型的输入是事件句加触发词的距离特征编码。触发词的距离特征编码定义为文本中所有字到触发词的相对距离,而触发词本身的距离编码为0。触发词周围的单词成为事件论元的概率更大,因此模型加入触发词距离特征来辅助事件论元抽取任务。该模型主要包括四个部分:①预训练层;②CLN层;③CRF层;④分类器层。
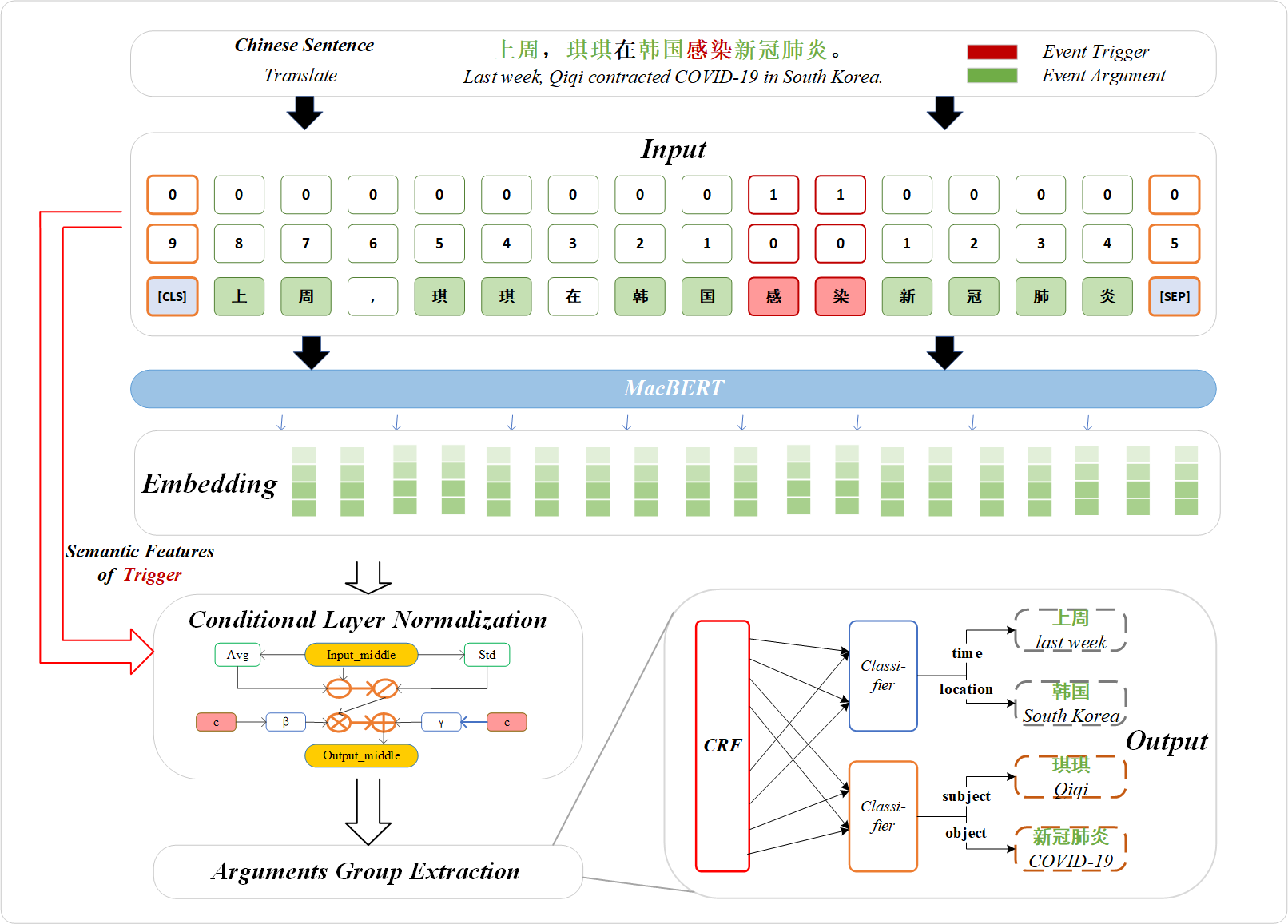
图1 EM-TFEEA模型结构图
(1)预训练层:使用MacBERT预训练模型提升对文本语义的理解能力,尤其是触发词与事件论元间的语义关系。
(2)条件层归一化 (CLN):使用语义信息作为一个额外的条件,与词向量一起输入到神经网络的输入层中。在网络的中间层中,使用 CLN进行归一化,从而使得不同的语义信息可以自适应地学习到适合的归一化参数。最后,可以将归一化后的表示输入到一个分类器或者序列标注模型中,用于抽取事件论元。
(3)条件随机场 (CRF):在序列标注任务中使用CRF模型,定义不同事件类型的标签集和标签转移矩阵,增强模型的泛化能力和准确性。
(4)分类器:本文使用两个二分类器,将时间和地点作为一组,主体和客体作为一组,以降低事件论元分布不平衡对模型的准确率、召回率以及F1值的影响。
实验结果及分析:
1、触发词抽取算法的实验结果及分析
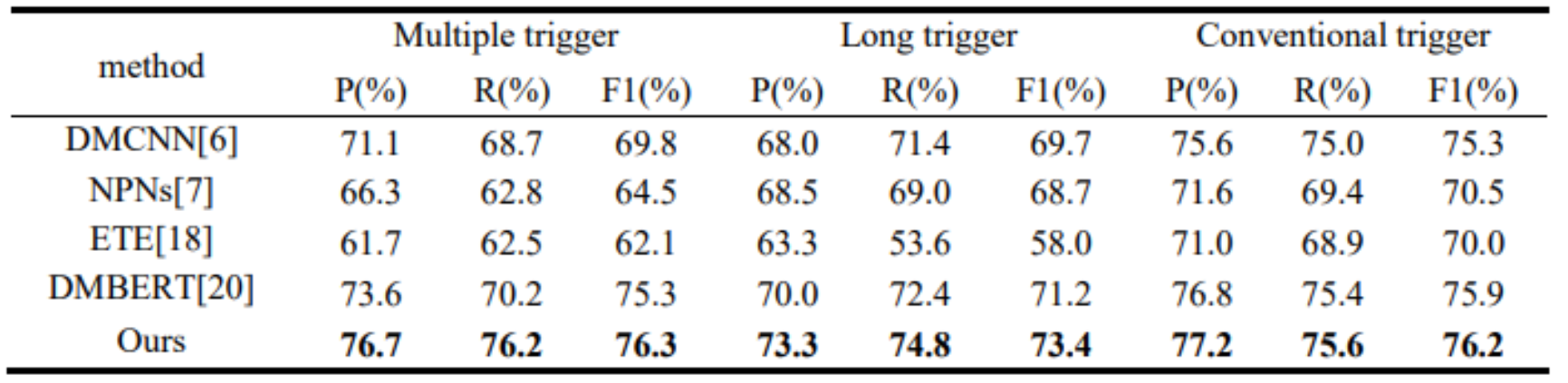
表1和表2显示,本文提出的触发词抽取算法在EEPCD数据集和ACE 2005数据集上都表现良好。这是由于本文提出的抽取算法考虑了长触发词和多触发词的现象,对包含长触发词和多触发词的事件句进行了详细的分析和理解,同时利用依存句法分析工具来更好地捕捉触发词之间的关系,并最大限度地减少它们的遗漏。
表1 ACE2005数据集上算法的指标对比结果
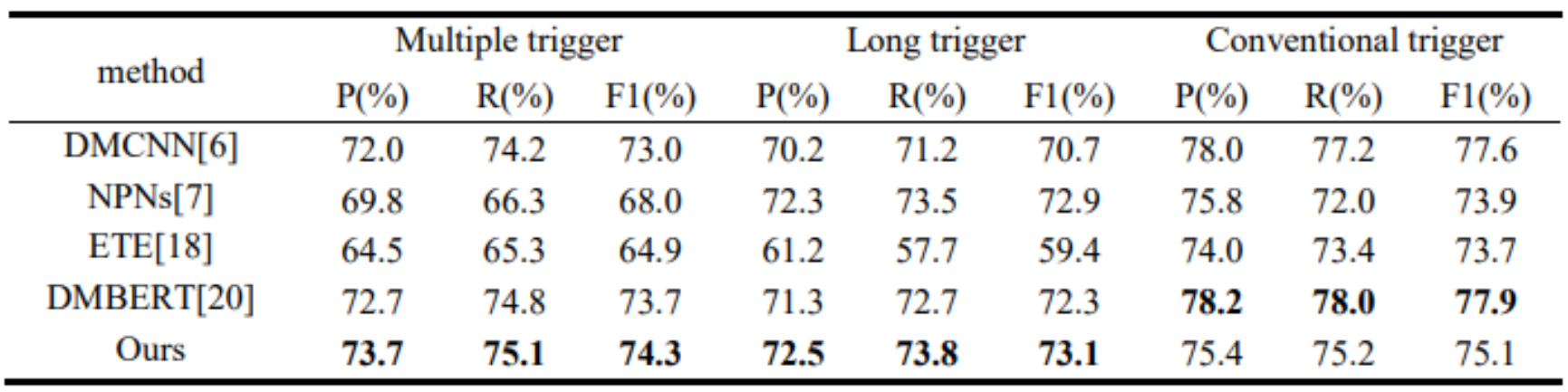
表2 EEPCD数据集上算法的指标对比结果
2、 事件论元抽取模型实验结果及分析:
(1)对比实验:
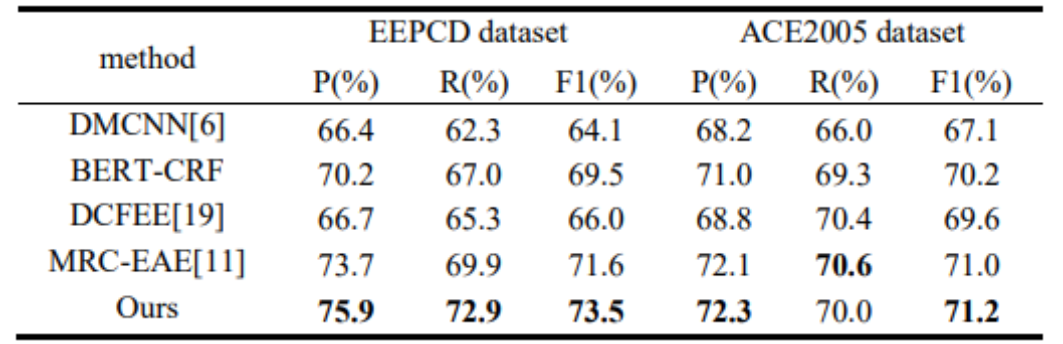
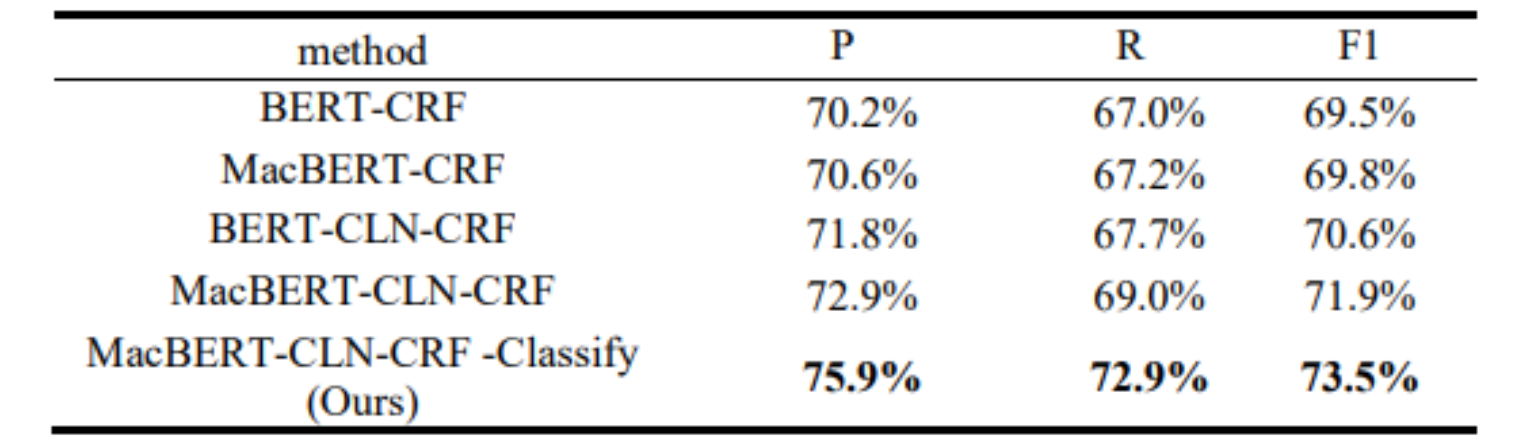
本文设置了对比实验,在EEPCD数据集与ACE2005数据集上与其他主流算法对比。通过表3可以看出,本文提出的模型,在EEPCD数据集上无论是准确率、召回率还是F1值都有显著提升;而在ACE 2005数据集上虽然召回率没有提升,但在准确率和F1值上都明显优于其他模型。
表3对比实验结果
(2)消融实验:
通过五组消融实验,可以看到在面向疫情防控领域新闻数据集上,各个模块对BERT-CRF模型都有提升效果,在使用MacBERT替换成BERT的同时加入CLN层,并使用论元分组抽取的策略,使本章模型得到了最大程度地提升。综上所述,本章模型能有效地抽取事件论元。
表4 消融实验结果
结论:
针对重大疫情防控事件缺乏数据集的问题,本文初步构建了一个专注于该领域的数据集。然后,针对事件句子中由于多触发词和长触发词的存在而导致的错抽、漏抽问题,本文采用了一种基于依存句法分析的事件触发词抽取算法。最后,针对事件触发词和事件论元抽取任务分离以及事件论元分布不平衡导致的抽取精度低的问题,开发了一种嵌入触发词特征的事件论元抽取模型。实验结果表明,所提出的方法应用于EEPCD数据集和ACE2005中文数据集,均优于传统技术。事件触发词抽取的准确性、召回率和F1分数最高提高了6.0%,而事件论元抽取的这些指标最高提高了3.0%。这项工作可以辅助下游的知识图谱构建任务,能更好地帮助公众了解疫情发展趋势,进行有效的预防。然而,就传统触发词抽取的准确性以及触发词抽取结果对后续结果的影响方面,本文提出的方法尚待优化。今后的工作将侧重于提高这些领域的效果。
作者简介:
王智广,教授,博士生导师,北京市教学名师。中国计算机学会(CCF)高级会员,全国高校实验室工作研究会信息技术专家指导委员会委员,全国高校计算机专业(本科)实验教材与实验室环境开发专家委员会委员,北京市计算机教育研究会常务理事。长期从事分布式并行计算、三维可视化、计算机视觉、知识图谱方面的研究工作,主持或承担国家重大科技专项子任务、国家重点研发计划子课题、国家自然科学基金、北京市教委科研课题、北京市重点实验室课题、地方政府委托课题以及企业委托课题20余项,在国内外重要学术会议和期刊上合作发表学术论文70余篇,培养了100余名硕士博士研究生。