
机器学习和GPU加速晶体管级电路仿真中的稀疏线性求解器:综述论文
中文题目:机器学习和GPU加速晶体管级电路仿真中的稀疏线性求解器:综述论文
论文题目:Machine learning and GPU accelerated sparse linear solvers for transistor-level circuit simulation: a perspective survey (Invited paper)
录用期刊/会议:29th Asia and South Pacific Design Automation Conference (CCF-C)
原文DOI:10.1109/ASP-DAC58780.2024.10473846
原文链接:https://doi.org/10.1109/ASP-DAC58780.2024.10473846
作者列表:
1) 金 洲
中国石油大学(北京)信息科学与工程学院 计算机科学与技术系教师
2) 李文豪 中国石油大学(北京)信息科学与工程学院 计算机技术 硕22
3) 柏一诺 中国石油大学(北京)信息科学与工程学院 电子信息工程 本19
4) 王腾程 中国石油大学(北京)信息科学与工程学院 计算机技术 硕21
5) 鲁一澄 中国石油大学(北京)信息科学与工程学院 电子信息工程 本19
6) 刘伟峰 中国石油大学(北京)信息科学与工程学院 计算机科学与技术系教师
背景与动机:
SPICE电路仿真中求解稀疏线性系统不仅占据了大部分的仿真时间,电路尺寸的快速增加也进一步加剧了稀疏线性求解器需要更多的执行时间和内存资源。因此,高性能稀疏线性求解器成为加速电路仿真和验证的关键。近年来,AI技术的蓬勃发展和硬件能力的不断增强为加速稀疏线性求解提供了新的机会。本文提供了对这些技术进步的总览,同时也探讨了目前面对的挑战和未来机遇。
主要内容:
在稀疏LU分解的预处理阶段采用不同的行列重排序方法会对性能有不同的影响(如图1)。对此,Ganqu Cui等人结合支持向量机和神经网络提出了一种基于AI来分析并选择最佳重排序方案的算法。但目前所有现有的基于AI的策略通常都是从现有方法中的选择最佳替代方案。利用半监督或无监督学习为矩阵生成特定的最优重排序方法在未来是非常有前途的方向。
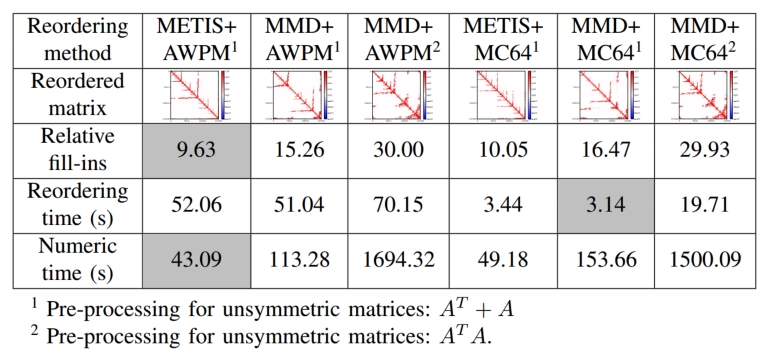
图1 电路仿真矩阵采用不同重排序方法的性能比较
在稀疏LU分解的数值分解阶段采用不同类型的矩阵乘法也会产生不同的性能(如图2)。TengCheng Wang提出了一种配备随机森林的密度感知自适应矩阵乘法以对不同的子矩阵块选择性能最优的矩阵乘法,来加速稀疏LU分解。
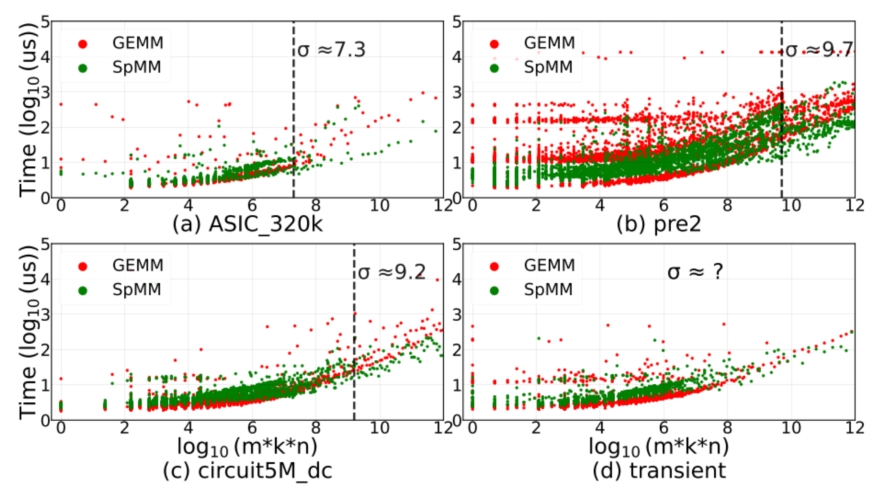
图2 不同阶电路矩阵上GEMM和SpMM的比较
在利用GPU加速计算内核方面,Piyush Sao等人开发了一种将小型密集BLAS操作聚合为一个较大操作的策略(如图3)。Xu Fu等人在其开发的求解器PanguLU中使用规则的2D分块策略,将其与决策树相结合后将部分内核放在GPU上实现相对加速。然而,结合矩阵特征来实现进一步的加速仍然具有挑战性。
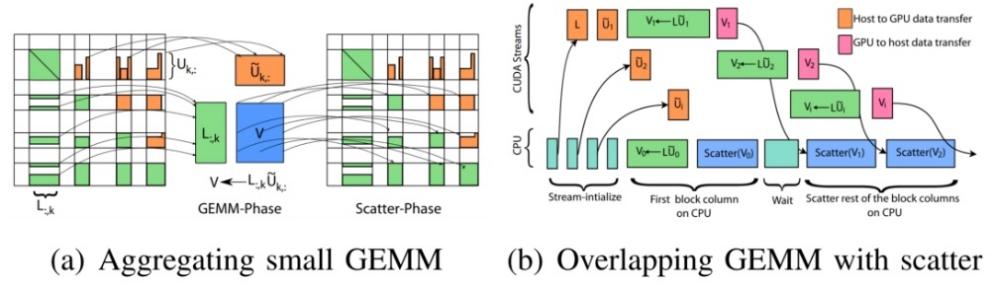
图3 GPU加速计算内核的方法
在利用GPU加速任务调度方面,Jianqi Zhao等人在GPU上提出SFLU利用无同步通信策略来充分利用GPU资源(如图4)。但当矩阵尺寸较小或列之间存在较强依赖性时,如何有效地将计算和调度策略结合起来,充分利用GPU的算力仍然是一个具有挑战性的问题。
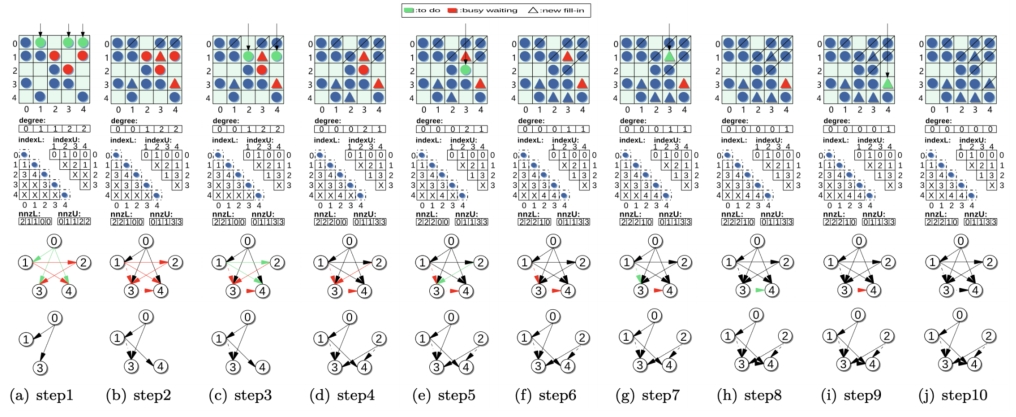
图4 SFLU算法示例
在利用分布式异构平台进行加速方面,Patrick R. Amestoy等人开发的求解器MUMPS利用异步通信和动态任务调度在Multifrontal方法中进行加速。Xu Fu等人在异构分布式平台上提出的PanguLU利用多种分块稀疏BLAS方法来提高GPU的效率、利用无同步通信策略降低总体延迟成本。
实验结果及分析:
表1展示了几种稀疏直接法解法器并在图5中对其数值分解的性能进行了对比。当矩阵规模、矩阵列之间的依赖关系、计算平台不同时,这些求解器的性能优劣关系都会产生变化。因此结合矩阵特征并充分利用计算平台来进一步优化LU分解是一个巨大的挑战。
表1 几种稀疏直接求解器总览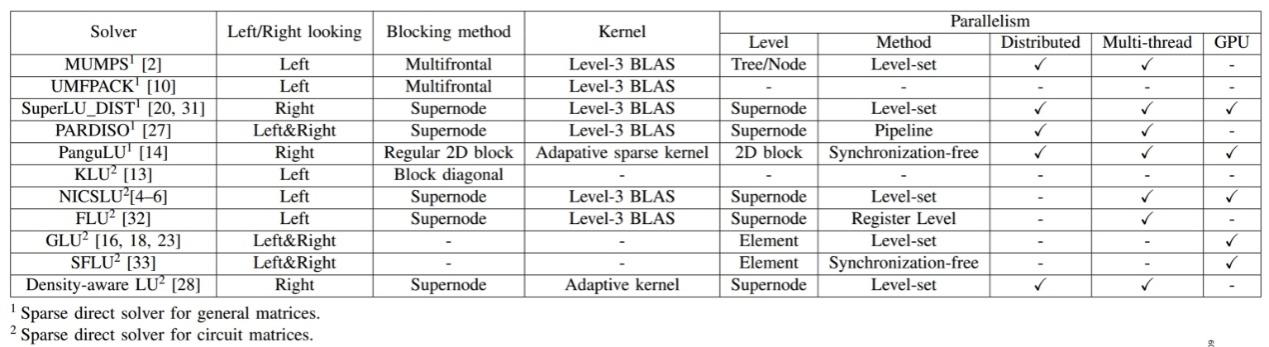
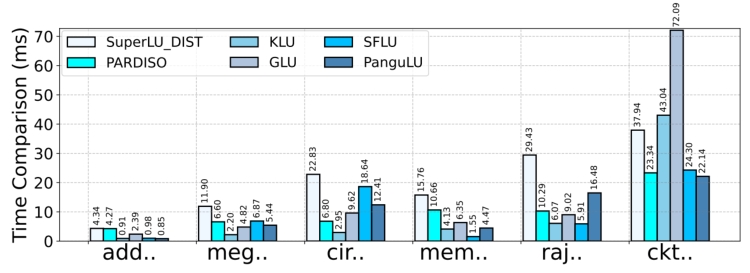
图5 不同解法器的数值分解时间对比
我们进一步对比了在32节点128GPU分布式集群上SuperLU_DIST和PanguLU(如图6)。虽然分布式方法具有并行加速的潜力,但由此产生的开销仍不可忽略,利用具有异构处理器的大规模超级计算机提高可扩展性以及降低具有不规则稀疏结构依赖性的进程之间的同步和通信成本仍然是一个巨大的挑战。
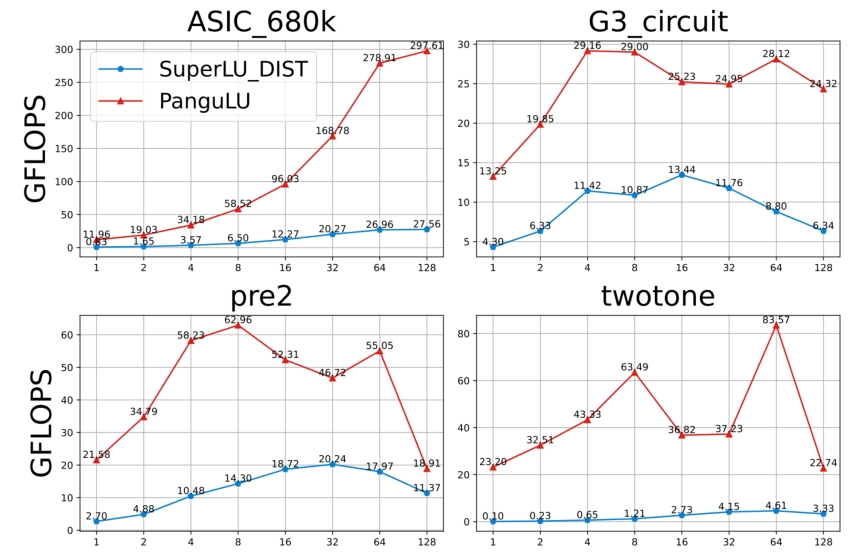
图6 SuperLU_DIST和PanguLU在128个A100GPU上的性能对比
通讯作者简介:
金洲,中国石油大学(北京)信息科学与工程学院./人工智能学院计算机系副教授,入选北京市科协青年人才托举工程、校青年拔尖人才。主要从事集成电路设计自动化(EDA)、面向科学计算的DSA软硬件协同设计等方面的研究工作。主持并参与国家自然科学基金青年项目、重点项目,科技部重点研发微纳电子专项、高性能计算专项青年科学家项目,国家重点实验室开放课题、企业横向课题等。在DAC、TCAD、TODAES、SC、PPoPP、IPDPS、TCAS-II、ASP-DAC等重要国际会议和期刊上发表40余篇高水平学术论文。
联系方式:jinzhou@cup.edu.cn