
CCDepth:一种可解释性增强的轻量化自监督深度估计网络
中文题目:CCDepth:一种可解释性增强的轻量化自监督深度估计网络
论文题目:CCDepth: A Lightweight Self-Supervised Depth Estimation Network with Enhanced Interpretability
录用期刊/会议:IEEE ITSC (CAA A)
作者列表:
1) 张 熙 中国石油大学(北京)人工智能学院 电子信息工程专业 本20
2) 薛亚茹 中国石油大学(北京)人工智能学院 电子信息工程系 教师
3) 贾邵程 香港大学 土木工程系 博21
4) 裴 新 清华大学 自动化系 教师
深度信息在自动驾驶领域发挥着至关重要的作用,准确的深度信息可以帮助自动驾驶系统正确地感知和理解周围环境。近年来,仅以单目图像序列为输入的自监督深度估计技术越来越受到人们的欢迎,拥有广阔的前景。
当前关于深度估计模型的研究主要集中在提高模型的预测精度方面,然而,过多的参数阻碍了模型在边缘设备上的通用部署。此外,目前常用的神经网络作为黑盒模型,其内部工作原理无法被数学解释,导致其性能难以被改进。为了缓解这些问题,本文提出了一种全新的、具有混合结构的自监督深度估计网络CCDepth,该网络由卷积神经网络(CNN)和白盒CRATE(Coding RAte reduction TransformEr)网络组成。这个全新的网络使用CNN和CRATE网络层分别提取图像中的局部和全局信息,从而提高网络学习能力、降低模型参数量。此外,通过CRATE网络的加入,本文提出的模型可以在捕捉全局特征的过程中被数学解释。
在KITTI数据集上的大量实验表明,本文提出的CCDepth网络可以达到与当前最先进方法相当的性能,同时模型尺寸已显著减少。此外,对CCDepth网络内部特征的一系列定量和定性分析进一步证实了本文所提方法的有效性。
近年来,伴随着人工智能的快速发展,人工智能的相关技术已经深入到人们的日常生活中。深度估计是自动驾驶系统的关键技术之一,发挥着让系统准确感知周围环境的任务。目前对于深度估计模型预测精度的研究已经较为完善,但是模型参数量轻量化和可解释性方面还存在局限和空白,限制着深度估计模型在自动驾驶领域的具体落地。
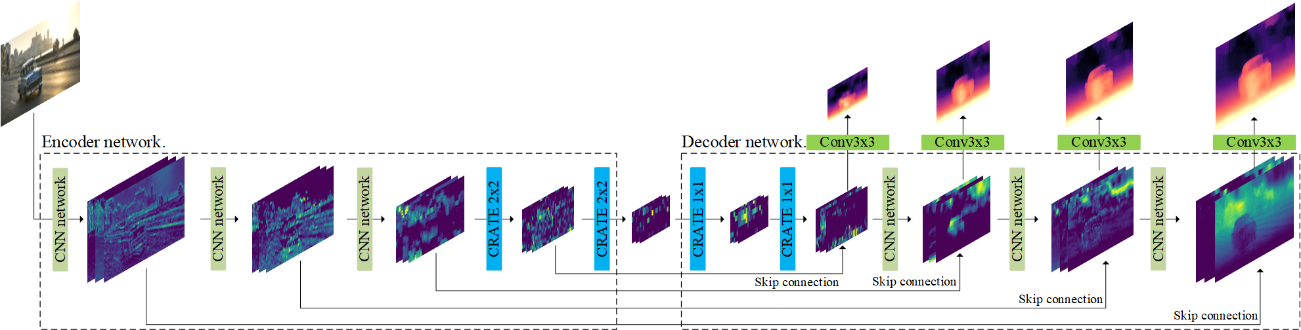
图1 CCDepth网络的编码器-解码器结构
图1为本文提出的CCDepth网络结构图,模型采用U-Net架构,编码器以RGB图像为输入,通过特征提取,在解码器网络得到图像深度的预测值。网络采用CNN-CRATE串联的结构,在图像分辨率大的部分,由CNN网络层提取图像的局部信息;在分辨率低的部分,利用CRATE网络层提取图像的全局信息。另外,网络会通过跳跃连接方式将U-Net编码器浅层提取到的细节特征直接传输至解码器的对应位置,以避免信息的丢失。
如图2所示,为本文采用的CNN网络层结构,该网络由两个最简单的残差块构成。卷积核边缘填充方式采用反射填充。
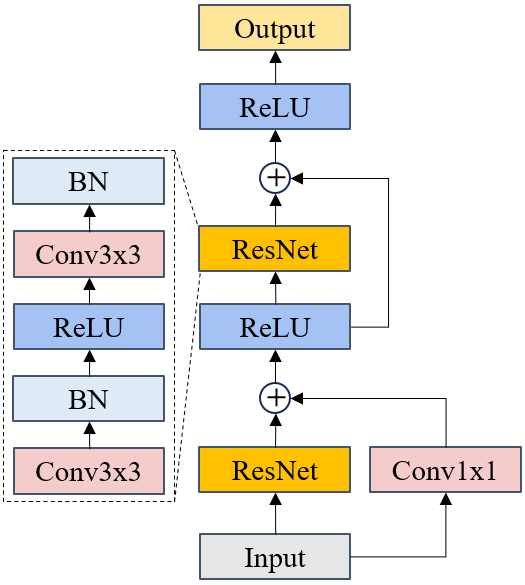
图2 CNN网络层结构
图3为本文CRATE网络层的工作流程,主要分为五步:第一步,将输入图像分割为若干图像块;第二步,破坏图像的二维结构,将图像块展开为一个序列;第三步,被映射为一个向量,并输入CRATE网络;第四步,向量集合(tokens)在CRATE网络中学习并被更新;第五步,向量集合被重新组合为图像格式,得到该层的输出特征图,即步骤2的逆过程。
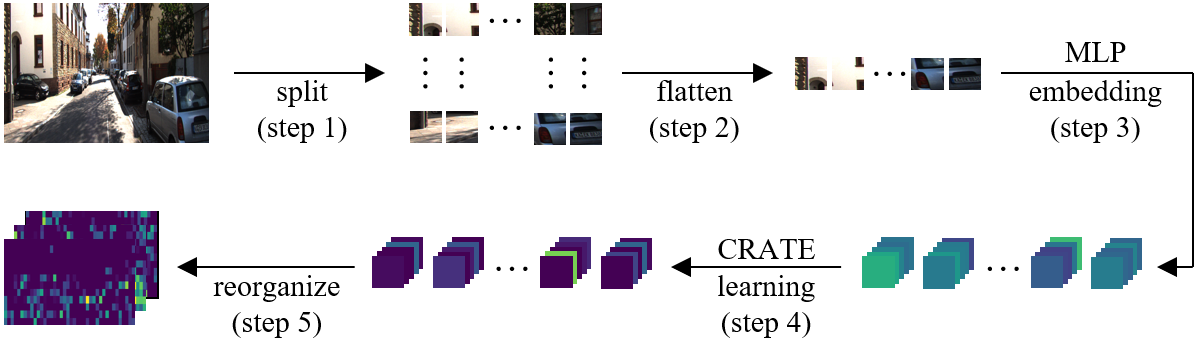
图3 CRATE网络层的工作流程
图4为CRATE网络的基础模块结构图,网络由多头子空间自注意力模块(Multi-Head Subspace Self-Attention block,MSSA)和一个迭代收缩阈值算法模块(Iterative Shrinkage-Thresholding Algorithms block,ISTA)构成,分别担任压缩(去噪)和稀疏化的操作。
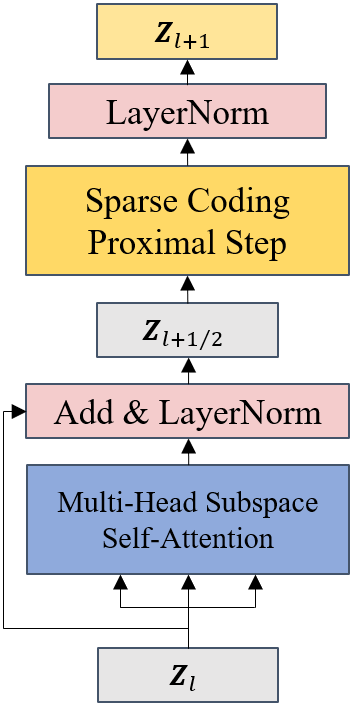
图4 CRATE网络的基本模块
如图5所示,CCDepth网络在自监督学习框架下进行训练,整个深度估计网络由深度网络和姿态网络两部分构成。深度网络接收视频序列中当前帧图像![]() ,经过编码器-解码器网络获得深度估计图
,经过编码器-解码器网络获得深度估计图![]() ,姿态网络接收当前帧图像
,姿态网络接收当前帧图像![]() 和相邻帧图像
和相邻帧图像![]() ,其中
,其中![]() ,并从中提取相机的位移信息。随后,根据
,并从中提取相机的位移信息。随后,根据![]() 与相机的位移信息
与相机的位移信息![]() ,进行图像重构,得到对
,进行图像重构,得到对![]() 的重构图像
的重构图像![]() ,并计算训练损失。
,并计算训练损失。
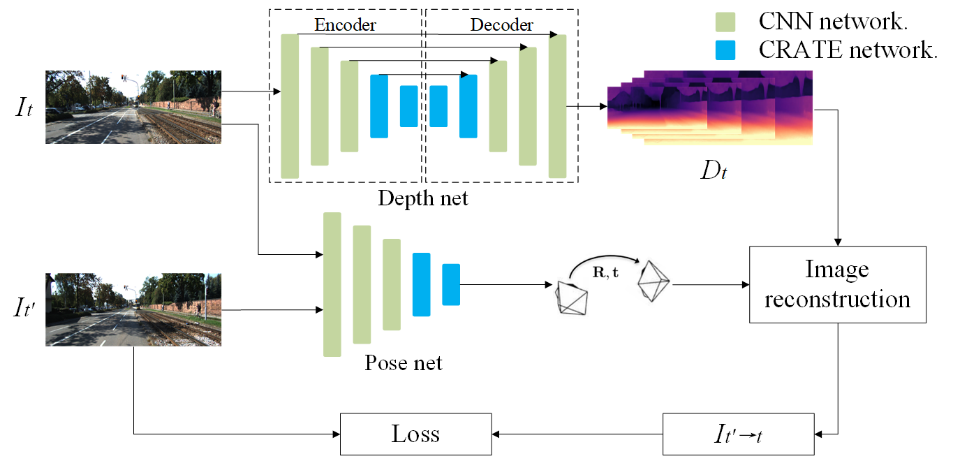
图5 CCDepth网络的自监督学习训练框架
表1所示,为本文提出的CCDepth模型与现有先进模型的定量对比结果。CCDepth在KITTI测试集的预测误差和精度上取得了更好的表现。同时,模型参数量仅有12.6M,相较于Monodepth2和FSLNet分别下降78.8%和23.6%。
表1 自监督深度估计在KITTI数据集上的定量结果
模型 |
误差,越小越好 |
精度,越大越好 |
模型 参数量 |
|||||
|
Abs Rel |
Sq Rel |
RMSE |
RMSE log |
|
|
|
|
Zhou et al. |
0.208 |
1.768 |
6.856 |
0.283 |
0.678 |
0.885 |
0.957 |
126.0M |
Geonet |
0.153 |
1.328 |
5.737 |
0.232 |
0.802 |
0.934 |
0.972 |
229.3M |
Casser et al. |
0.141 |
1.138 |
5.521 |
0.219 |
0.820 |
0.942 |
0.976 |
67.0M |
Monodepth2 |
0.115 |
0.903 |
4.863 |
0.193 |
0.877 |
0.959 |
0.981 |
59.4M |
FSLNet-L |
0.128 |
0.897 |
4.905 |
0.200 |
0.852 |
0.953 |
0.980 |
16.5M |
CNN-ViT |
0.119 |
0.857 |
4.789 |
0.194 |
0.867 |
0.958 |
0.981 |
17.4M |
CCDepth (Our) |
0.115 |
0.830 |
4.737 |
0.190 |
0.874 |
0.959 |
0.982 |
12.6M |
图6所示,为自监督深度估计任务上的定性对比结果。由标记框中的内容可以定性分析得出,本文提出的模型在图像深度预测上,尤其是对于细小障碍物和天空距离的识别方面,优于其他的模型。这是由于CCDepth采用了基于CNN和CRATE的混合网络结构,因此可以更加有效地提取图像局部和全局特征。

图6 自监督深度估计的定性结果
表2与表3所示,为本文的消融实验结果。在本部分,通过实验证明了网络多尺度预测和卷积核反射填充方式的必要性。
表2 不同预测尺度下的消融研究
Scales |
误差,越小越好 |
精度,越大越好 |
|||||
|
Abs Rel |
Sq Rel |
RMSE |
RMSE log |
|
|
|
1 |
0.119 |
0.860 |
4.750 |
0.194 |
0.870 |
0.958 |
0.981 |
2 |
0.121 |
0.861 |
4.760 |
0.195 |
0.866 |
0.957 |
0.981 |
3 |
0.118 |
0.841 |
4.738 |
0.194 |
0.870 |
0.958 |
0.981 |
4 |
0.115 |
0.830 |
4.737 |
0.190 |
0.874 |
0.959 |
0.982 |
表3 不同填充方式下的消融研究
Padding mode |
误差,越小越好 |
精度,越大越好 |
|||||
Abs Rel |
Sq Rel |
RMSE |
RMSE log |
|
|
|
|
zeros |
0.118 |
0.858 |
4.755 |
0.193 |
0.870 |
0.958 |
0.981 |
reflect |
0.115 |
0.830 |
4.737 |
0.190 |
0.874 |
0.959 |
0.982 |
图7所示,为CRATE网络内部各模块输出的非零项占比对比,可以分析得到,CRATE网络在深度估计任务中有效地为所有数据实现压缩(去噪)和稀疏化,将特征向低秩转化,以更好地暴露全局信息。
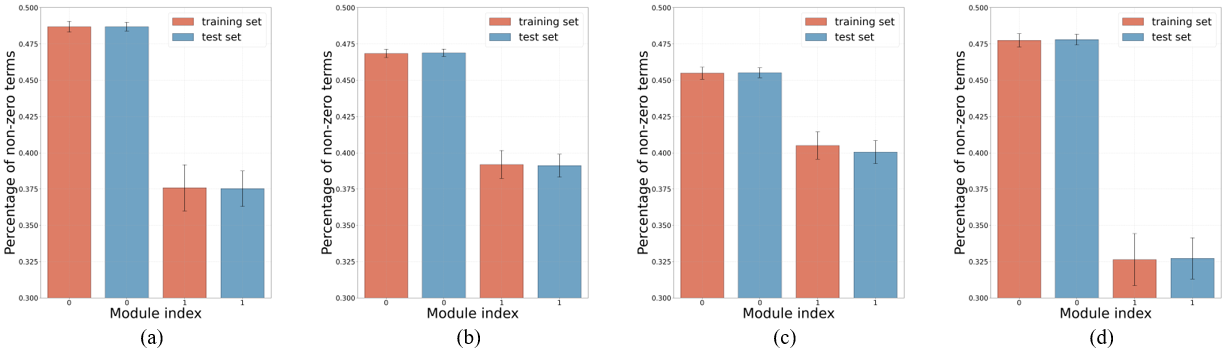
图7 CRATE网络层内各模块输出的非零项占比对比,(a)CCDepth中第一个CRATE网络层的结果,(b)CCDepth中第二个CRATE网络层的结果,(c)CCDepth中第三个CRATE网络层的结果,(d)CCDepth中第四个CRATE网络层的结果。
图8所示,为网络中CNN和CRATE网络层的特征图。可以明显地看出,CNN网络(layer 3和layer 8)更强调提取图像的具体形状和边缘细节。相比之下,CRATE网络则侧重于描述图像的环境等全局结构。这与CCDepth最初设计中通过CNN-CRATE结构分别提取图像细节和全局信息的理念相吻合,进一步肯定了CCDepth网络结构设计的有效性。

图8 CNN和CRATE特征图的可视化结果
本文提出了一种全新的深度估计网络CCDepth,该网络通过CNN和CRATE分别提取图像的细节和全局信息,以实现在自监督深度估计任务中高效地提取有用特征。相比较于现有的先进模型,CCDepth拥有更高的准确度,显著降低了模型参数量,并提升了网络可解释性。
薛亚茹,副教授,博士生导师/硕士生导师。主要从事信号处理、图像处理、人工智能、地球物理反演等方面研究。