
APF-DQN:基于改进的深度强化学习的建筑火灾自适应目标路径规划算法
中文题目:APF-DQN:基于改进的深度强化学习的建筑火灾自适应目标路径规划算法
论文题目:APF-DQN: Adaptive Objective Pathfinding via Improved Deep Reinforcement Learning among Building Fire Hazard
录用期刊/会议:ICANN 2024(CCF-C)
原文DOI:
原文链接:
录用/见刊时间:2024.06.06
作者列表:
1) 章可 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
2) 朱丹丹 中国石油大学(北京)信息科学与工程学院/人工智能学院 智能中心教师
3) 许秋晗 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
4) 周昊 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
5) 彭雪梅 香港科技大学(广州)信息枢纽 数据科学与分析学域 博23
摘要:
疏散路径规划引导是确保火灾中人员生命安全的关键任务。目前的疏散规划方法主要是计算确定性目标地点的最优路径。然而火灾疏散引导场景面临着建筑物内部存在多出口、火灾动态蔓延导致疏散路径不稳定等关键挑战。为了解决这些问题,本文提出了一种疏散智能体,采用一种人工势场深度强化学习(APF-DQN)算法来计算疏散路线,使疏散智能体能够选择合适的出口并规划动态疏散路径。该算法在深度强化学习架构中引入人工势场概念,引导智能体自适应地选择目标出口,避免火灾蔓延造成的伤害;同时深度强化学习算法保证疏散智能体规划动态路径。本文在仿真实验中测试了APF-DQN并与几种传统路径规划方法进行了比较。与传统的A*,APF,DQN方法相比,我们的APF- DQN算法规划的疏散路径所需要的时间成本降低了18.7%,距离火源点的安全距离增加了20.1%。本文代码可以从 https://github.com/ColaZhang22/APFDQN-Indoor-fire-hazard-path-planning下载。
背景与动机:
面对火灾隐患时,路径规划是建筑消防疏散系统的重要组成部分。然而随着建筑物结构越来越复杂和建筑面积逐渐庞大,建立合理的疏散路径可以有效减少火灾造成的威胁。此外,由于建筑物内有多出口和动态火灾隐患,传统方法中固定疏散路径不足以应对建筑物内的多出口问题。因此,建立一条动态、可靠和安全的路线成为火灾疏散路径规划中一个关键问题。
由于室内建筑结构规模庞大,传统路径规划方法耗时长,因此在有限的疏散时间下是不可接受的。尽管已经有许多先前的研究尝试解决这个问题,比如IACO和 Hierarchical A*。但目前的方法仍然存在两个挑战,如图 1 所示。第一个问题是动态火灾蔓延变化带来的负面影响。随着火灾危险性的增加,环境中的某些路径无法通过,而某些房间则成为疏散通道的障碍。第二个问题是大型建筑中存在多个出口。因此根据火灾危险性选择合适的出口是另一个重要问题。

图1 单目标出口疏散路径规划与自适应目标疏散路径规划
为了解决上述问题,本研究构建了一种称为人工势场深度强化学习 (APF-DQN) 的方法来训练疏散智能体规划疏散路径,引导待疏散人员在室内建筑物中以更短的疏散时间和更安全的距离进行避险疏散。本文在两种建筑场景中检验了APF-DQN,并与三种典型的寻路算法进行了比较,基于APF-DQN的智能体能够考虑火势蔓延来规划动态疏散路径,并选择合理的出口作为目标,以避免火灾造成的损害。
设计与实现:
APF-DQN主要包含两个模块:基于数据的强化学习模块(RL) 和基于知识的人工势场模块(DQN),如图2所示。与经典的路径规划算法相比,基于 RL 的路径规划能够提供实时动态疏散路线,从而避免计算开销。同时,人工势场模块引导智能体自适应地选择合适的目标出口作为目标,并根据建筑物内火灾危险的变化调整目标出口。
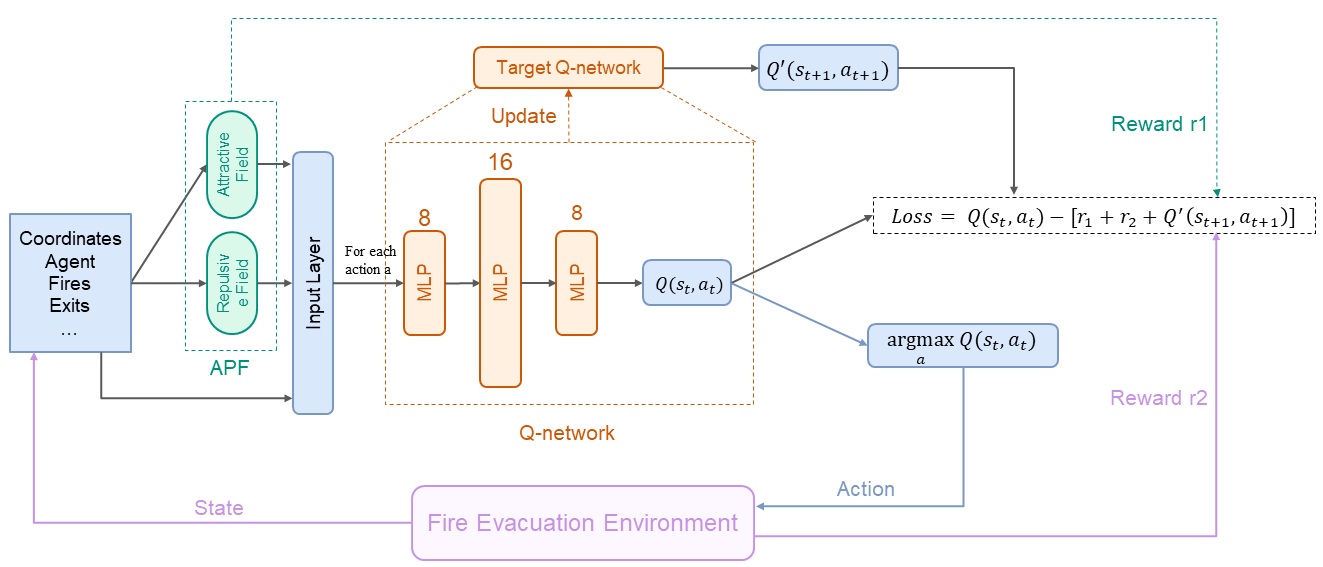
图2 APF-DQN 算法
强化学习模块:为了减少计算最优路径的时间消耗实现实时规划疏散路径,采用DQN作为火灾疏散场景的路径规划框架。本问将火灾疏散引导系统视为DQN中的疏散智能体,与火灾疏散环境进行交互。疏散引导智能体根据自身状态和火灾危险情况规划下一个疏散坐标并调整目标出口。
在火灾疏散场景中,疏散引导智能体从环境中感知周围属性,如当前坐标和火灾发生位置,作为智能体的状态。然后,火灾疏散引导智能体根据感知到的信息选择下一个逃生动作。最后,火灾疏散环境将奖励反馈给火灾疏散引导智能体。火灾疏散引导智能体的目标是积累并最大化这些奖励:
![]()
经典强化学习算法Q-learning引入了价值函数来估计疏散代理当前配对动作状态的值:
![]()
更高的Q值意味着当前疏散位置更安全,并且疏散引导智能体倾向于选择该逃离位置作为下一次行为选择中的最佳行为。在训练过程中,为了在探索和开发之间保持平衡,疏散代理采用epsilon-greedy策略来选择下一步行动:
![]()
在火灾疏散环境中,基于强化学习的算法可能实时进行疏散路径规划,然而火灾的发展扰乱强化学习理论中马尔可夫过程过程的假设,从而导致疏散智能体的决策产生错误。在某些情况下,疏散引导智能体会判断并选择距离安全出口最近的下一步行动,但这种选择可能会因火灾的副产物和火情的蔓延而出错。为了消除火灾发展对DQN在火灾疏散中的影响,本研究将人工势场 (APF) 引入了DQN。
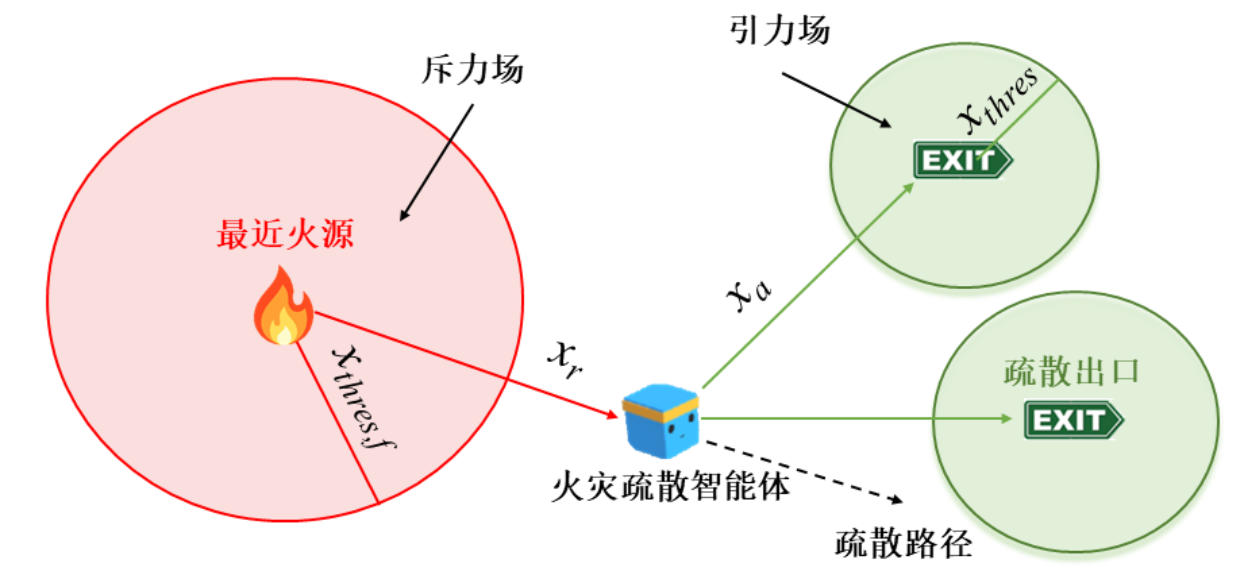
图3 人工势场模块
人工势场模块:APF模块生成两个力场,包括吸引力场和排斥力场。在火灾疏散场景中,火灾和障碍物产生排斥力场,引导疏散引导智能体远离火灾隐患。同时建筑物中的多个出口分别产生吸引力场,引导疏散引导智能体朝向目标出口。因此,APF能够准确反映火灾的变化信息,并消除DQN算法中因为火灾发展和不同场景导致的建筑环境不稳定性。
APF中的吸引力场表示多出口吸引力的强度,公式表示为:
![]()
由上式可知,随着距离的缩短,引力场变得更大,疏散引导智能体将被引导到建筑物中所有出口中最近的出口。然而,当火灾危险发生在最近的出口附近时,最近的出口并不是理想的目标。因此,APF 中的排斥力场也用于指导疏散引导智能体的路径规划。与引力场相比,排斥力场也表示障碍物或火点排斥力的强度。排斥力场公式表示如下:
![]()
排斥力场公式说明,当疏散引导智能体离火灾点越近,智能体受到的排斥力就越大。因此,疏散引导智能体倾向于与火灾隐患保持安全距离,同时被引力场引导至合适的出口。
此外,在传统的强化学习中,DQN存在稀疏奖励问题阻碍了疏散引导智能体从经验样本中有效地学习。因此,APF的变化被视为两种状态之间的奖励函数,以提高训练质量,本文使用:
![]()
作为APF-DQN的奖励函数。疏散引导智能体每一次采取行动,都可以获得奖励来评估动状态的好坏;当疏散引导智能体到达出口时,它会获得一个固定的奖励。
实验结果及分析:
本文利用两种环境来测试我们提出的方法来验证算法的可扩展性,一种环境包含两个出口和一个火灾发生点,另一种环境考虑三个出口和一个火灾发生点。实验结果如图4所示,每个点表示空间内对应状态的Q值。颜色越深即Q值越高,意味着疏散引导智能体倾向于采取 Q 值较高的行动。在训练开始时,每个状态的 Q 值是不规则的,因此代理无法正确选择行动。在训练过程中,出口附近的状态具有较高的 Q 值,而环境中靠近火灾隐患的状态具有较低的值。因此,疏散代理能够在多个出口中自适应地选择合适的出口,同时远离远处的隐患。
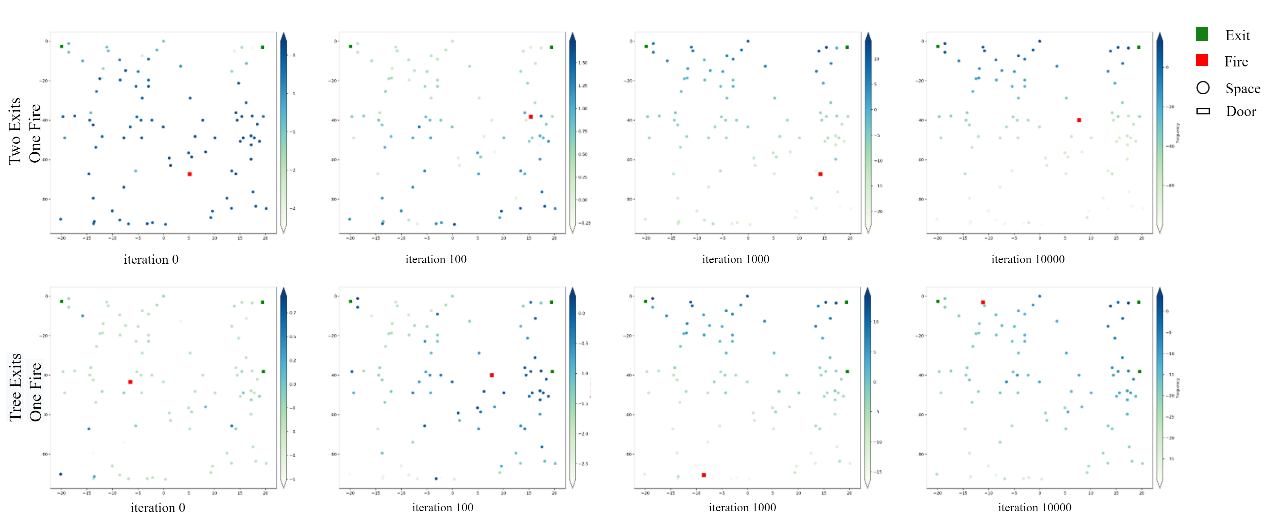
图4 状态价值函数变化
至于疏散路径,本文的疏散引导智能体初始被设置到建筑中的随机位置,火灾隐患也发生在随机位置。如图5所示,APF-DQN算法能够在各种情况下找到逃离火灾的最佳疏散路径,并选择远离火灾的路线以避免火灾隐患造成的损害。同时基于APF-DQN 规划的疏散路径表明,当同时面临多个出口时,疏散引导智能体愿意选择远离火灾点的出口。在5的 (c)(d) 中,规划的疏散路线显示,尽管一些出口靠近疏散引导智能体的当前状态,但疏散引导智能体更倾向于规划一条相对较远但更安全的路径以确保逃离火灾。
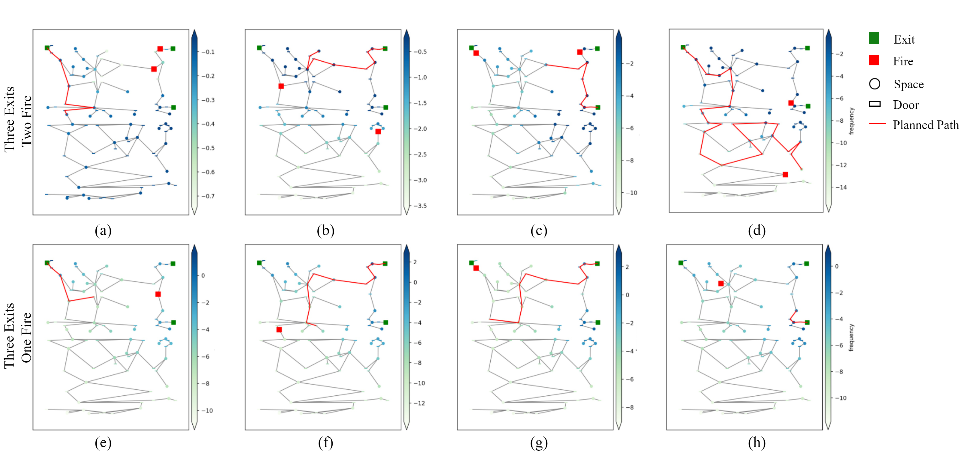
图5 基于APF-DQN的疏散路径
然后,本文从两个指标评估提出的 APF-DQN算法,即疏散时间和疏散引导智能体到火灾发生点的最短距离。疏散时间表示疏散引导智能体从初始坐标到达适当出口所花费的时间步长。在火灾隐患疏散中,较短的疏散时间意味着代理能够有效地到达出口,从而避免火灾隐患造成的损害。最短火源距离表示从疏散引导智能体到火灾发生点的距离,较长的最短火源距离表示智能体距离火灾发生地较远,能够更安全的到达出口。
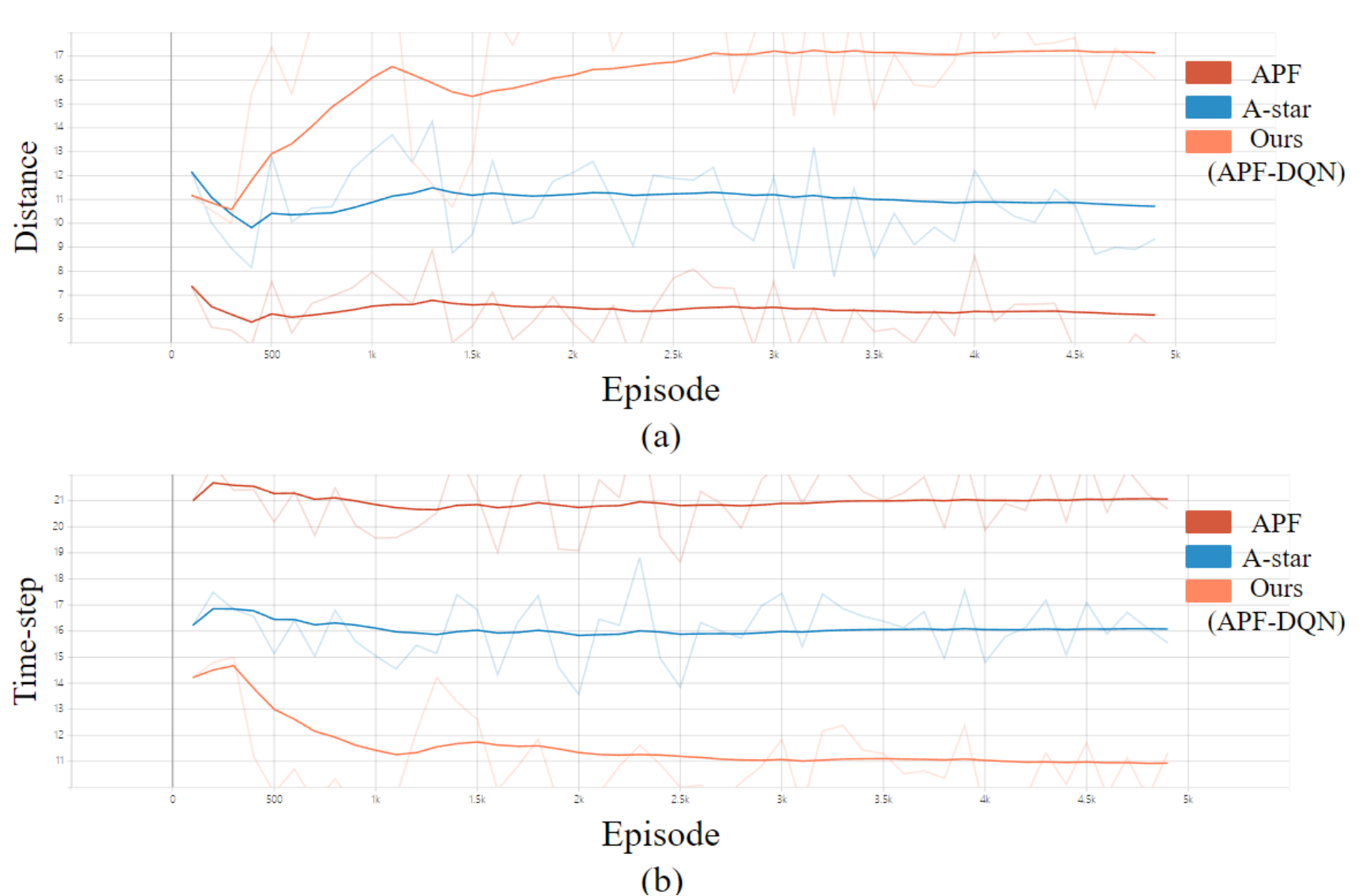
图6 APF-DQN对比实验
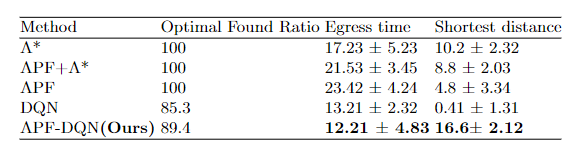
本文对两种经典路径规划方法 A-star 和 APF 进行了对比实验,如图6所示。在我们的实验中,对于每个代理,初始位置的差异会显着影响疏散时间步长和距离火灾的最近距离。因此,本文实验采取100次仿真,并计算平均距离和时间步长以消除误差。同时与传统强化学习算法DQN对比,如表1所示,APF-DQN具有最短的疏散时间和距离火灾危险最大的距离。
表 1 对比实验结果
结论:
本文重点研究了火灾建筑环境中的疏散路径规划引导问题。建筑物中存在多个出口和动态火灾隐患,因此疏散引导智能体需要选择合适的目标出口来逃生并避免火灾隐患造成的损害。传统方法需要针对每种情况重新计算疏散路线,并且只为固定出口提供静态路径。然而,火灾发生的地点是随机的,同时多个出口会导致疏散路线动态变化。
为了解决这些问题,本文提出了一种APF-DQN算法来规划到出口的疏散路径。APF-DQN 将人工势场方法融合到深度强化学习中,以计算最短疏散路径并同时保持与火灾点的安全距离。此外,APF-DQN能够在环境中的多个出口中自适应地选择合适的出口,并根据吸引力场和排斥力场的变化构造奖励函数,从而引导疏散引导智能体感知火灾的发展,选择合适的出口并规划疏散路线。
作者简介:
朱丹丹:博士,智能中心副教授,硕士生导师。目前主要研究方向是强化学习和数据挖掘。联系方式:zhu.dd@cup.edu.cn