
一种基于迁移强化学习的目标感知井眼轨迹控制方法
中文题目:一种基于迁移强化学习的目标感知井眼轨迹控制方法
论文题目:A Target-Aware Well Path Control Method Based on Transfer Reinforcement Learning
录用期刊/会议:SPE Journal (JCR Q1)
原文DOI:https://doi.org/10.2118/218409-PA
原文链接:https://doi.org/10.2118/218409-PA
录用/见刊时间:2024/01/15
作者列表:
1) 朱丹丹 中国石油大学(北京)信息科学与工程学院/人工智能学院 智能中心 副教授
2) 许秋晗 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术 研21
3) 王 菲 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术 研19
4) 陈 冬 中国石油大学(北京)石油工程学院 油气井工程系 副教授
5) 叶智慧 中国石油大学(北京)安全与海洋工程学院 海洋油气工程系 副教授
6) 周 昊 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术 研21
7) 章 可 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术 研21
文章简介:
井眼轨迹控制技术是指遵循预先设计好的井眼轨道,控制钻头的实际钻进方向,使得实际钻进轨迹尽可能地与预设井眼轨道贴合。在石油工程中,井眼轨迹控制技术对于钻井质量、采收效率及资金投入等方面具有至关重要的意义。目前,全球油气勘探的趋势正在朝着超深水、超深层、低渗透、非常规等方向发展,井眼轨迹控制技术迎来了巨大的挑战。随着油气行业对采收率及钻井成本要求的不断提高,传统井眼轨迹控制技术已然无法满足复杂油气藏在轨迹精度和钻进效率等方面的需求,井眼轨迹控制技术亟待突破。但是,随着油气藏复杂度的不断提高,井眼轨迹控制技术正面临着复杂油气藏高温、高压及高陡等特点所带来的严峻挑战。同时,钻进过程中的非线性、强干扰、高耦合、滞后性及时变性也为井眼轨迹控制技术带来了很多棘手的问题。而大多数传统井眼轨迹控制方法通常是基于空间几何关系,结合某些线性化的约束和假设进行构建,无法对钻进过程进行准确的描述,与实际井眼轨迹控制工作有一定差距,智能化程度低。而现有的智能井眼轨迹控制技术也尚未成熟,仅在某一或特定环境下表现优异,算法的抗干扰性和自适应性还需要进一步研究。
基于以上背景,本文聚焦于井眼轨迹跟踪控制,针对实际钻进过程中存在的强干扰、非线性等问题,提出了一种基于强化学习和迁移学习的井眼轨迹自适应跟踪控制方法。该方法采用基于优先级经验回放机制的深度确定策略梯度(Deep Deterministic Policy Gradient,DDPG)模型,并通过迁移学习加速模型学习,提高系统的泛化能力。该方法能够在三维模拟钻进环境中精准跟踪预设轨道,并在不确定干扰约束下表现出优秀的抗干扰性,准确引导井眼轨迹到达靶区。同时,该方法具备良好的自适应能力,当预设井眼轨道与实际随钻数据不符时,能够对轨迹控制决策进行优化,提高目标油层的钻遇率。
在实际施工过程中,由于地质因素、钻井工具以及井眼扩大等原因导致井眼不可避免地发生偏斜,井眼轨迹控制任务通常具有挑战性。传统的井眼轨迹控制方法大多侧重于精细的物理模型构建,这些方法通常建立在一定的约束或假设的基础上,而它们准确捕捉实际钻井过程的能力有限、智能水平低、抗干扰性能差、自适应能力弱。为了解决这些问题,本文提出了一种结合强化学习和迁移学习的目标感知井眼轨迹控制方法,从而构建了具有较强抗干扰能力的目标感知井眼轨迹自适应控制系统。本文提出的基于强化学习和迁移学习的井眼轨迹目标感知控制方法,能够在不同地质环境下准确跟踪预定轨迹,高精度到达靶区,在目标轨迹与油藏实际分布不匹配的情况下,利用MWD进行合理的轨迹优化决策。该方法具有良好的抗干扰能力和自适应能力。
井眼轨迹控制在钻完井工程中起着至关重要的作用。实际钻井过程复杂,具有变异性和不确定性,因此井眼轨迹控制存在一定难度。在常规井眼轨迹控制方法中,研究的重点主要是建立经验模型和数值模型。然而,在实际钻井过程中,由于具有较强的非线性、复杂性、时变性和不确定性等特点,始终存在跟踪误差和粘滑振荡等问题。
在井眼轨迹控制的背景下,实现最优控制通常需要专家知识。利用人工智能的鲁棒性,智能井眼轨迹控制算法可以实现更强的自适应井眼轨迹控制。在地层条件复杂的实际油田中,自适应方法最初可能需要专家知识的指导。通过不断的学习,系统可以逐渐掌握知识,并将其应用到类似的地质环境中。本文提出的方法有望帮助钻井人员完成更多的任务,从而降低人工成本。
井眼轨迹控制本质上是BHA的控制。为了实现井眼轨迹的实时高效控制,本文设计了一种基于强化学习和迁移学习的目标感知井眼轨迹控制系统。该系统在完成钻井作业的同时,能够保持较强的抗干扰性和适应性。本文定义了钻井环境任务中的基本要素,包括状态空间、动作和奖励函数。其整体系统结构如图1所示。
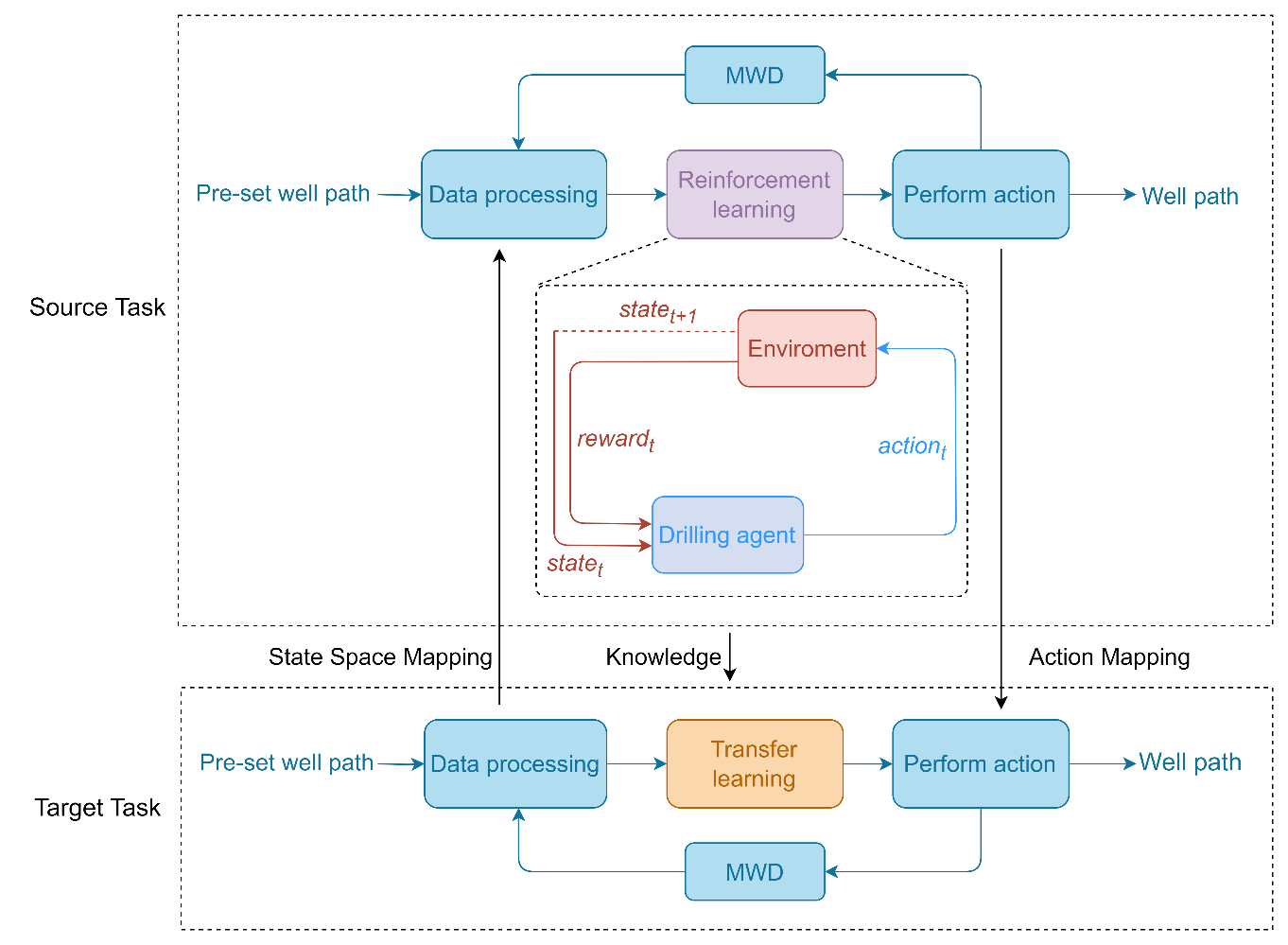
图1 自适应钻井系统框架
如图1所示,定向井轨道经过设计而预先确定,随后针对相关数据进行计算,以获得预先设置的井眼轨迹数据。本文以方位角和倾角作为描述井眼轨迹的物理量。在迁移学习部分,模型将目标任务的状态空间映射到源任务。当前井眼轨迹倾角数据和预先设定的井眼轨迹数据作为DDPG网络模型的输入。在强化学习部分,钻井智能体在与环境的交互中对策略进行优化,以获得最大的奖励。随后,模型将输出源任务操作映射到目标任务操作。通过这种方式,可以实现井眼轨迹的实时跟踪和控制。整个系统通过随钻测量实现信号反馈,并实时调整DDPG神经网络模型参数,最终生成井眼轨迹。通过重用源任务生成的知识来完成目标任务。当测井数据与实际随钻数据不符时,系统可以通过迁移学习重新利用过去的知识来规划合适的井眼轨迹。在此过程中,钻井策略自适应调整以达到目标储层,确保有效跟踪预设的井眼轨迹。
1. 井眼轨迹跟踪控制问题形式化
为了通过强化学习解决井道控制问题,本文首先将问题形式化,将其转化为三个部分:定义智能体的状态空间、动作空间和奖励函数。
状态空间如下所示:
![]()
本文将aω与aγ作为DDPG模型的井眼轨迹控制动作。考虑到真实BHA的工具限制,定义ω方向的控制动作aω的取值范围为[0,π/2],定义γ方向的控制动作的aγ取值范围为[0,2π]。
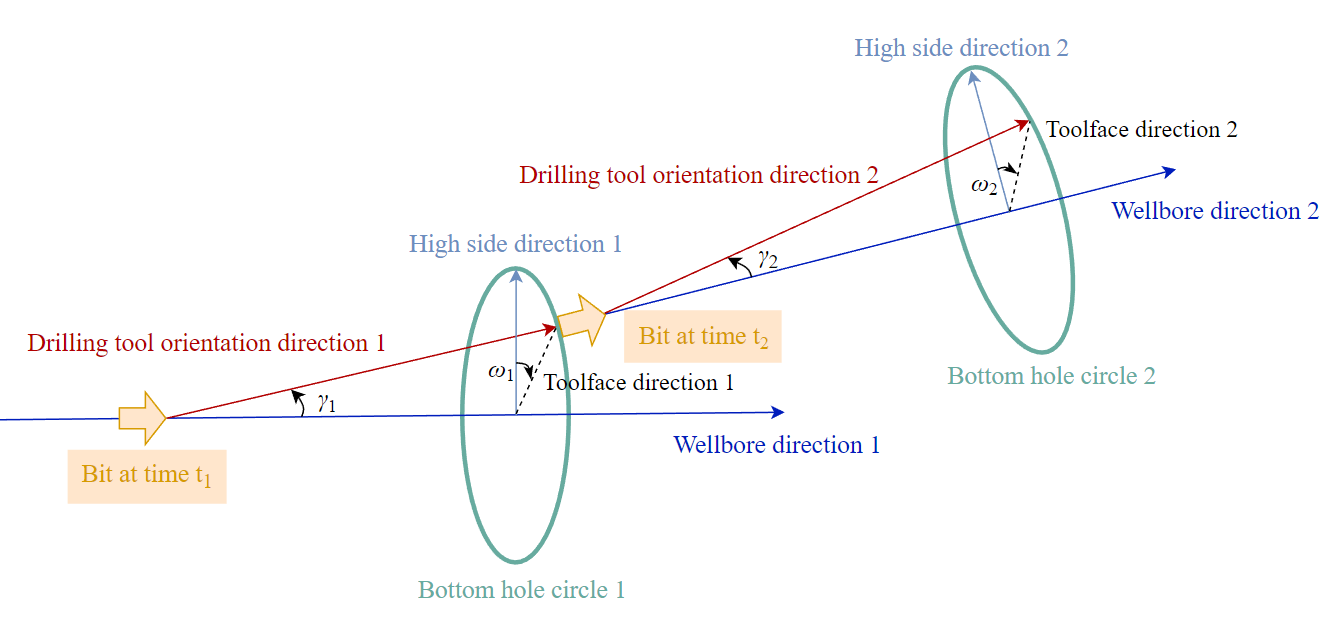
图2 井眼轨迹控制过程
为了构建具备自适应能力的井眼轨迹跟踪控制模型,新奖励函数的设计如下:
![]()
其中,R1为单步奖励,R2为回合奖励。R1的计算由两部分组成:
![]()
其中,r1代表对预设轨迹的跟踪奖励,r2代表在目标油层中行进的奖励,λ作为调节两奖励权重的系数。r1与r2奖励的计算公式如下所示:
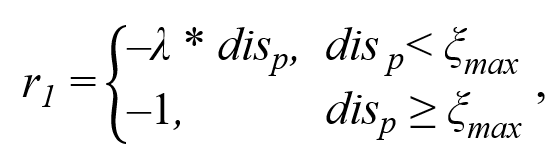
![]()
奖励R2是回合奖励,其设置的目的是为了激励智能体到达靶区,其计算公式如下:
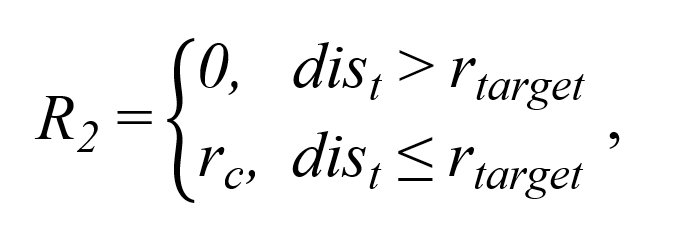
2. 基于DDPG的井眼轨迹控制模型
本文所建立的DDPG模型的输入向量维度为5,为当前井眼轨迹井斜数据及预设井眼轨道数据。模型的输出为作用于BHA的方位角和倾斜角。建立的DDPG模型的网络结构如图所示。
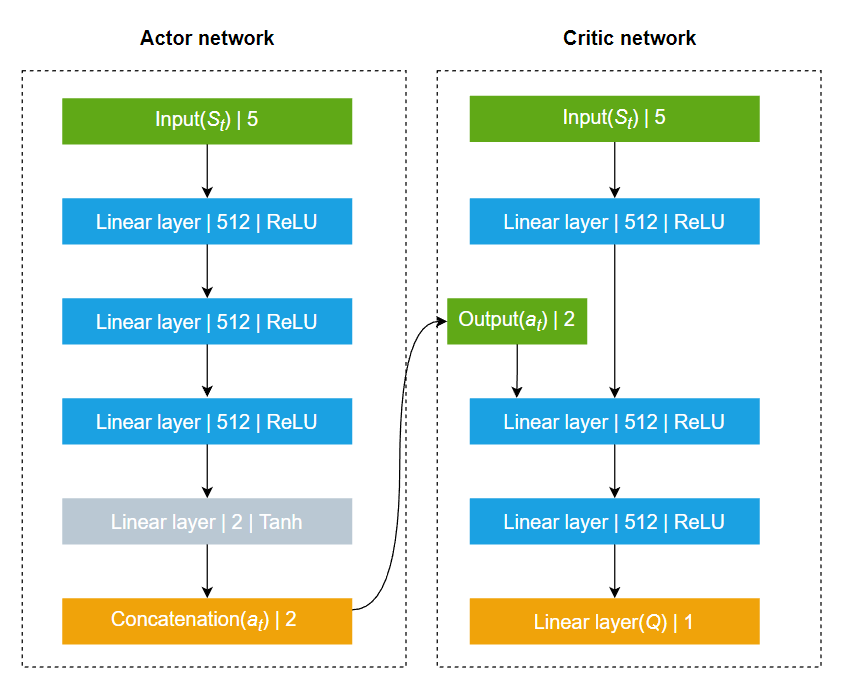
图3 DDPG网络模型
考虑到井眼轨迹跟踪控制系统的复杂性,为了进一步提高DDPG模型的训练效率与稳定性,本文对DDPG模型进行了改进,摒弃了传统经验回放的随机采样机制,采用了一种基于优先级的经验回放机制。
在本文所设计的基于优先级的经验回放机制中,经验的抽样并非随机从经验池中进行抽取,经验抽样的概率分布如下所示:
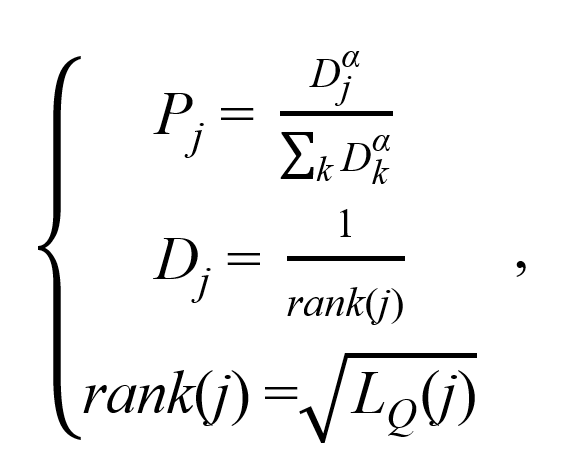
3. 控制策略迁移学习
基于迁移学习的DDPG模型需要解决的是如何将源领域的策略网络和价值网络迁移到目标领域的策略网络和价值网络。
对于策略网络,其定义为![]() ,即对于当前状态输出一个确定性动作。从本质而言,策略网络是一个非线性策略逼近器,用于对策略模型π(a|s)进行逼近。因此,对策略网络的迁移实质上是对源领域的状态-动作关系进行迁移。策略网络具体的迁移过程如图4所示。
,即对于当前状态输出一个确定性动作。从本质而言,策略网络是一个非线性策略逼近器,用于对策略模型π(a|s)进行逼近。因此,对策略网络的迁移实质上是对源领域的状态-动作关系进行迁移。策略网络具体的迁移过程如图4所示。
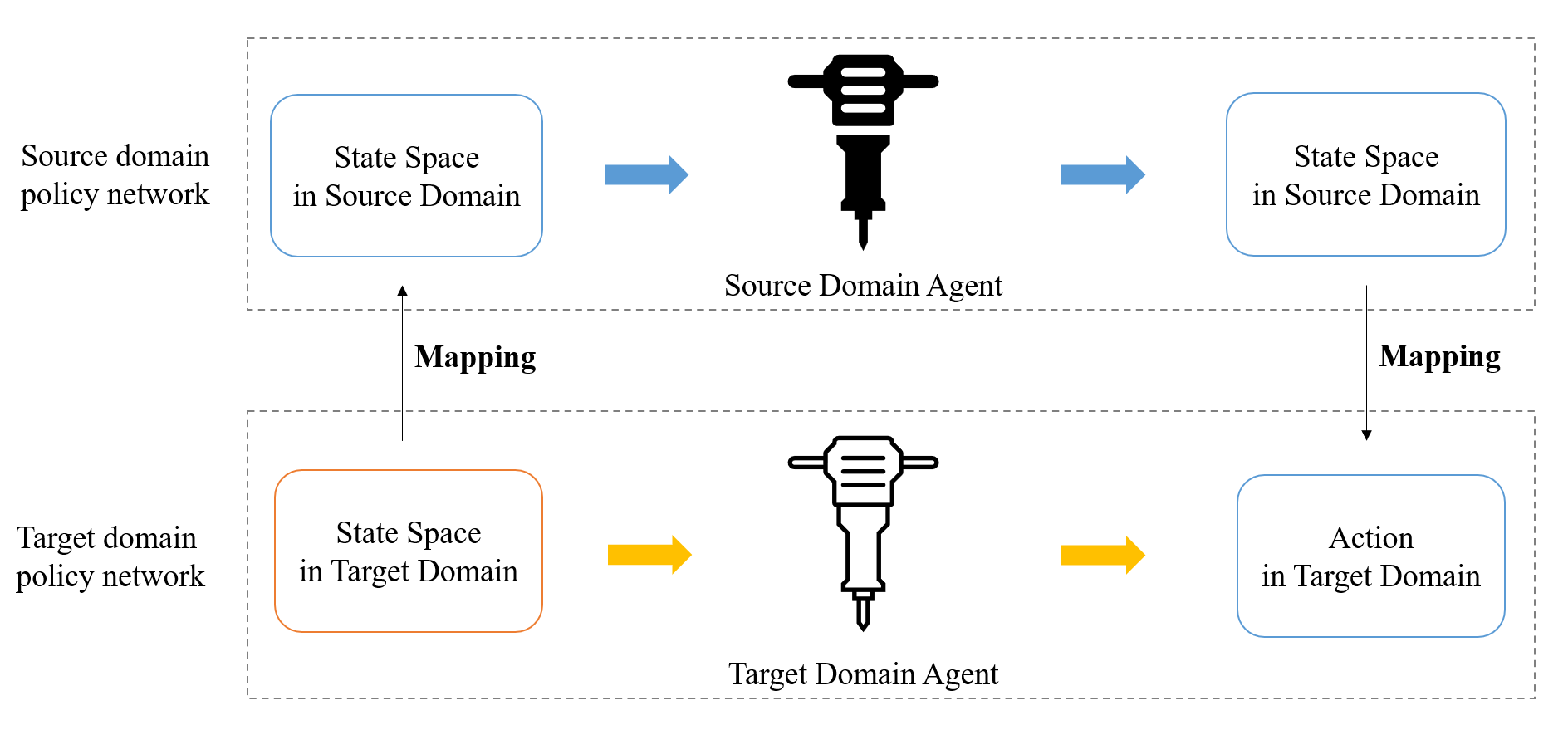
图4 策略网络迁移过程
为了验证基于强化学习和迁移学习的井眼轨迹跟踪控制算法的有效性,测试算法的抗干扰能力与自适应能力,本文设计了井眼轨迹跟踪实验、抗干扰实验及自适应实验。
1. 井眼轨迹跟踪实验
图5为基于随机经验重放的DDPG模型收敛后的井眼轨迹对比图。红色轨迹代表预先设定的井眼轨迹,蓝色轨迹代表实际井眼轨迹。图6为井眼轨迹水平投影对比图,其中横轴为东西方向位移,纵轴为南北方向位移。图7为井眼轨迹垂直投影对比图,其中横轴为视平移,纵轴为垂深。
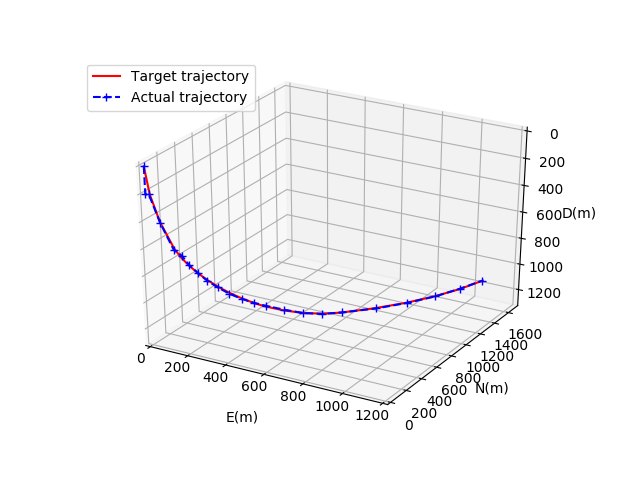
图5 基于RER的DDPG模型井眼轨迹比较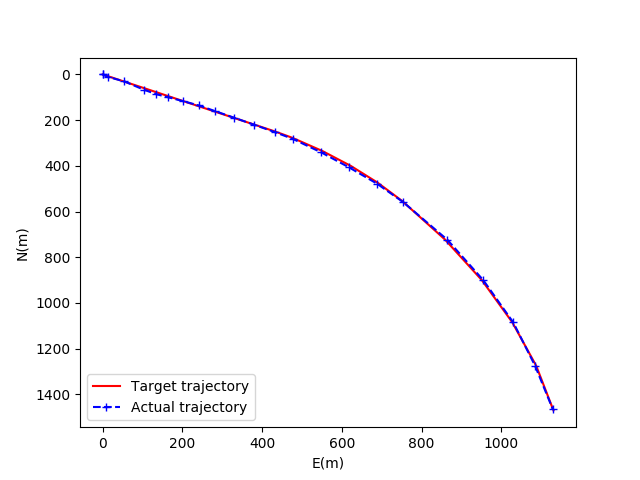
图6 基于RER的DDPG模型的水平投影图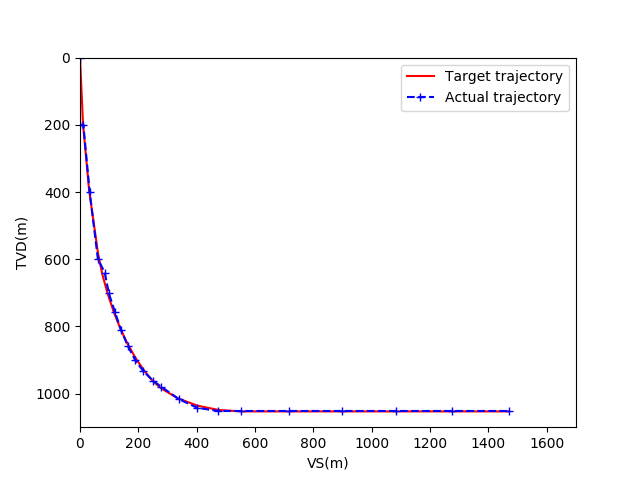
图7 基于RER的DDPG模型的垂直投影图
同理,图8、图9、图10分别为基于优先级经验回放机制的DDPG模型在收敛后的井眼轨迹对比图、井眼轨迹水平投影对比图、井眼轨迹垂直投影对比图。
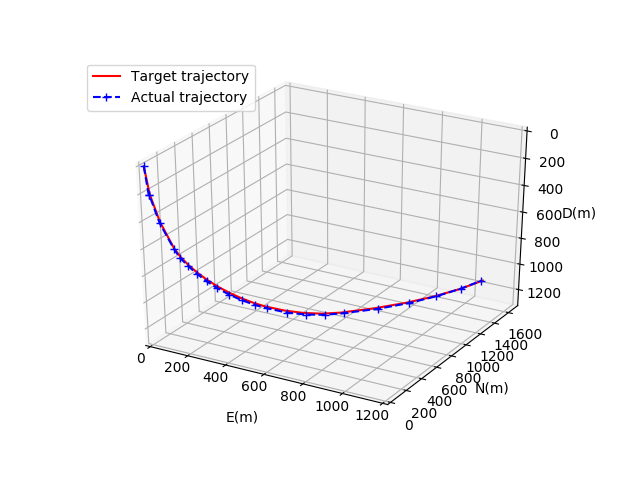
图8 基于PER的DDPG模型井眼轨迹比较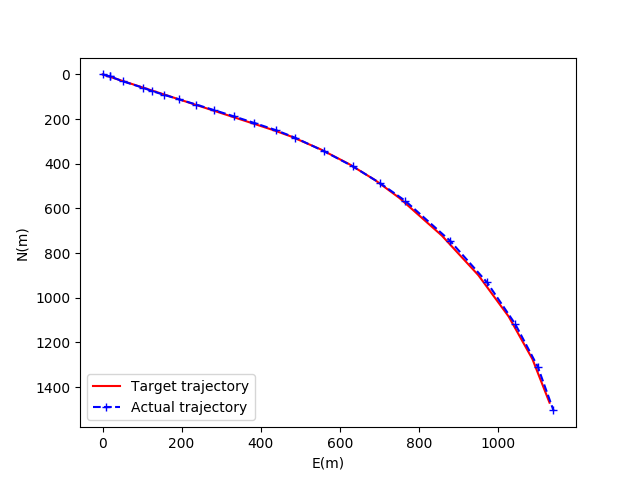
图9 基于PER的DDPG模型的水平投影图
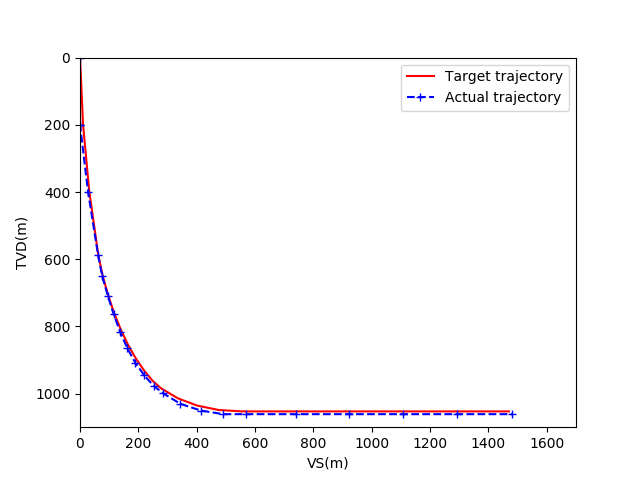
图10 基于PER的DDPG模型的垂直投影图
可以看出,在收敛后两模型的跟踪效果基本一致,均能完成对预设井眼轨道的跟踪任务。
为了进一步对比两模型的训练效率与跟踪性能,验证基于优先级经验回放机制的优化效果,本文采用最大偏移距离对两模型进行对比评估。图11为两模型的训练效果对比图。
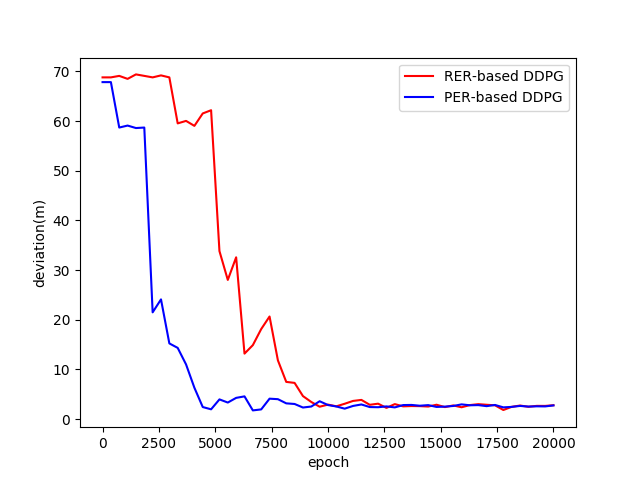
图11 两模型训练结果
两模型最终都能达到收敛,且收敛后的最大偏移距离基本一致,都在1.5米左右。但基于优先级经验回放机制的DDPG模型的训练效率明显优于基于随机经验回放机制的DDPG模型。在本实验中,基于优先级的经验回放机制的训练效率约为随机经验回放机制的两倍。
2.抗干扰实验
考虑到钻头和岩石之间的相互作用具有强烈的不确定性,本实验在钻进模型与地质模型之间采用了随机相互作用模型,该模型会导致角速度响应的随机结果,从而引发井眼轨迹控制的一定偏差。
对基于迁移学习的井眼轨迹自适应跟踪控制算法进行抗干扰训练,图12为算法收敛后的井眼轨迹跟踪情况。图13为井眼轨迹水平投影对比图,图14为井眼轨迹垂直投影对比图。

图12 干扰约束下的井眼轨迹
图13 干扰约束下的井眼轨迹水平投影图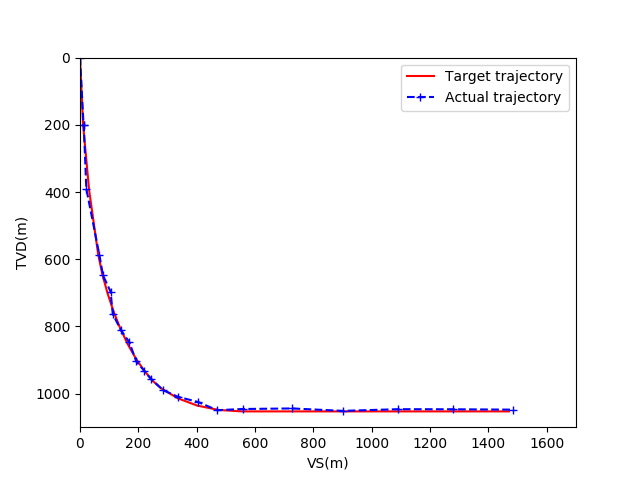
图14 干扰约束下的井眼轨迹垂直投影图
为了更加贴近实际工程,本实验增加了中靶率这一评价指标。在井眼轨迹跟踪控制算法的训练过程中,对每100条钻进轨迹进行中靶率计算。
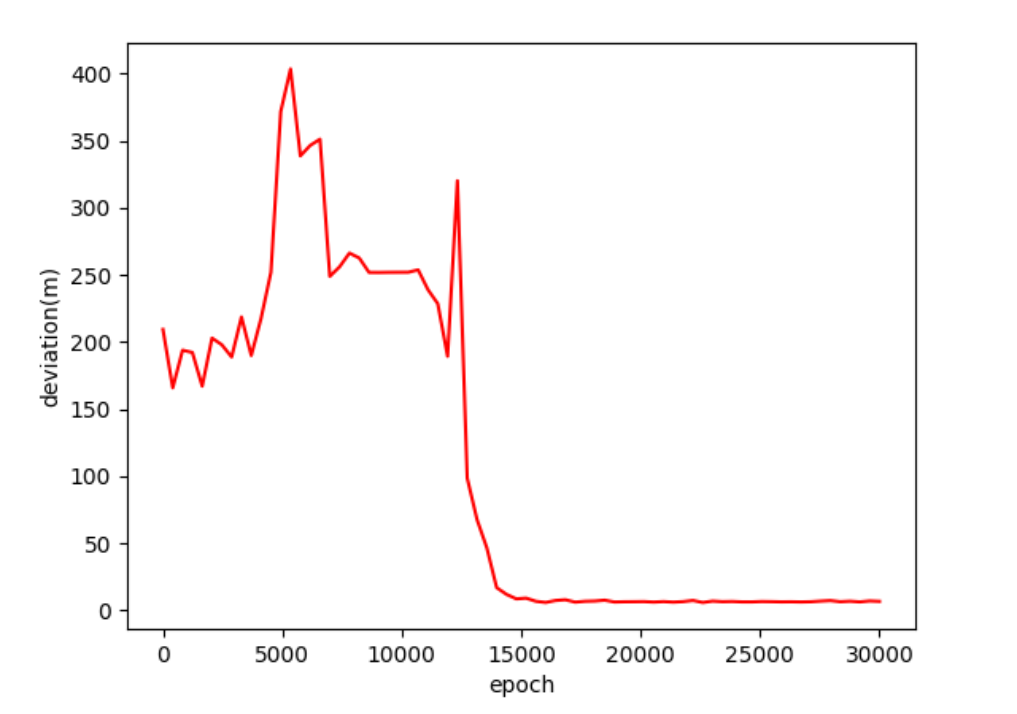
图15 干扰约束下的井眼轨迹最大偏移距离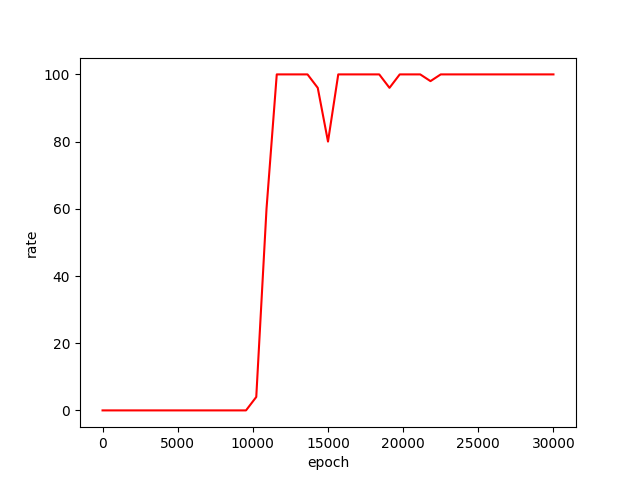
图16 干扰约束下的中靶率
在不确定干扰的约束下,井眼轨迹跟踪控制算法在15000步左右逐渐收敛。收敛后的井眼轨迹跟踪控制算法的井眼轨迹最大偏移距离为3m左右,中靶率约为97%。实验结果表明,基于迁移学习的井眼轨迹自适应跟踪控制算法具备良好的抗干扰能力,能够在干扰约束下完成较高精度的轨迹跟踪任务,成功引导井眼轨迹到达地层中的靶区。
3.自适应实验
本文在原有的三维模拟钻进环境中,在部分地质区块中加入了偏移处理。在钻进过程中,由于偏移处理,地层形态会随机发生细微变动,从而模拟目标轨迹与地层实际分布不一致的情况。
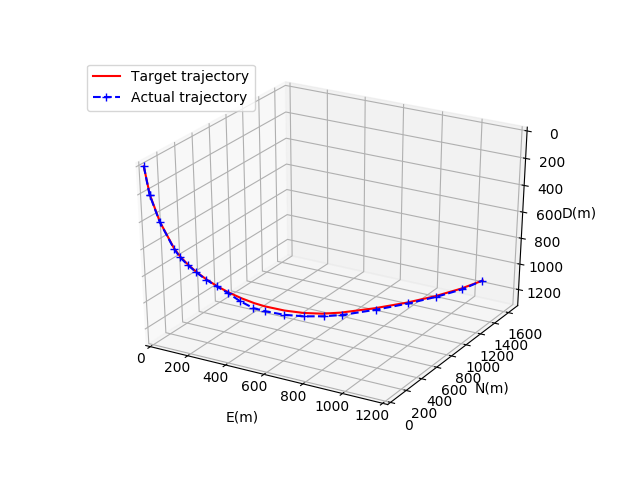
图17 自适应井眼轨迹
如图17所示,实际的井眼轨迹在偏移地质区块中与目标井眼轨迹产生了一定的偏离,而在非偏移地质区块中与目标井眼轨迹保持一致。
为了进一步分析井眼轨迹自适应跟踪控制算法的优化效果,本实验采用钻遇率这一指标进行评估。通过对比目标井眼轨迹与实际钻进轨迹的钻遇率,从而验证井眼轨迹控制算法的自适应能力。
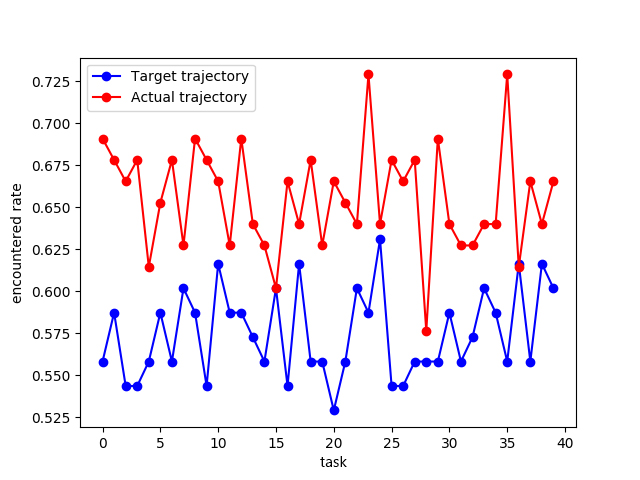
图18 钻遇率对比
结果表明,基于迁移学习的井眼轨迹自适应跟踪控制算法有效提高了钻遇率,相比于目标井眼轨迹,实际井眼轨迹的钻遇率约提高10%。由此可知,井眼轨迹自适应跟踪控制算法能够在钻进过程中根据测量到的随钻数据,进行自适应决策,优化井眼轨迹,提高目标油层的钻遇率。
结论:
本文提出了一种基于强化学习和迁移学习的自适应井眼轨迹跟踪控制方法。基于优先体验重放机制的DDPG算法可以根据井斜数据实时控制井眼轨迹,完成高精度的井眼轨迹跟踪任务。此外,迁移学习通过映射技术转移知识,提高了模型的学习效率和泛化能力。
该算法在三维模拟钻井环境中进行了训练和测试。本文利用随机生成的地质块作为钻井环境,基于不确定性干扰机制。这种方法模拟了不同的钻井环境,为算法自适应训练提供了一个高效的平台。实验结果表明,所提出的自适应井眼轨迹跟踪控制方法具有良好的抗干扰能力和自适应能力。通过算法的智能决策能力,可以规划出适合实际需求的井眼轨迹。该算法的反馈还可以帮助钻井人员评估情况。本文提出的方法有助于解决实际井眼轨迹跟踪控制技术面临的挑战,为智能井眼轨迹跟踪控制提供了新的思路。
朱丹丹,博士,智能中心副教授,硕士生导师。目前主要研究方向是强化学习和数据挖掘。联系方式:zhu.dd@cup.edu.cn