
一种基于神经网络层贡献分析的高效微调方法
中文题目:一种基于神经网络层贡献分析的高效微调方法
论文题目:Efficient Neural Network Fine-Tuning via Layer Contribution Analysis
录用期刊/会议:The 2024 Twentieth International Conference on Intelligent Computing (CCF C)
原文链接:https://link.springer.com/chapter/10.1007/978-981-97-5591-2_30
作者列表:
1) 刘志卓 中国石油大学(北京)人工智能学院 先进科学与工程计算专业 博 22
2) 周南建 中国石油大学(北京)人工智能学院 计算机科学与技术专业 硕 23
3) 刘 民 中国石油大学(北京)人工智能学院 计算机科学与技术专业 硕 21
4) 刘志邦 中国石油大学(北京)人工智能学院 控制科学与工程专业 博 21
5) 徐朝农 中国石油大学(北京)人工智能学院 计算机系教师
文章简介:
随着物联网技术的快速发展,各类智能设备在智能家居、智慧城市和工业自动化等领域得到了广泛应用。然而,隐私问题随着设备的普及而日益突出,促使在本地设备上进行模型训练成为趋势。由于物联网设备计算资源有限,如何在这些受限条件下高效训练模型成为重大挑战。物联网场景中,单个设备产生的数据量通常较小,传统深度神经网络训练难以获得满意的效果,因为深度学习模型通常需要大量标注数据,而本地设备上的小样本数据集难以满足这一需求。为此,少样本学习技术应运而生,旨在利用少量样本数据进行有效模型训练。迁移学习作为少样本学习的一种变体,通过预训练模型获取先验知识,再通过微调适应特定任务,从而在数据量较少的情况下仍能取得不错的推理精度。迁移学习中的特征重用是关键步骤,通过使用预训练模型中的特征提取器,从少样本数据集中提取特征向量,提升分类的精度。然而,简单利用少样本数据集训练分类器易导致过拟合。为解决这一问题,少样本分类方法兴起,利用度量学习或原型网络技术,通过建模样本间的距离进行分类,有效避免过拟合问题。这些方法通过相似样本聚类、不相似样本分离,分类效果显著,但其性能仍有提升空间,进一步优化少样本分类方法仍是一个重要的研究方向。
本文的主要内容如下:
本文首先量化分析神经网络各层对模型推理性能的贡献,基于这些分析寻找最优微调策略以最大限度提高精度,然后利用求解器求得最佳微调策略。通过多次迭代,能够在保证推理精度的前提下,大幅减少微调所需的时间,从而使系统可以在资源受限的物联网设备中应用。与元学习相比,将微调所需的时间最多减少了36%。
由于隐私问题的日益突出,在物联网设备上部署深度神经网络逐渐成为一种趋势。然而,物联网设备有限的计算能力与神经网络训练所需的巨大计算资源之间存在矛盾。为提高训练效率,通常采用迁移学习方法。这种方法高度依赖微调,尽管微调对于模型的准确性至关重要,但也引入了额外的训练时间开销。为此,我们提出了一种高效的微调方法——基于神经网络层贡献分析的高效微调方法,旨在满足推理精度要求的同时加快微调速度。通过分析每一层对模型性能的贡献,构建了一个优化微调策略的问题模型,以最大化准确性。我们利用求解器识别出最佳微调方法。与元学习相比,在保持准确性的同时,将微调所需的时间最多减少了36%。
本文将每一层的推理准确性表现作为性能的直接指标,相较于其他代理信号,这更直接地反映了其对推理精度的重要程度。本文假设各层对推理精度的贡献是可以叠加的。在此基础上,我们引入了对各层分类特性的分析,以确保最佳策略不会破坏模型低层的特征提取能力,从而保留特征重用的效果。因此,可以建模为:
![]()
![]()
在深度神经网络中,各层权重对迁移学习的影响存在显著差异,这为模型训练策略提供了指导。本文旨在在保持推理精度的前提下尽可能的减少训练时间,因此提出了一种高效微调方法,优先处理对模型性能至关重要的层次。通过量化分析每一层对准确性的贡献,能够有效确定微调策略。
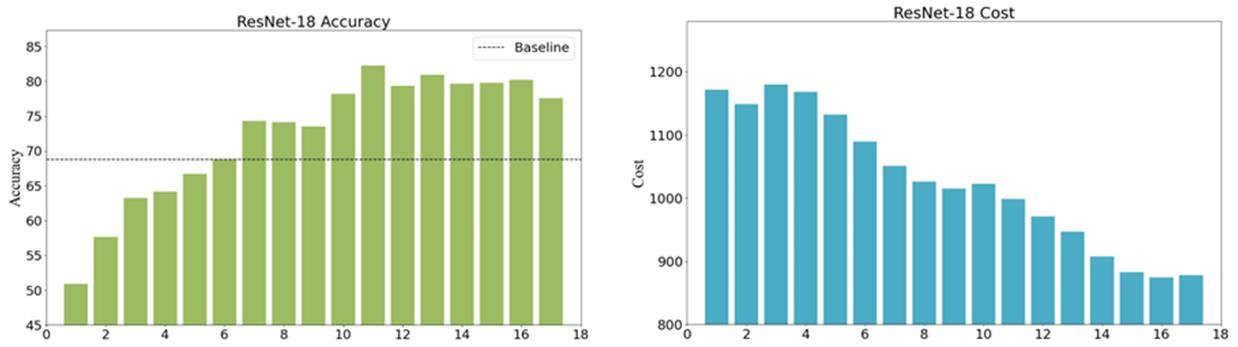
如上图,本文使用预训练的ResNet-18模型和CUB-200-2011数据集举例说明。首先,用少样本分类器替换模型的全连接层,并将此时的精度作为基准。然后逐层微调卷积层的权重,并记录每层权重对精度的增益。实验结果显示,不同卷积层对准确性的贡献不一致,且深层卷积层并不一定贡献更大;同时,微调所需的时间随着层的加深逐渐减少。这一现象与模型结构有关,因为计算较低卷积层的梯度时,即使不更新这些层的参数,仍需涉及与其他相关层的梯度计算。此方法能够在精度和微调时间之间取得平衡,进而选择出最佳的微调策略,以保证在达到最优推理精度的同时,微调时间消耗最小化。需要注意的是,预训练模型与少样本学习数据集之间存在关联,准确性会受到用于预训练的大规模数据集与小样本数据集之间差异的影响。
本文在同时引入了对各层分类特性的贡献分析。在预训练模型中,随着网络逐步向前推进,从较低层次提取基本特征,在较深层逐渐将不同的特征向量分类,最终输出图像分类结果。较低层的分类特性不明显,因为此时提取的主要是基本几何形状(如边缘和线条),这些特征在相对较低的层上可以重复利用。随着网络的加深,模型的分类特性逐渐变得显著,这表明要增强模型对特定任务的推理性能,微调应主要集中在较深层次。分类特性通过下式表示:
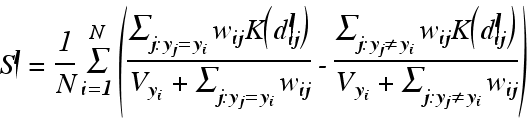
最后,本文将模型的全连接层替换为少样本分类器,此分类器由小样本数据集的支持数据集计算得出。
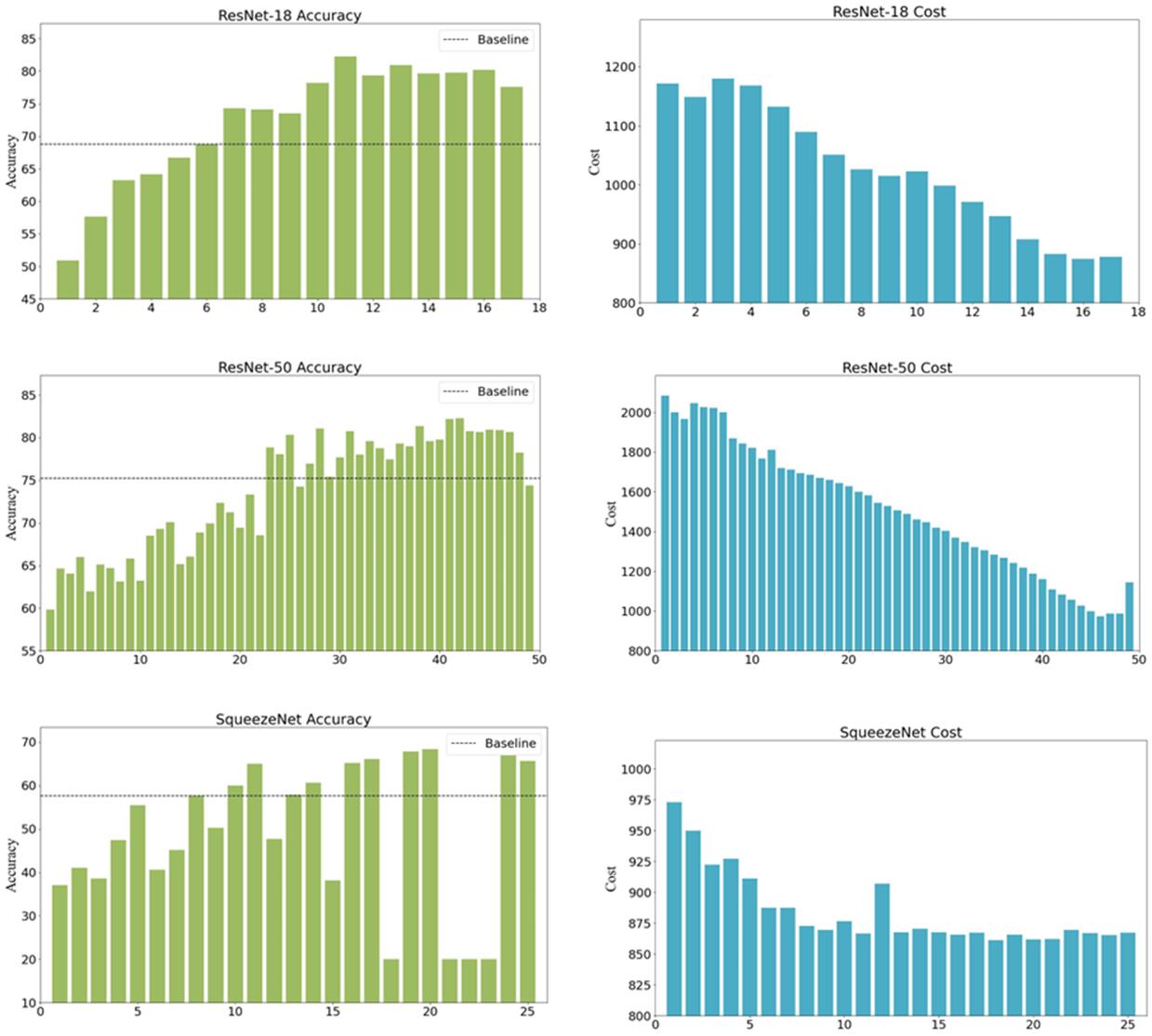
本文针对三种模型进行实验,包括了ResNet-18、ResNet-50和SqueezeNet。首先对层贡献进行分析得出微调方案,下图展示了各层对推理精度的贡献及对应消耗的时间。
本文与Meta-Learning方法和Prototypical Networks方法进行对比,实验结果如下:
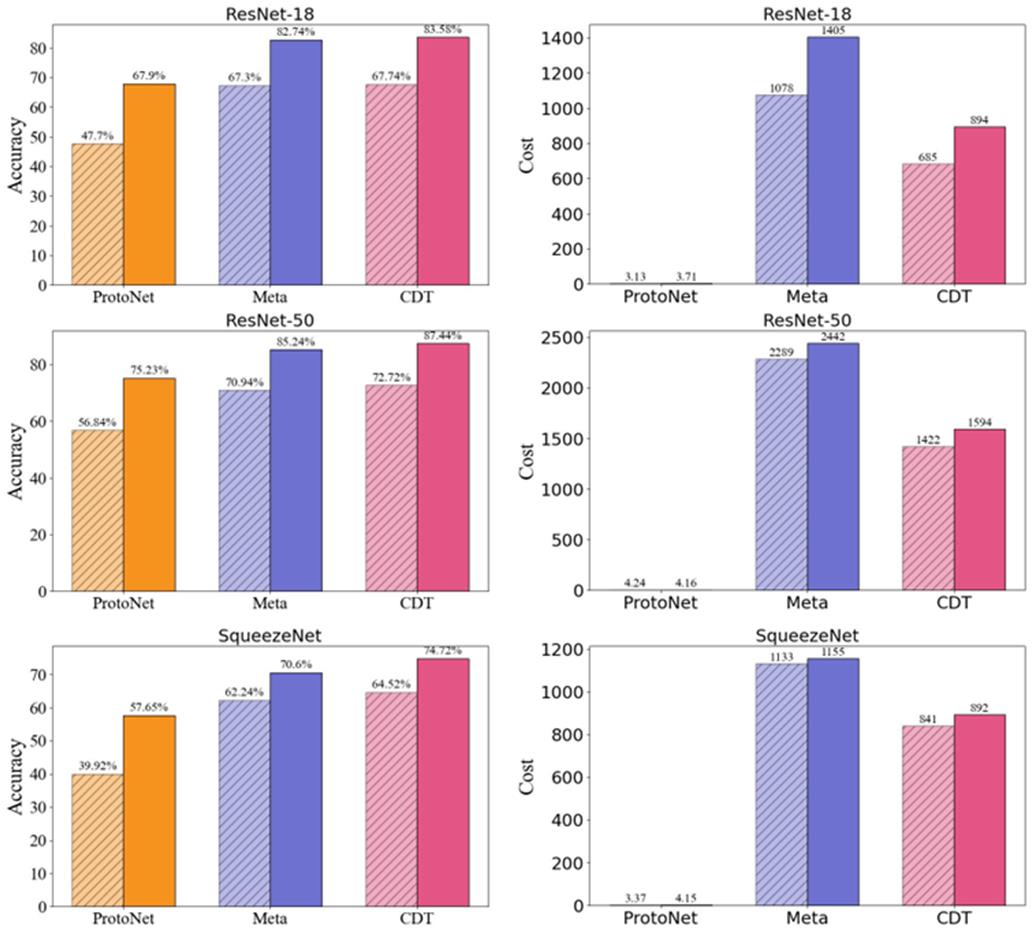
本文提出的高效微调方法在不同模型上都优于Meta-Learning,并且有![]() 的性能提升。
的性能提升。
本文提出的神经网络高效微调方法,在保持推理精度的同时降低微调时间消耗。通过分析模型各层的贡献,将寻找最佳微调策略的问题建模为优化问题,并利用求解器确定出高效的微调策略。与元学习相比成本降低了多达36%。这一方法加速了模型训练过程,使其在执行特定任务时更加高效。
徐朝农,中国石油大学(北京)人工智能学院教师,主要研究领域为边缘智能、嵌入式系统、无线网络。