
面向全球含油气盆地知识图谱和文档的混合问答方法
中文题目:面向全球含油气盆地知识图谱和文档的混合问答方法
论文题目:Hybrid Q&A Method for Knowledge Graph and Documents of Global Petroliferous Basins
录用期刊/会议:油气田勘探与开发国际会议(IFEDC)(EI)
原文DOI:doi.org/10.1007/978-981-97-0272-5_21
作者列表:
1)季廷雨 中国石油大学(北京)人工智能学院 计算机技术 硕20
2) 李大伟 中国石油勘探开发研究院 高级工程师
3) 袁明才 中国石油大学(北京)人工智能学院 计算机科学与技术 硕21
4) 牛 敏 中国石油勘探开发研究院 二级工程师
5) 米石云 中国石油勘探开发研究院 企业级专家
6) 安笑予 中国石油勘探开发研究院 助理工程师
7) 王 芬 中国石油大学(北京)人工智能学院 计算机技术 硕21
8) 鲁 强 中国石油大学(北京)人工智能学院 智能科学与技术系 教师
摘要:
勘探开发形成的海量含油气盆地数据和文档非常宝贵,需要利用新技术对其进行深层次挖掘利用,为勘探开发提供数据支撑和决策依据。知识图谱能够对这些数据和文档中蕴含的知识进行很好整合,然而它的概念及关系依赖人工建设,导致其覆盖的知识领域范围有限。传统的问答方法能根据问题在文档中获取相关答案,其具有知识覆盖面广的特点,但是它难以理解专业领域内容,导致其在含油气盆地领域的准确率偏低。针对以上问题,本文构建了一套面向含油气盆地知识图谱和文档的混合问答方法,将含油气盆地知识图谱作为专业背景知识库,并从文档资料中获取与专业相关的知识内容。其中,针对含油气盆地知识图谱,分析问句并与知识图谱进行实体对齐,将问句转换为结构化的图数据库查询语句并获取答案;针对含油气盆地文档资料,构建语义索引库,并根据问句检索得到候选文档,利用知识图谱嵌入方法将图谱信息与文档信息进行融合,构建深度语义匹配算法从候选文档中推理得到答案;针对两种问答方法得到的候选答案,设计重排序算法衡量答案与问题的语义匹配程度,对候选答案列表进行排序与展示。与传统问答方法相比,本方法支持面向含油气盆地知识图谱及相关文档的专业问答场景,提高了用户知识查询效率,在保证检索准确率的同时增加了查全率,最终提升了答案准确率。该方法具有操作方便、交互性强、答案精准等特点,为含油气盆地研究提供了知识的深度共享和应用平台。
设计与实现:
面向含油气盆地知识图谱和文档的混合问答方法总体框架如图1所示。具体流程为:(1)为大量文档内容构建全文索引和语义索引,根据问题检索得到候选段落,候选段落数量一般由人工设定为5-10个,通过图嵌入的方式将知识图谱信息与文档信息进行融合,然后采用深度语义匹配模型从候选段落中获取答案;(2)以含油气盆地知识图谱作为查询基础,分析自然语言问题并转化为图谱中存在的查询结构,在图谱中进行知识匹配从而获取答案;(3)采用答案重排序算法衡量问题与以上所有候选答案的语义匹配程度,集成为一个完整准确的答案列表。

图1 方法框架
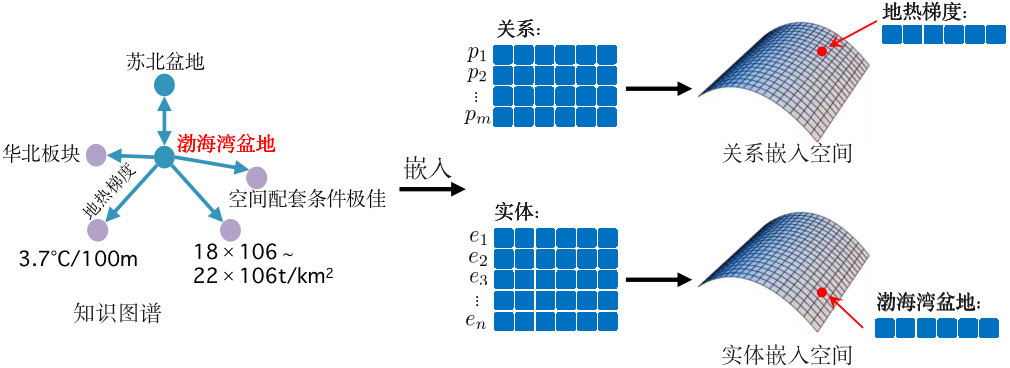
图2 图嵌入示例
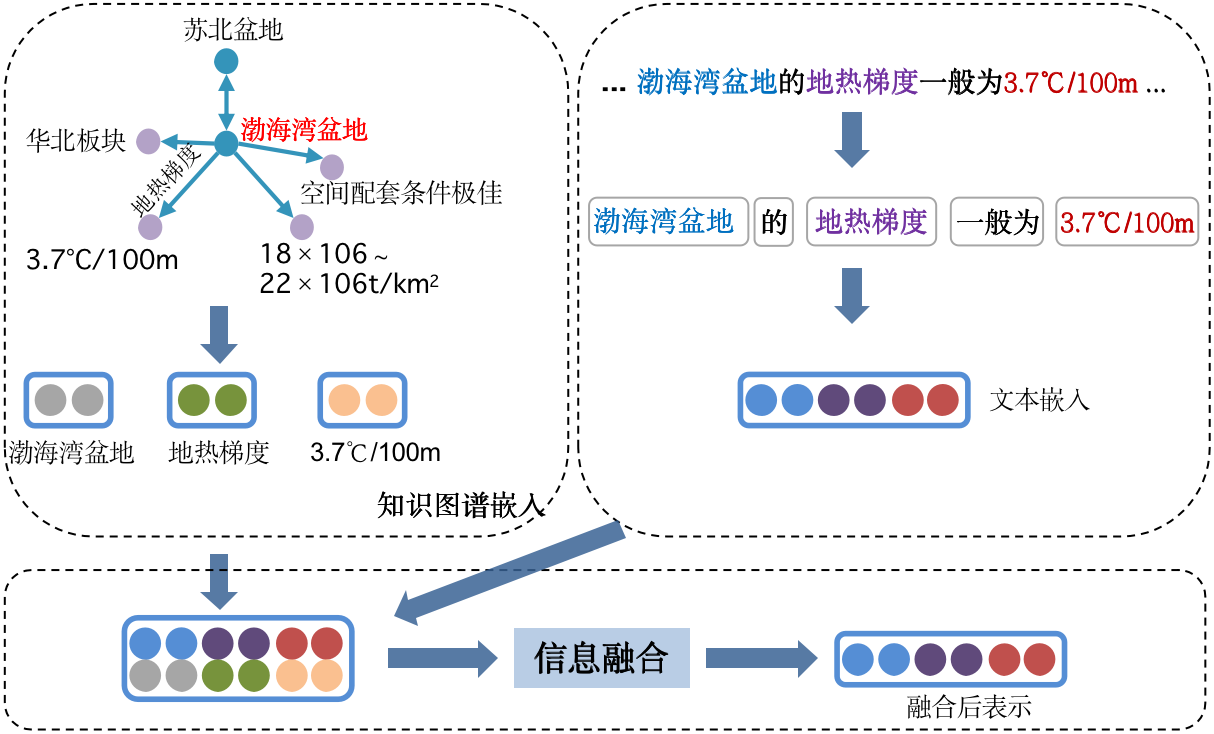
图3 知识图谱与文档信息融合
图嵌入如图2所示,将知识图谱中的实体和关系映射到高维向量空间。而知识图谱与文档信息的融合如图3所示。通过将知识图谱中实体“渤海湾盆地”“18×106~22×106t/km2”“3.7℃/100m”等表示与段落表示中的对应词的表示进行融合,增强了段落语义信息。其中,首先分析问句得到含油气盆地知识图谱中的对应子图;然后通过预先训练好的TransE嵌入模型得到问题对应知识图谱中实体的向量表示;最后使用自注意力机制融合编码文本段落信息和实体信息,从而得到更新后的段落表示。
深度语义匹配模型的结构如图4所示。首先,将问句和候选段落利用BERT预训练语言模型进行联合嵌入,获得的编码向量中融合了上下文的语境信息;然后,将编码序列首位[CLS]标记对应的向量作为聚合序列表示,训练分类器判断在该段落中问题是否存在答案;对于段落中不存在答案的情况,直接将答案设为空值;对于段落中存在答案的情况,利用序列标注模型进行词级别预测,确定答案在段落中的起止位置,抽取出对应的文本子序列作为答案。
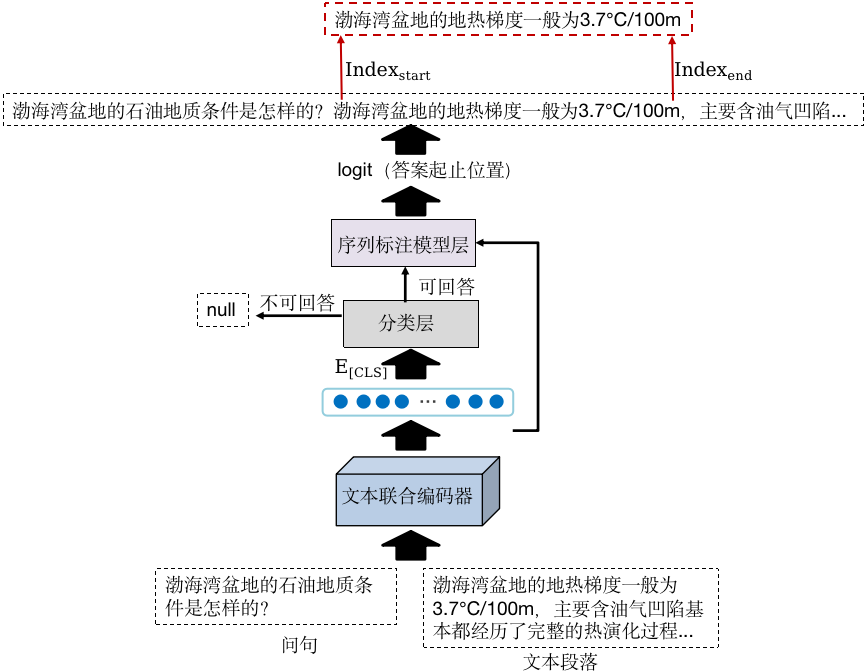
图4 深度语义匹配模型
另外,本文提出的混合问答方法中集成了知识图谱嵌入的文档问答方法和基于知识图谱的推理问答方法。如图5所示,通过设计重排序算法,将两种问答方法的结果进行融合,最后按照匹配度获取已排序的答案列表。
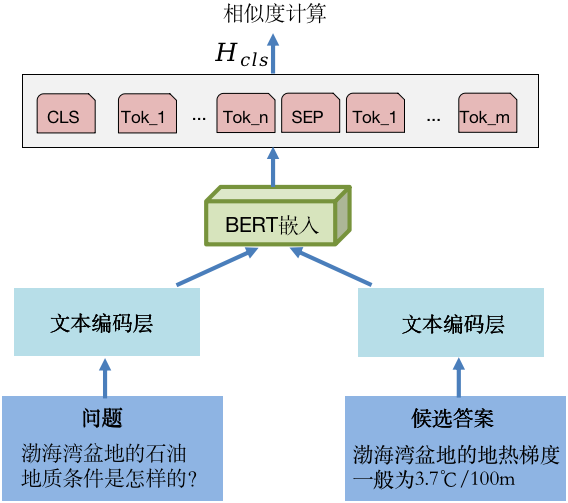
图5 答案重排序
实验结果及分析:
表1 检索数据集

表2 问答数据集
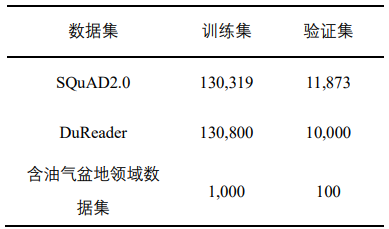
表3 检索效果对比
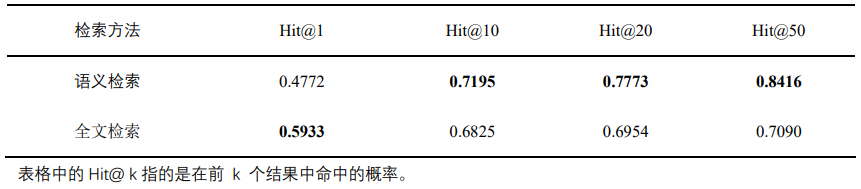
表4 重排序实验结果
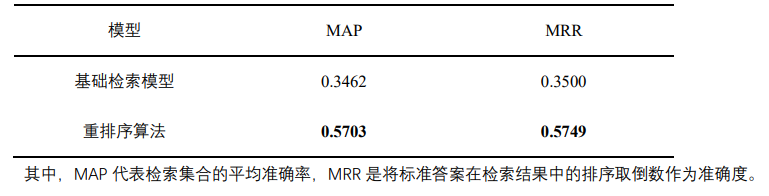
表5 SQuAD2.0数据集实验结果
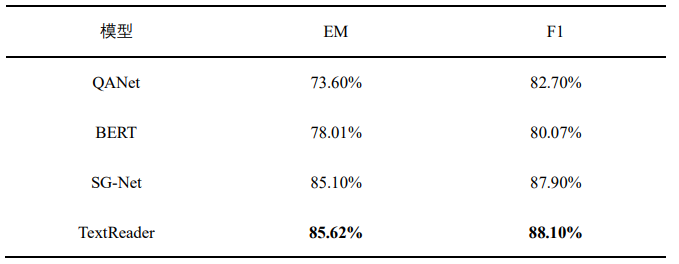
表6 含油气盆地数据集实验结果
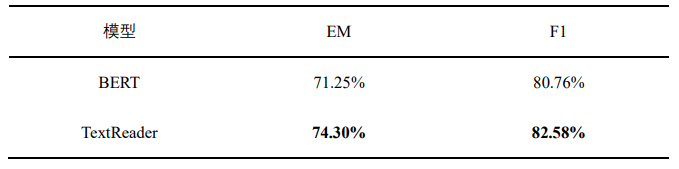
表7 混合问答方法在含油气盆地数据集实验结果

本文方法在全球含油气盆地领域的问答准确率达到84.38%,召回率达到85.95%,与单一的知识图谱问答和文档问答效果相比均有较大程度的提升,由此验证了混合问答方法的有效性。
结论:
本研究面向全球含油气盆地知识图谱与文档库设计并实现了一种混合问答方法,主要包括知识图谱嵌入的文档问答方法、图谱和文档答案的综合排序方法两部分。通过对问句进行语义分析,从知识图谱中匹配得到对应子图并推理得到候选的节点答案,然后将图谱信息与语义检索得到的候选段落信息融合并推理得到候选的文本答案,最后利用重排序算法将所有候选答案进行排序,生成答案列表。
本研究分别针对检索、问答和重排序三个方面展开了实验。通过实验分析可得:本文提出的混合问答方法能够改进候选文档的检索方式,提高整体查全率;能够扩大含油气盆地知识领域范围,同时支持面向含油气盆地知识图谱和文档库的两种专业问答场景;与传统问答方法相比,提升了全球含油气盆地领域的问答准确率。因此,本文研发的方法不仅提升了全球含油气盆地领域的问答效果,提高了盆地研究成果的共享水平和效率,还为研究人员提供了更好的勘探开发知识服务能力。此外,由于实验中发现本方法在领域数据集上的准确率低于公开数据集,因此加强模型对专业领域的适应性研究是下一步的工作重点。
通讯作者简介:
鲁强,副教授,博士生导师。目前主要从事演化计算和符号回归、知识图谱与智能问答、以及轨迹分析与挖掘等方面的研究工作。联系方式:luqiang@cup.edu.cn