
AmgT:Tensor Core加速的AMG解法器
中文题目:AmgT:Tensor Core加速的AMG解法器
论文题目:AmgT: Algebraic Multigrid Solver on Tensor Cores
录用期刊/会议:37th ACM/IEEE International Conference for High Performance Computing, Networking, Storage, and Analysis. (CCF A) Best Paper Finalist. 最佳论文提名
原文DOI:10.1109/SC41406.2024.00058
会议时间:2024.11.17-22
作者列表:
1) 卢玥辰 中国石油大学(北京)人工智能学院 先进科学与工程计算 博22
2) 曾礼杰 中国石油大学(北京)人工智能学院 计算机科学与技术 硕24
3) 王腾程 中国石油大学(北京)人工智能学院 计算机科学与技术 硕21
4) 付 旭 中国石油大学(北京)人工智能学院 计算机科学与技术 硕21
5) 李文瑄 中国石油大学(北京)人工智能学院 计算机科学与技术 硕24
6) 程贺琳 中国石油大学(北京)人工智能学院 计算机科学与技术 硕24
7) 杨德闯 中国石油大学(北京)人工智能学院 计算机技术 硕21
8) 金 洲 中国石油大学(北京)人工智能学院 计算机系教师
9) Marc Casas 巴塞罗那超级计算中心 首席研究员
10) 刘伟峰 中国石油大学(北京)人工智能学院 计算机系教师
摘要:
代数多重网格(AMG)方法因其灵活性和适应性,被广泛用于求解稀疏线性系统。尽管现代GPU为AMG提供了大规模并行计算能力,但其最新硬件特性(即Tensor Core及低精度计算能力)尚未被很好地用于加速AMG。本文提出了一个新的AMG解法器AmgT,其能够在AMG算法的多个阶段中利用最新GPU的Tensor Core和混合精度能力。我们首先提出了一种统一稀疏存储格式,充分利用Tensor Core及混合精度来提高AMG算法中频繁调用的稀疏矩阵-矩阵乘法(SpGEMM)和稀疏矩阵-向量乘法(SpMV)的性能,并尽量减少AMG整个数据流中格式转换的成本。同时,为更好地利用现有库中的算法组件,AmgT的数据格式和计算kernel被集成到HYPRE库中。实验结果表明,在NVIDIA A100、H100 和AMD MI210 GPU上,AmgT比原GPU版本的HYPRE平均快1.46倍、1.32倍和2.24倍(最高达2.10倍、2.06倍和3.67倍)。
背景与动机:
代数多重网格(AMG)方法因其灵活性和适应性,被广泛用于求解稀疏线性系统。尽管现代GPU为AMG提供了大规模并行计算能力,但其最新硬件特性(即Tensor Core及其低精度计算能力)尚未被很好的用于加速AMG。然而利用Tensor Core加速AMG面临着三个挑战:(1)存储方面,如何避免为SpGEMM和SpMV生成不同格式的矩阵;(2)计算方面,如何将一般稀疏结构与Tensor Core的严格稠密GEMM模式相匹配;(3)精度方面,如何将可变精度的SpGEMM和SpMV集成到AMG的完整数据流中。
设计与实现:
我们首先设计了一种统一稀疏存储格式mBSR(图1),这是经典块稀疏行(BSR)格式的一种变体。mBSR格式将稀疏矩阵存储在一组大小为4×4的稠密块中,并使用位图存储每个块中的非零元位置。
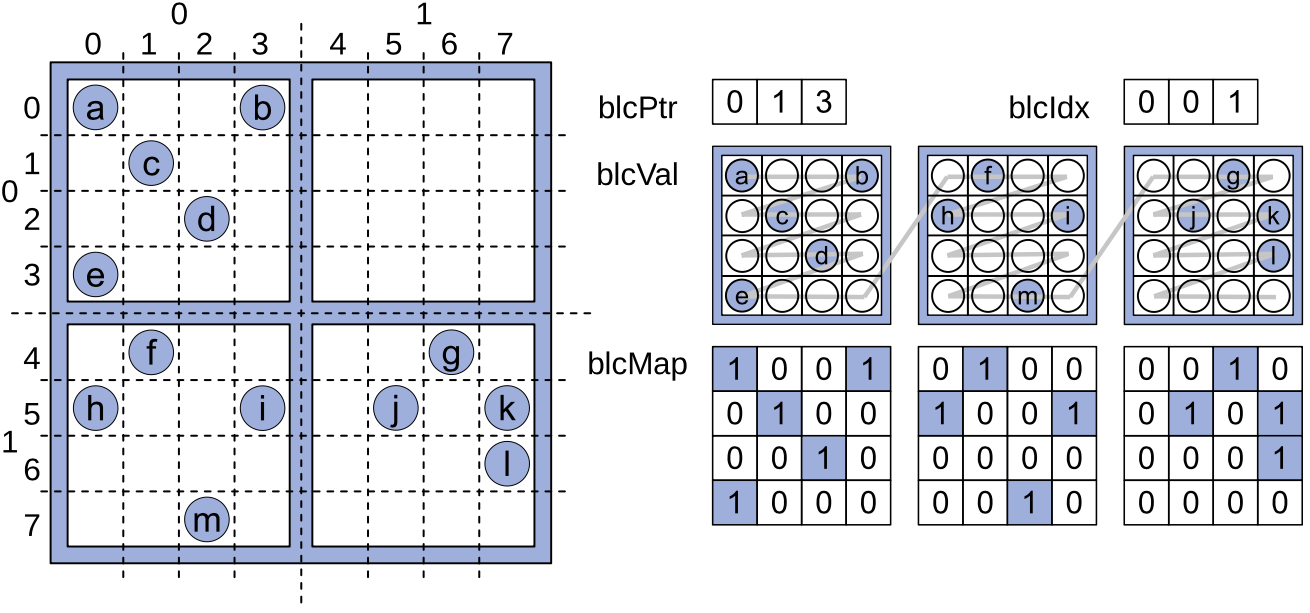
图1. mBSR格式
在这种数据格式的基础上,我们提出了一种新的AMG求解器AmgT,它在AMG算法的多个阶段利用了最新GPU的Tensor Core和及其低精度能力。AmgT基于新的SpGEMM(图2)和SpMV算法,能够根据块的稀疏程度同时使用Tensor Core和CUDA Core加速计算。AmgT中的SpGEMM算法会先分析矩阵数据,并将所有块行归入八个分区,然后执行两步哈希操作进行符号计算,以获取生成矩阵中块的位置信息,最后同时使用Tensor Core和CUDA Core进行数值计算。AmgT中的SpMV算法采用自适应性选择负载均衡和计算kernel策略,并同样实现了Tensor Core和CUDA Core的混合使用,以提高整体性能。
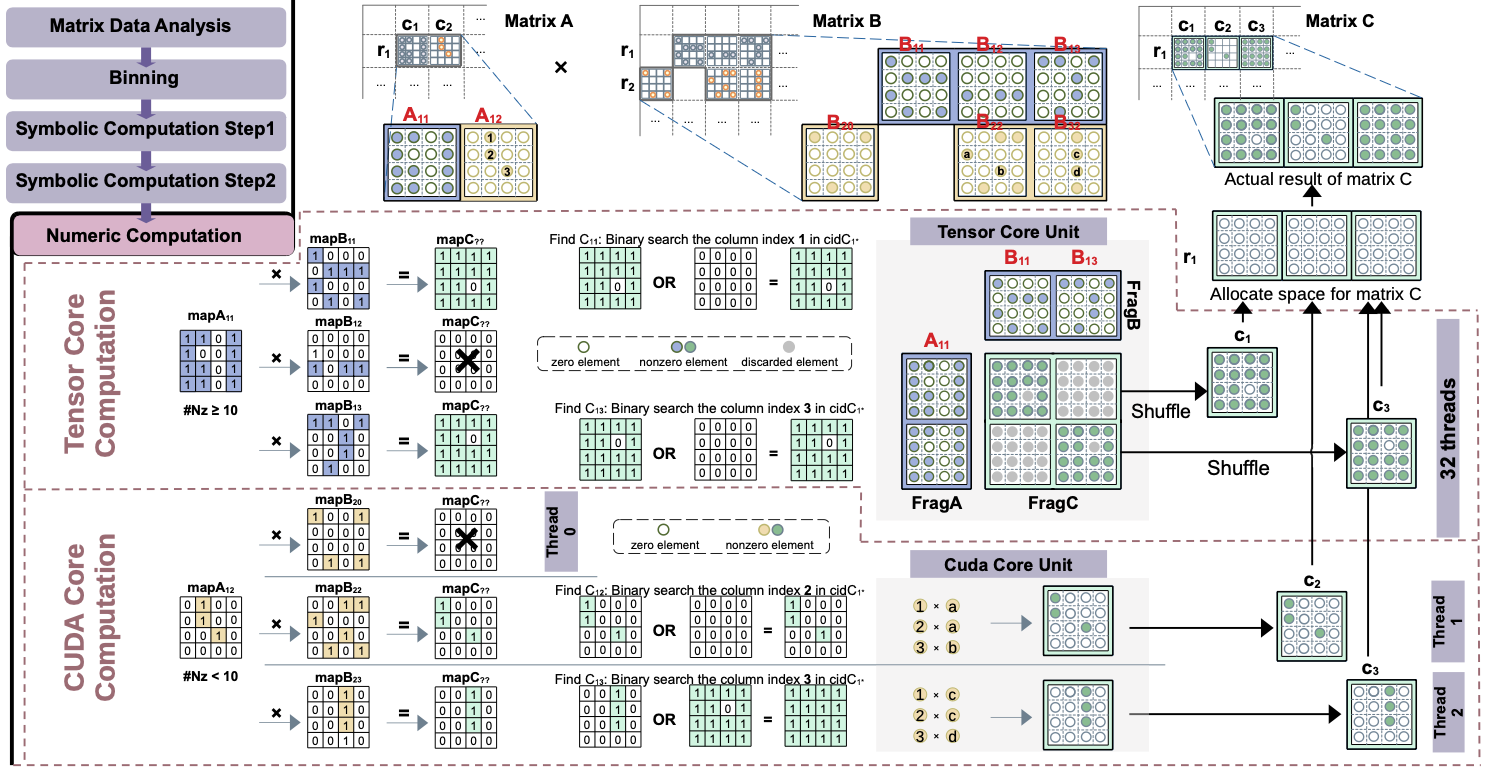
图2. mBSR格式的SpGEMM计算过程
最后,多种精度的新SpGEMM和SpMV算法分别在不同层的网格中调用,以有效利用Tensor Core的计算能力。
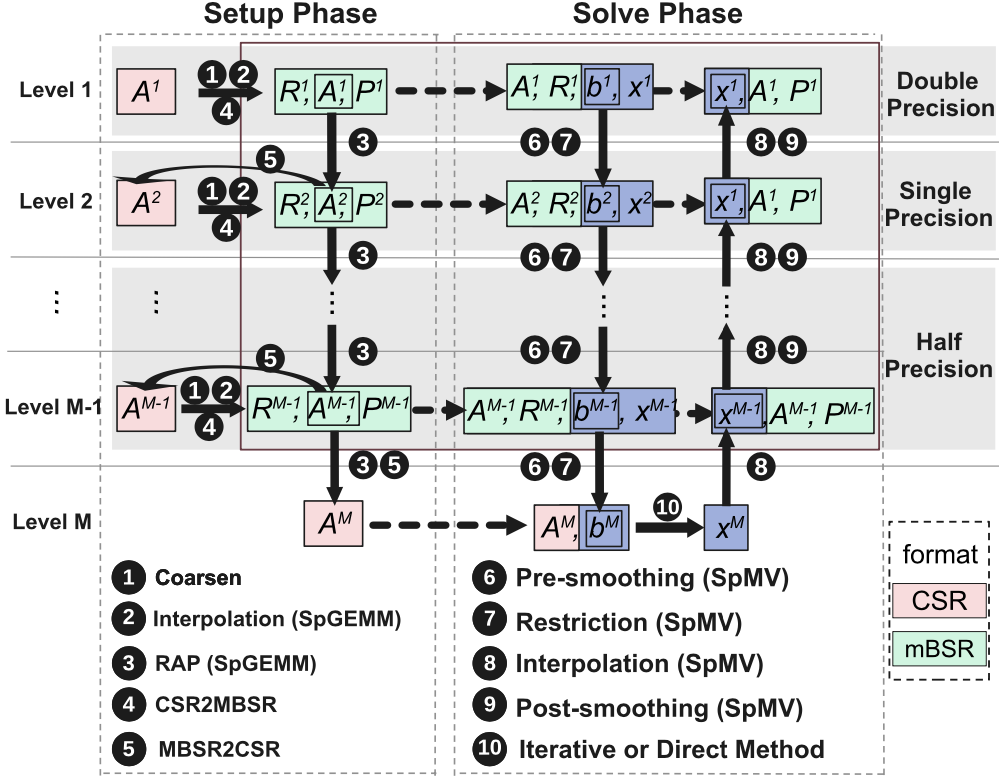
图3. AmgT的完整数据流
实验结果及分析:
为更好地利用现有库中的算法组件,AmgT的数据格式和计算kernel被集成到HYPRE库中。我们的测试平台为两款NVIDIA GPU A100(Ampere)和H100(Hopper)以及一款AMG GPU MI210(CDNA2),并测试了SuiteSparse矩阵集的16个代表性矩阵。
实验结果表明,在NVIDIA A100、H100 和AMD MI210 GPU上,AmgT比原GPU版本的HYPRE平均快1.46倍、1.32倍和2.24倍(最高达2.10倍、2.06倍和3.67倍),如图4所示。在A100和H100上,我们的混合精度AmgT比双精度AmgT分别快1.03倍和1.04倍(最高1.08倍和1.14倍)。此外,独立kernel测试表明,我们的SpGEMM比cuSPARSE和rocSPARSE SpGEMM分别快3.09倍、2.40倍和4.67倍(最高达7.61倍、6.11倍和5.96倍),SpMV在三个GPU上的性能分别是cuSPARSE和rocSPARSE SpMV的1.34倍、1.19倍和2.92倍(最高达2.21倍、2.09倍和6.70倍)。
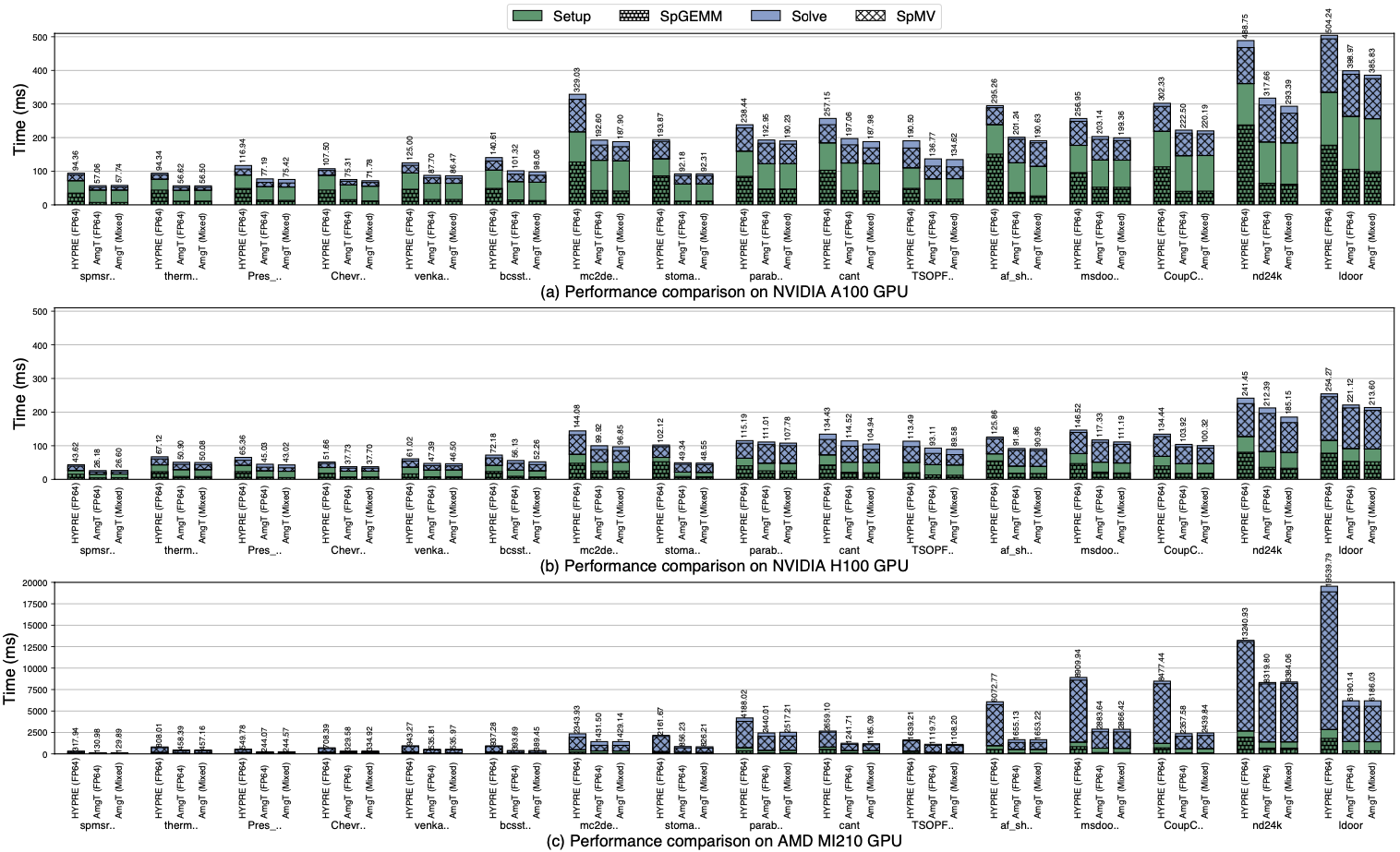
图4. 不同方法的AMG在三个GPU上的性能比较
我们还比较了双精度HYPRE、AmgT和混合精度AmgT在8个A100 GPU上的性能,如图5所示。与双精度HYPRE相比,我们的双精度AmgT方法的速度快了1.35倍(最高1.84倍)。此外,与双精度AmgT方法相比,我们的混合精度AmgT方法的速度快了1.06 倍(最高 1.11 倍)。虽然数据划分会导致通信成本增加、每GPU的计算量减少,但我们的算法仍能保持相对于调用cuSPARSE 的HYPRE的稳定优势。
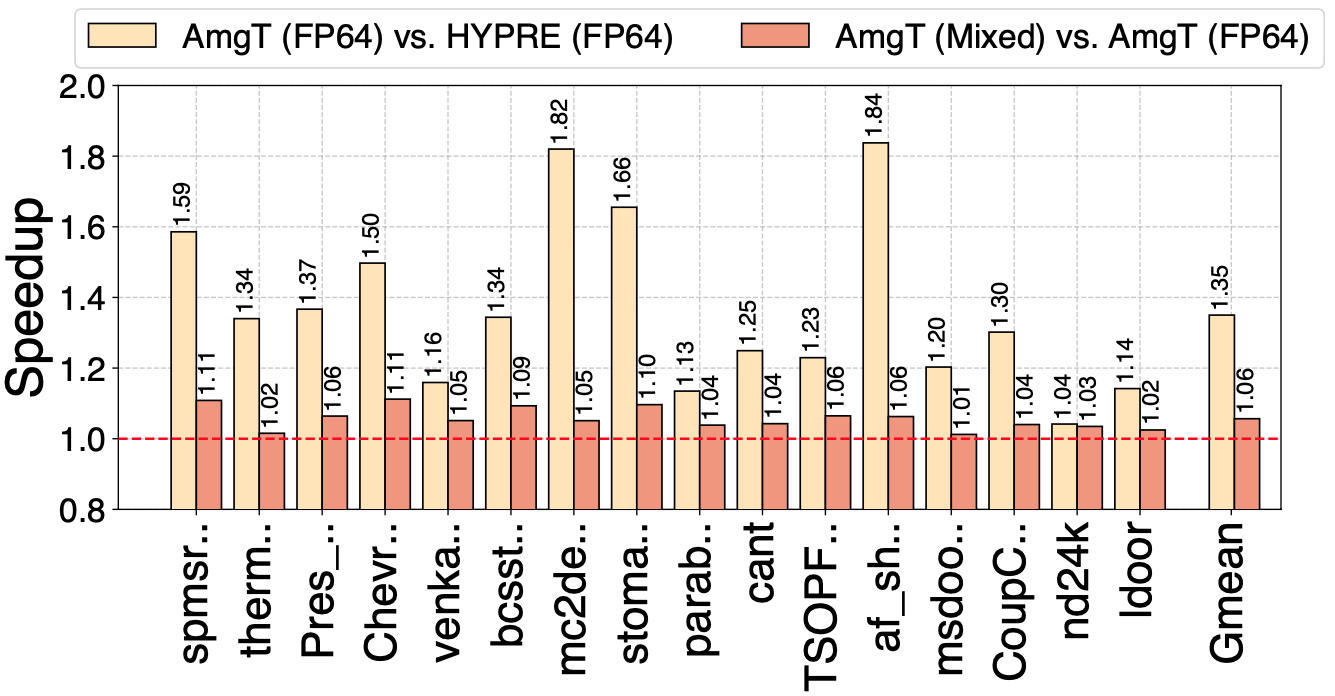
图5. HYPRE和AmgT在8个A100 GPU上的性能比较
作者简介:
刘伟峰,教授,博士生导师,欧盟玛丽居里学者。2002年和2006年于中国石油大学(北京)计算机系获学士与硕士学位。2006年至2012年在中国石化石油勘探开发研究院历任助理工程师、工程师和高级研究师,其间主要研究领域为石油地球物理勘探的高性能算法。2016年于丹麦哥本哈根大学获计算科学博士学位,主要研究方向为数值线性代数和并行计算,其中尤其关注稀疏矩阵的数据结构、并行算法和软件。研究工作发表于SC、PPoPP、DAC、ASPLOS、ICS、IPDPS、ICPP、TPDS、JPDC、FGCS和Parco等重要国际会议和期刊。担任TPDS、SISC和TKDE等多个重要国际期刊审稿人,以及SC、ICS、IPDPS和ICPP等多个重要国际会议的程序委员会委员。他是IEEE高级会员、CCF高级会员、ACM和SIAM会员。
联系方式:weifeng.liu@cup.edu.cn。