
基于衰减激励的筛选信息数据的化工过程建模
中文题目:基于衰减激励的筛选信息数据的化工过程建模
论文题目:Chemical process modelling using the extracted informative data sets based on attenuating excitation inputs
录用期刊/会议:【Journal of the Taiwan Institute of Chemical Engineers】 (JCR Q1)
原文DOI:https://doi.org/10.1016/j.jtice.2023.104872
原文链接:https://www.sciencedirect.com/science/article/pii/S1876107023002018
录用/见刊时间:2023年6月
作者列表:
1) 袁力坤 中国石油大学(北京)信息科学与工程学院/人工智能学院 博17
2) 徐宝昌 中国石油大学(北京)信息科学与工程学院/人工智能学院 自动化系副教授
3) 梁志珊 中国石油大学(北京)信息科学与工程学院/人工智能学院 自动化系教授
4) 王雅欣 中国石油大学(北京)信息科学与工程学院/人工智能学院 博19
快速发展的先进化学工艺的操作设计需要适当的模型和这些模型的参数识别需要高信息含量的输入输出数据集。最佳参数识别实验需要额外的持续激励输入来激励化学过程用于信息丰富的数据集,确保过程的动态信息。然而,最优识别持续刺激输入的实验是一项耗时、高成本的任务,可能会干扰过程操作。由于低成本识别的要求,这些实验无法应用,因此,研究有限的外部激励或从历史数据中提取的信息片段支持化学过程建模的问题显得尤为重要。
1.模型描述
考虑如下真实模型
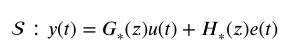
考虑误差的平方和函数可得模型参数为
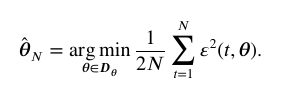
模型参数的误差服从高斯分布即
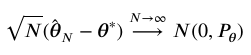
推导分析可得
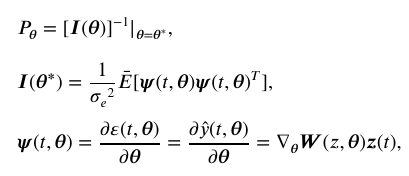
2.衰减激励
考虑衰减激励![]() ,由如下公式
,由如下公式
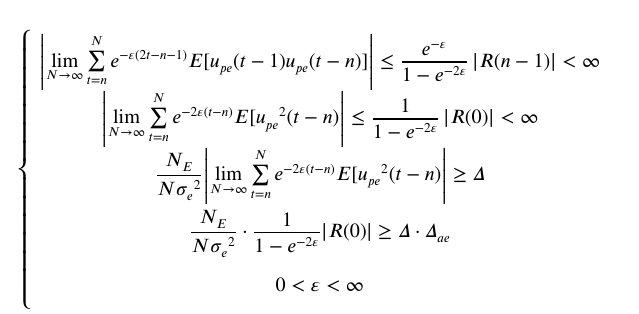
计算可得相应衰减系数合理的取值范围。
考虑衰减激励![]() ,由如下公式
,由如下公式
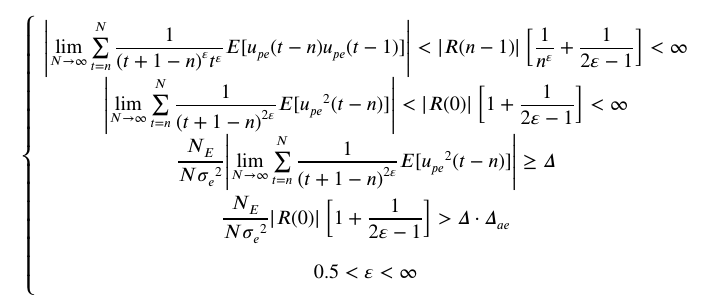
计算可得相应衰减系数合理的取值范围。
3. 逐步期望最大化法
利用如下公式实现信息数据的筛选和模型参数的估计。
SWEM-E步:
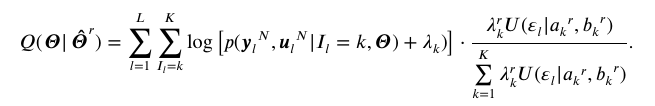
SWEM-M步:
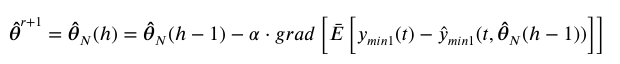
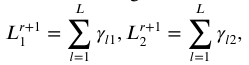
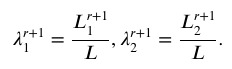
SWEM-EX步:
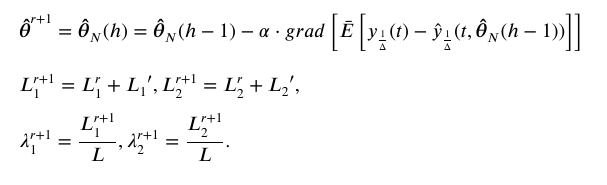
考虑一个典型的单入单出线性二阶ARX系统,可如下式表示
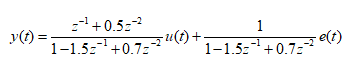
可得其相应的线性回归方程可写为
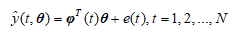
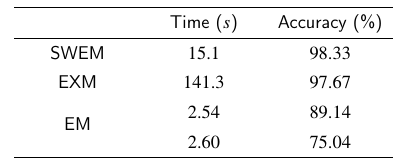
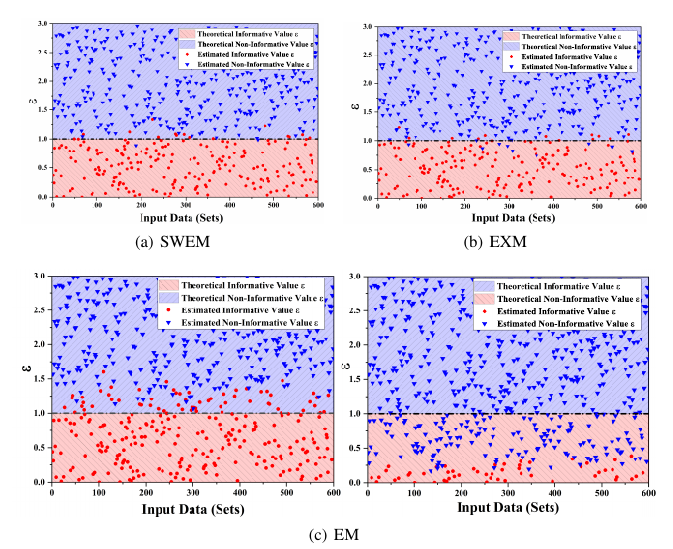
取衰减系数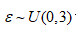 设计600组相互独立的数据集进行仿真实验,分析比较EM法、EXM法和SWEM法的性能,不同算法的计算时长和信息数据筛选精度下所示。SWEM法证明了计算得到的理论上
设计600组相互独立的数据集进行仿真实验,分析比较EM法、EXM法和SWEM法的性能,不同算法的计算时长和信息数据筛选精度下所示。SWEM法证明了计算得到的理论上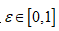 的合理性,反映出SWEM法在信息数据筛选和线性模型参数估计上的可靠性和有效性。
的合理性,反映出SWEM法在信息数据筛选和线性模型参数估计上的可靠性和有效性。
得到的模型阶跃响应如下所示:
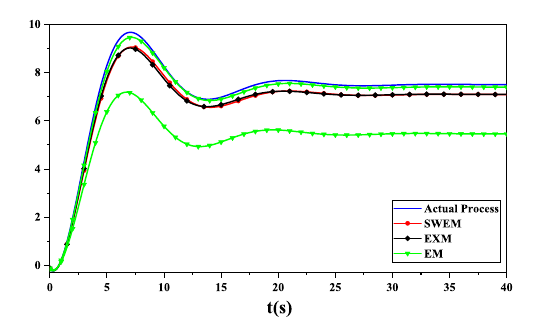
从上述结果可以看出,EXM法可以获得准确的信息数据筛选结果和所需精度的过程模型,但是计算时间较长;EM法计算时间较短,但是信息数据筛选结果不稳定,导致不合理的过程模型或信息浪费。只有严格合理地选择初值,才能避免上述情况。SWEM法融合了上述两种方法的特点,并克服上述缺点,降低了计算时间和初值选择要求,获得了准确的信息数据筛选结果和所需精度的过程模型。
本文在信息数据和衰减激励的基础上,提出了保证实验非信息性的测试数据标准,并对选定的衰减激励形式进行了实例分析,结果表明,在合理的衰减指标下,可以保证实验的非信息性,以保证所需的模型精度。本标准可用于在允许有限外部激励的情况下以最低成本进行测试输入设计,也可用于隔离历史数据。与现有的信息数据需求和工业历史数据策略相比,它可以将历史数据分析扩展为一种新的工业建模策略,还可以提高数据利用率,减少过程信息的损失,这对工业建模的低成本具有重要意义。同时,提出了一种SWEM方法,并仿真验证了其海量数据集分类的优点。该方法还用于验证理论衰减激励设计,实现了快速的信息片段提取和所需的精确过程模型。
徐宝昌,副教授,博士生导师,长期从事复杂系统的建模与先进控制;钻井过程自动控制技术;井下信号的测量与处理;多传感器信息融合与软测量技术等方面的研究工作。现为中国石油学会会员,中国化工学会信息技术应用专业委员会委员。曾参与多项国家级、省部级科研课题的科研工作,并在国内外核心刊物发表了论文60余篇;其中被SCI、EI、ISTP收录20余篇。