
基于音频感知身份补偿的一次性说话人头生成
中文题目:基于音频感知身份补偿的一次性说话人头生成
论文题目:One-shot Talking Head Generation with Audio-aware Identity Compensation
录用期刊:第五届物联网、人工智能与机械自动化国际学术会议 (IoTAIMA)(EI)
作者列表:
1)袁瑞鸿 中国石油大学(北京)人工智能学院 计算机技术 硕22
2)王智广 中国石油大学(北京)人工智能学院 计算机科学与技术系 教授
摘要:
生成说话头像的主要目标是基于输入音频信号和人物的源图像合成逼真且富有表现力的视频。这涉及到创建一个动态、同步且视觉上令人信服的人物表示,当人物表述提供的音频内容时,这些表示在图像中会相应展现出来。然而,生成视频中存在伪像,如嘴巴区域模糊、面部特征扭曲以及头部和嘴唇运动不稳定等问题。上述缺陷可归结为唇部未同步以及面部表示不足,这将极大地降低生成的说话头像视频的质量。为了解决这个问题,我们提出了一种基于一次音频感知的说话头像生成架构,称为AaICNet,该架构通过学习的全局面部特征进行补偿。我们使用AaICNet从随机给定的音频中获得唇部同步的音频嵌入,然后驱动肖像随着输入音频进行说话。具体来说,我们首先构建了一个音频编码器和面部编码器来提取音频特征和面部特征,并将它们合并成一个混合特征。为了准确塑造嘴唇运动,我们训练了一个强大的唇部同步鉴别器来生成驱动视频。在完成中间说话者训练阶段后,我们选择得分最高的LSE-C的人作为下一阶段训练的驱动图像。然后我们引入了一个有效的补偿模块,该模块计算全局面部结构并丰富变形后的源图像以供后续生成。大量实验表明,我们所提出的架构可以稳定地处理说话头像生成任务,并能在生成视频的视觉质量和唇部同步准确性之间取得良好的平衡。
背景与动机:
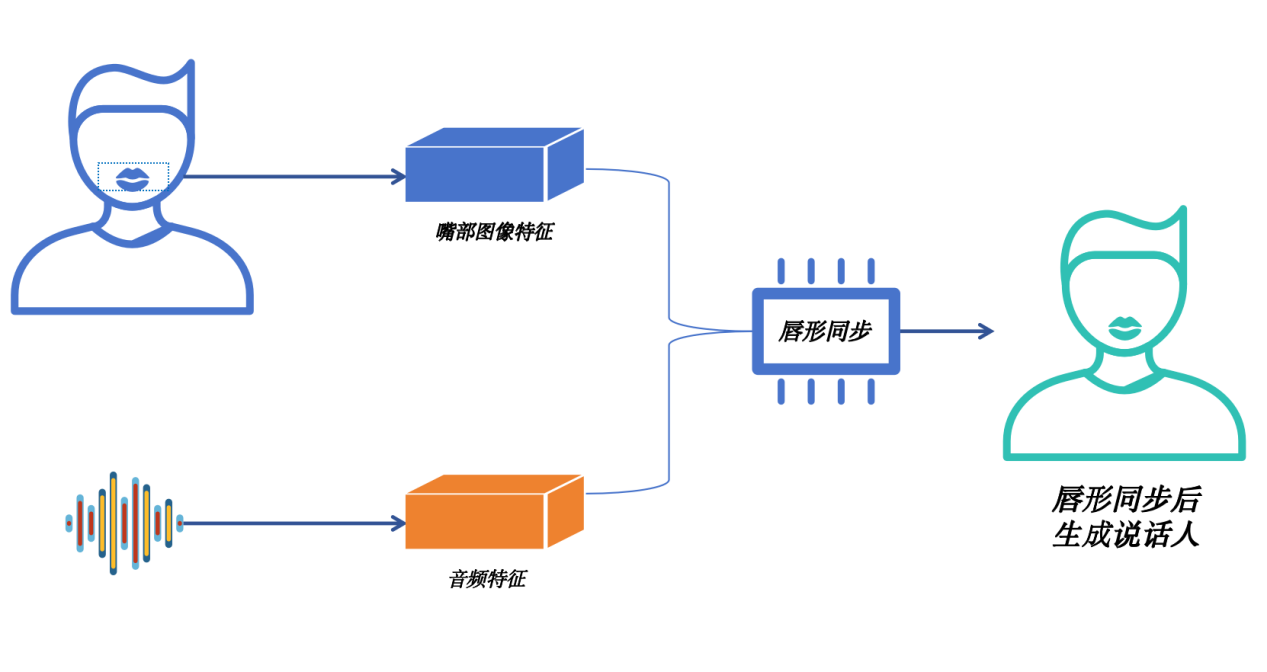
唇形编辑是指在视频处理和图像合成中,用声音信号将人物或虚拟角色的嘴部运动进行人为改变的技术。例如给定源视频(source video),再给定驱动音频(driving audio),那么得到的输出是源视频人物以驱动音频的音色和说话内容讲话,其唇部运动方式是与该音频对应的。
基于唇形编辑的说话头像的驱动技术的发展,促进了数字媒体时代中虚拟人物和人机交互体验的进步。在数字人物生成领域,通过应用包括深度学习在内的人工智能技术,数字人物已经逐渐拥有了更加逼真的外观和动态表现。近些年,这一趋势在各种领域中都体现出来,从娱乐产业中的游戏角色、虚拟主播,到商业应用中的虚拟销售都能看到其影响。
设计与实现:
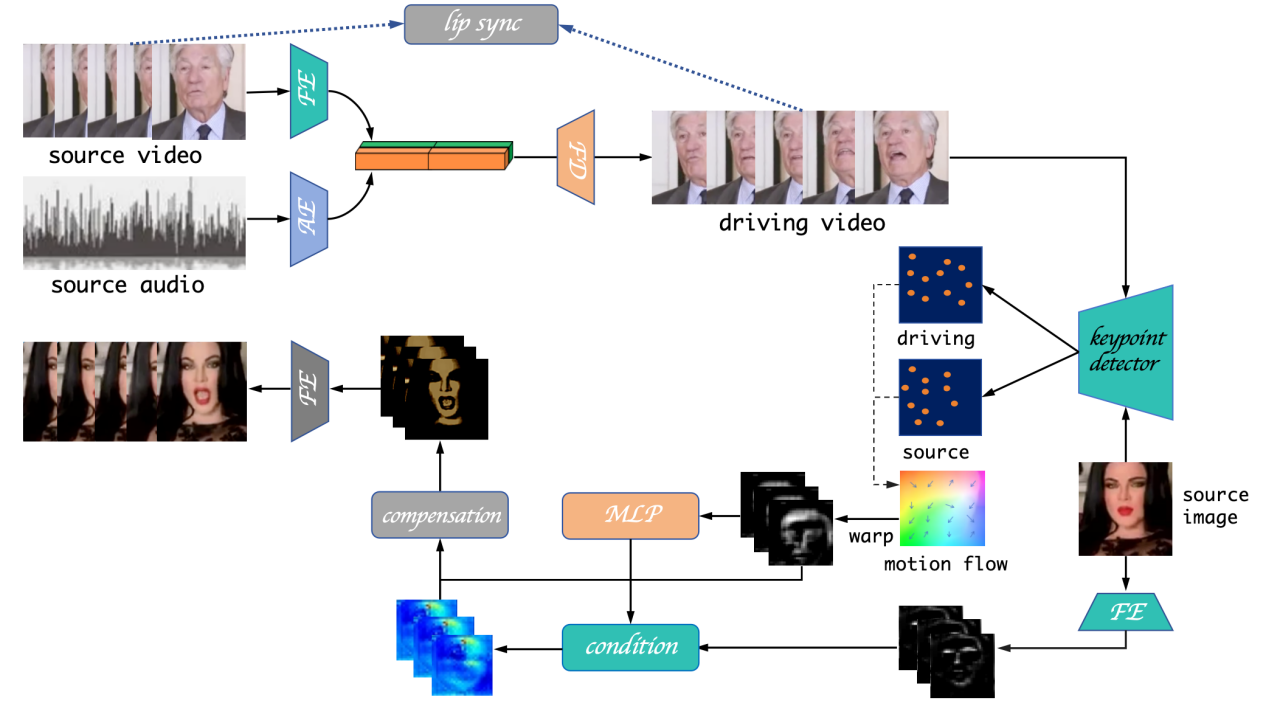
一次音频感知身份补偿的说话头像生成网络分为三部分:
(1)中间说话人生成模块:这个模块输入一个下半部分被遮挡的面部序列帧,然后将其与同长度的未遮挡面部序列进行连接,作为面部编码器的输入。未遮挡的面部序列提供姿势先验,以指导后续的重建过程。该模块主要是一个生成器-判别器架构。模型中包含面部编码器、音频编码器和面部解码器,每个组件由一系列卷积层组成。具体而言,音频编码器对输入音频片段进行编码,而面部编码器对随机参考帧进行编码。我们独特的损失函数结合了余弦相似度和二元交叉熵损失。接着,我们计算面部嵌入和音频嵌入之间的点积,以指示音频和嘴唇嵌入的同步概率。接下来,我们将音频嵌入和面嵌入拼接作为解码器的输入,经过解码器生成中间说话头像。如下图所示。
(2)最优中间说话人选择模块。在面部数据上经过大量训练后,中间说话者生成模块会产生许多由音频驱动的说话者化身。但并非所有这些化身对我们都有用。在最优中间说话者选择模块中,我们计算具有最佳唇部同步误差置信度(LSE-C)的图像,并保留此图像作为下一个模块的驱动化身。
(3)面部特征补偿模块。该模块首先接收最优中间说话者选择模块生成的图像(一次只接收一张)作为驱动图像和源图像。关键点检测器首先检测驱动图像和源图像的关键点对D和S,然后这些关键点配对将被用于估计D和S之间的光流(motion flow)。并利用该光流对第i个通道中的编码源脸特征进行扭曲(warp),生成扭曲特征。将源图像的这些关键点变宽,然后与扭曲的源特征连接在一起,然后送入多层感知机生成隐式的身份表示。我们从扭曲特征中提取数量是实际一半的特征并进行卷积变换以产生投影特征。我们训练了一个全局人脸记忆存储单元(memory bank),可以根据作为查询条件的来对人脸进行细节补偿。此外,我们采用交叉注意力机制来补偿扭曲的源特征。记忆产生k、q、v以对投影特征进行条件处理。
总体结构如下图所示
实验结果及分析:
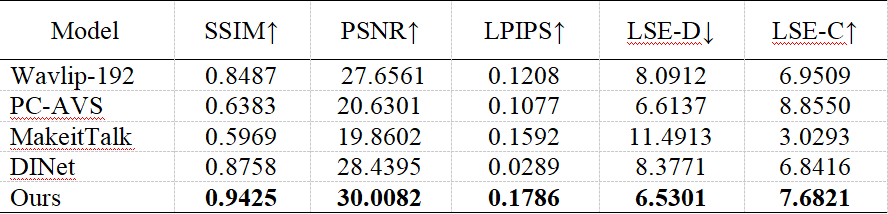
我们在VoxCeleb1和HDTF上评估我们的AaICNet,这两个数据集分别是低视觉质量数据集和高视觉数据集。VoxCeleb1包含有1251个说话人脸视频,而HDTF包含有430个高分辨率的说话人脸视频。我们在VoxCeleb1上训练我们的AaICNet并在HDTF上进行测试。我们利用结构相似性(SSIM)、峰值信噪比(PSNR)和感知图像块相似性(LPIPS)指标来评估低级相似性和感知相似性。同时,为了验证我们的架构是否能够生成准确的唇部运动,我们还使用唇部同步误差距离(LSE-D)和唇部同步误差置信度(LSE-C)作为我们的评价指标。下图为与其他四个不同的方法在HDTF数据集上的表现对比,进一步证明了我们的方法的有效性。
结论:
本研究对当前的说话人(talking head)生成方法进行了重新审视,针对唇形同步问题和面部补偿问题进行了深入研究。通过引入唇形同步模块对输出的说话人的音频效果进行约束,同时提出了中间人选择机制,来保证输出最终说话人与源说话人的身份一致性和结构相似性,同时还提出了全局面部特征记忆库,以解决之前生成的面部表情的缺陷问题。实验结果表明,我们的框架可以创建one-shot说话人肖像,同时具备精确的唇部动作和更高的保真度。本研究为后续对数字人领域的进一步研究提供了参考和对照。
通讯作者简介:
王智广,教授,博士生导师,北京市教学名师。中国计算机学会(CCF)高级会员,全国高校实验室工作研究会信息技术专家指导委员会委员,全国高校计算机专业(本科)实验教材与实验室环境开发专家委员会委员,北京市计算机教育研究会常务理事。长期从事分布式并行计算、三维可视化、计算机视觉、知识图谱方面的研究工作,主持或承担国家重大科技专项子任务、国家重点研发计划子课题、国家自然科学基金、北京市教委科研课题、北京市重点实验室课题、地方政府委托课题以及企业委托课题20余项,在国内外重要学术会议和期刊上合作发表学术论文70余篇,培养了100余名硕士博士研究生。