
基于最大均值差异领域泛化的化工过程智能辨识方法
中文题目:基于最大均值差异领域泛化的化工过程智能辨识方法
论文题目:An intelligent identification method based on self-adaptive mechanism regulated neural network for chemical process
录用期刊/会议:Journal of the Taiwan Institute of Chemical Engineers (JCR Q1)
原文DOI:10.1016/j.jtice.2023.105318
原文链接:https://doi.org/10.1016/j.jtice.2023.105318
作者列表:
1) 徐宝昌 中国石油大学(北京)信息科学与工程学院/人工智能学院 自动化系教师
2) 王雅欣 中国石油大学(北京)信息科学与工程学院/人工智能学院 控制科学与工程专业 博19
3) 孟卓然 中国石油大学(北京)信息科学与工程学院/人工智能学院 控制科学与工程专业 博20
4) 陈贻祺 中国石油大学(北京)信息科学与工程学院/人工智能学院 控制科学与工程专业 博21
5) 尹士轩 中国石油大学(北京)信息科学与工程学院/人工智能学院 控制科学与工程专业 博23
化工过程具有多变量、非线性、时变、强耦合等复杂特性,往往导致传统辨识理论在实际应用中效果不佳。近年来,深度学习的发展为非线性系统辨识带来了突破,但仍需要更多的进展。本文提出了一种基于自适应正则化神经网络的化工过程动态模型辨识方法。首先,为了提高神经网络应用于化工过程辨识的可靠性,提高泛化能力,将描述机理的已知微分方程作为正则化项来约束神经网络的输出。然后,提出了一种具体的训练方法,通过引入可训练的自适应权值,迫使神经网络专注于训练误差较大的区域。此外,针对机理方程中某些参数未知的情况,提出了一种半监督网络训练方法。最后,建立了一个动态虚拟装置(VD)模型来模拟被控对象的动态响应。在pH中和与连续搅拌釜反应器(CSTR)过程上进行的各种比较实验表明,该辨识方法能够获得鲁棒性强、精度高、泛化能力强的非线性动态模型。
深度学习方法主要基于数据驱动,需要大量的采样数据和丰富的信息。如今,先进控制系统和生产管理系统的引入使得工业过程可以实现快速、准确、稳定的控制。尽管从DCS中获得的样本数据数量巨大,但波动非常小。在某种程度上,这相当于重复的数据采样,数据覆盖率和代表性较差。而机理建模方法获得的模型虽有良好的可解释性和外延性,但对于复杂工业过程普遍存在求解复杂度过高等诸多难题,且实际模型往往会随着时间推移而与机理模型产生偏差。因此,提出了一种机理与数据融合驱动的非线性工业过程辨识方法,该方法利用已知的机理对深度网络模型进行约束,建立自适应机理正则化深度网络。
1.为了最大限度地减少传统化工过程辨识方法对化工厂运行的干扰,提出了一种基于工厂历史数据的神经网络辨识方法。此外,还采用了适用于控制领域的虚拟装置模型结构。
2.提出在已知化学过程机理的情况下,将常微分方程作为正则化项来约束网络的输出。这种数据-机理混合驱动建模方法可以在训练数据信息不足的情况下获得满足机理条件约束的模型,提高神经网络的可解释性和外推性。
3.对于部分机理参数未知的情况,提出了一种半监督训练方法,在估计未知机理方程参数的同时更新神经网络权重。
1)自适应机理正则化LSTM模型
MRLSTM框架由两部分组成。该框架的第一部分是LSTM网络结构。然后,LSTM网络的输出被输入到机理正则化部分,该部分本质上由描述动态过程遵循的q个微分方程组成,以评估微分方程的残差。本研究考虑以下形式的一般非线性常微分方程(Ordinary differential equation,ODE)作为已知机理方程:
![]()
![]()
MRLSTM的机理正则化部分定义为下式。其中,na为解空间中随机分布的配置点数量。显然,resi表示第i个常微分方程与模型输出在na个配置点下的残差之和。
![]()
接下来,将等式约束作为正则化项训练LSTM网络。通过组合与样本数据及残差相对应的损失来构建损失函数。其中ODE的残差的权重由可训练的自适应权重重新缩放。该方法使神经网络在求解方程的过程中自动聚焦误差较大的区域,并在损失较大的区域增加相应的权重。具体地,
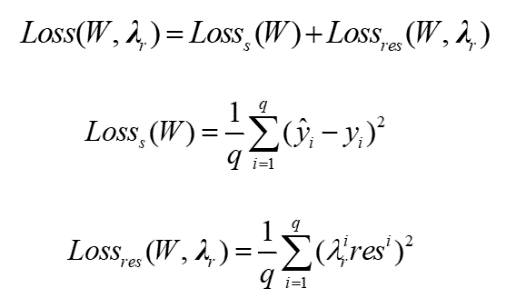
2)自适应训练算法
a. 所有已知机理方程参数为常数
在机理模型的所有参数都是常数的情况下,通过网络反向传播,以计算损失函数对LSTM网络的权重和残差的权重的梯度。如下式所示,所提出的训练方法的基本思想是在具有较大损失的区域中最大化相对于自适应权重的损失,并最小化相对于网络权重的损失。
![]()
在最小化损失函数的过程中,第t步的权重更新如下式所示。
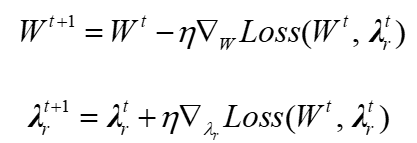
自适应权重梯度更新方程如下:
![]()
可以看出,如果权重向量初始值为非负值,则权重向量将为非单调递减。当方程残差和权重较大时,其梯度会相应增加,这是对不能很好地拟合机理方程的深度网络的惩罚。在具体的优化过程中,采用双层优化方法。首先使用Adam算法进行固定次数ep1的迭代优化,同时更新自适应权重和网络权重。然后使用二阶算法SGD-SRSO进行新ep2轮次的迭代优化,在此期间自适应权重保持不变,仅优化LSTM网络权重。
b. 部分机理方程参数未知
在未知的情况下,训练机理正则化部分的问题变成了半监督学习任务。具体实现方法为通过最大化关于自适应权重的损失并最小化关于网络权重和参数估计的损失来获得一致性参数估计:
![]()
其中,
![]()
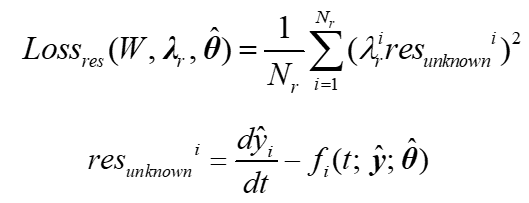
在最小化损失函数的过程中,第t步的权重更新如下式所示。
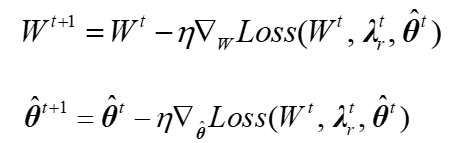
![]()
在半监督训练过程中,采用双层优化方法。首先使用Adam算法进行固定次数ep1的迭代优化,同时更新自适应权重,网络权重和未知机理参数。然后使用二阶算法SGD-SRSO进行新ep2轮次的迭代优化,在此期间自适应权重和未知机理参数保持不变,仅优化LSTM网络权重。
用于辨识的SA-MRLSTM结构如图1所示。
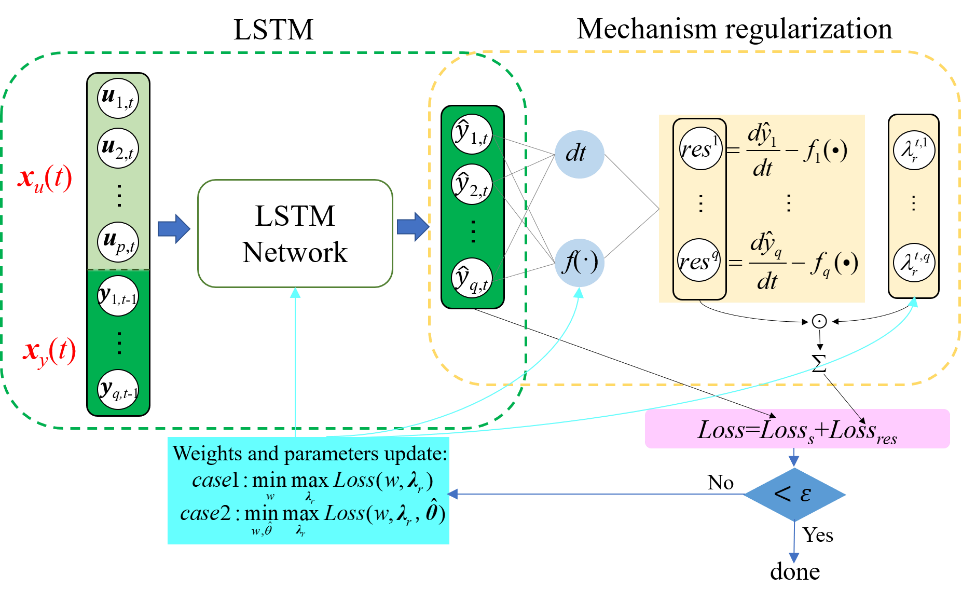
图1 SA-MRLSTM模型
3)虚拟装置模型(VD)构建
在神经网络训练过程中,模型的输入由实际采样数据组成。这种模型被大多数基于深度学习的非线性系统辨识方法所使用。然而,为了模拟被控对象对控制信号的响应,希望在训练结束后构建一个只使用CV的实际初始条件和MV的实际值作为输入的模型。该模型可以作为虚拟装置模拟受控对象在不同工况下的动态响应或测试控制算法的性能,更适合控制领域。因此,模型的输入向量由实际输入和预测输出组成,而不是实际输入和实际输出,如下式所示。
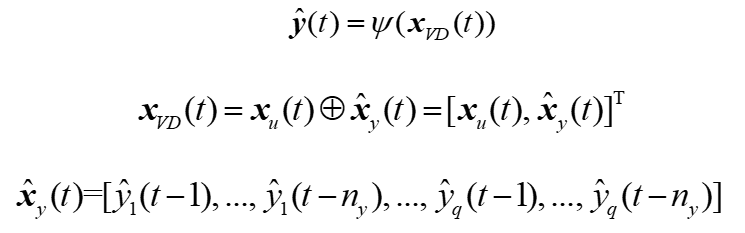
VD模型的构建如图2所示,其中MV是被控对象的输入,CV是被控对象的输出。在采用开环控制时,MV是手动给定的。对于闭环控制,MV是执行器在接收到来自控制器的控制信号之后的输出。VD模型的输入和输出向量的维数与STA-LSTM的相同。在初始时刻t0,STA-LSTM输入向量中的所有值都是预先设置的或通过实际采样获得的,网络计算的输出值则存储在数据库中。然后,在t0+1时刻,网络输入向量中的元素为来自上一时间步存储在数据库中的输出值,而不是实际采样。在之后的时间步里,VD模型的输入向量中的xy(t)部分的每个元素的值都来自网络本身的先前计算结果。
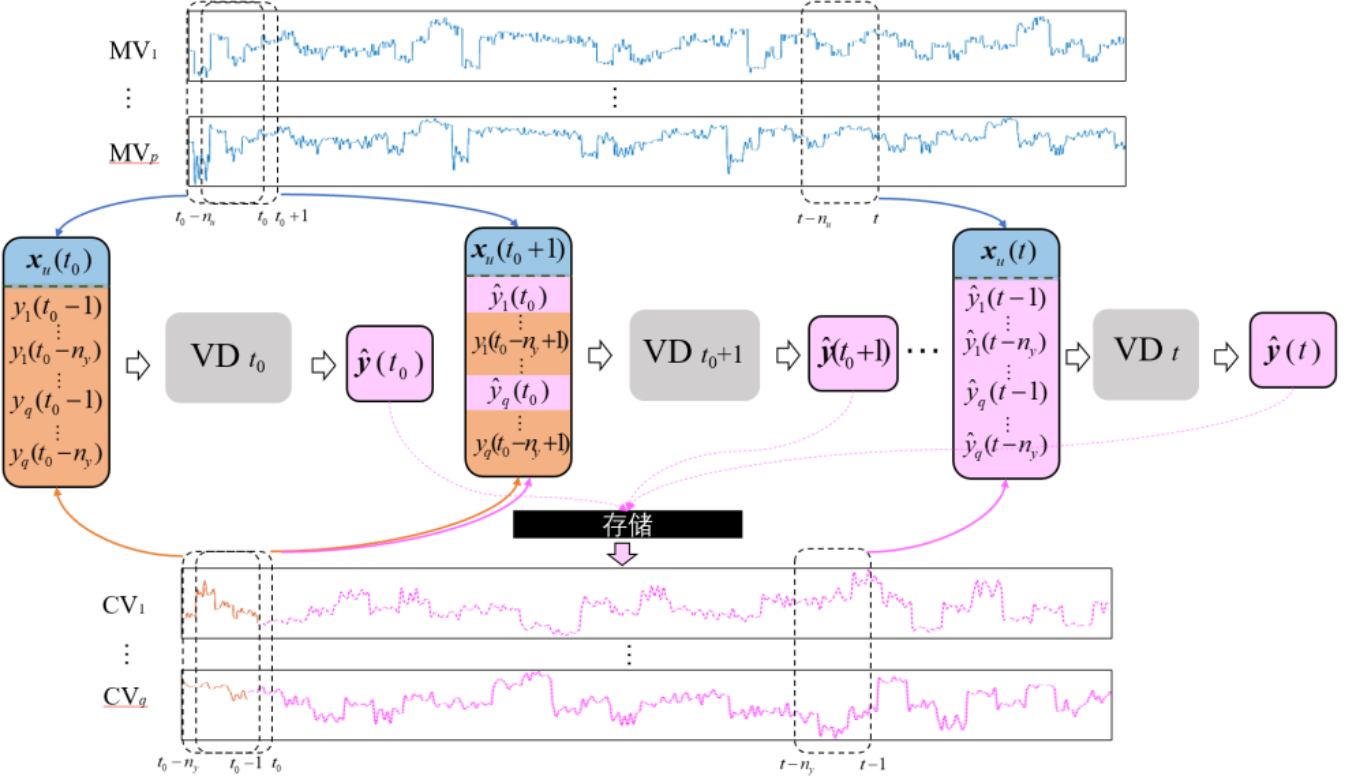
图2 VD模型构建示意图
以pH中和过程与CSTR过程为例进行实验,验证SA-MRLSTM模型和相应双层优化算法的有效性和优越性,以及在CSTR机理方程参数k0未知的情况下所提出的训练算法的鲁棒性。
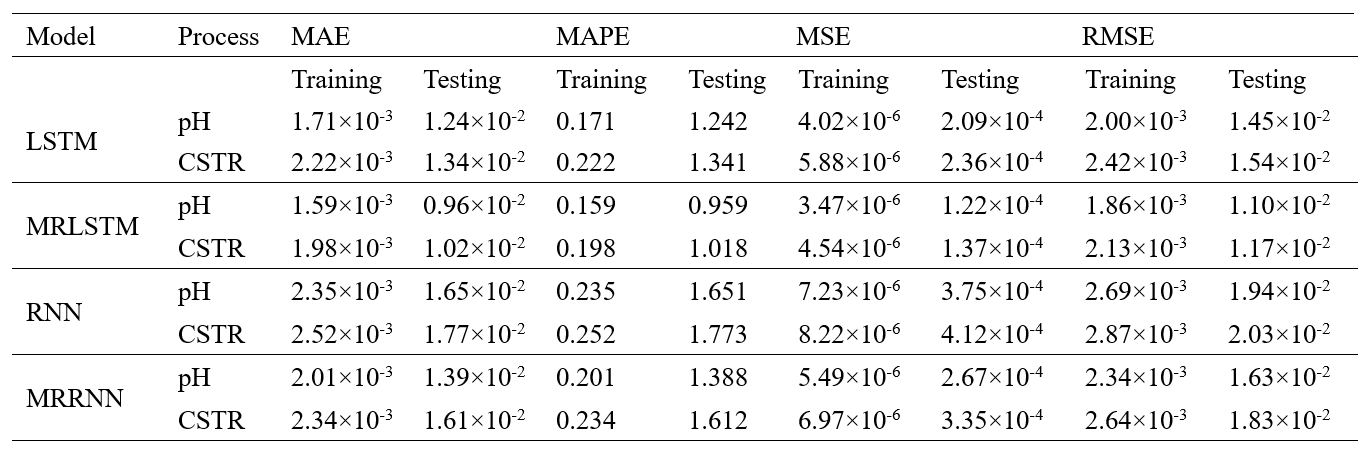
表1 不同模型结构下的实验结果
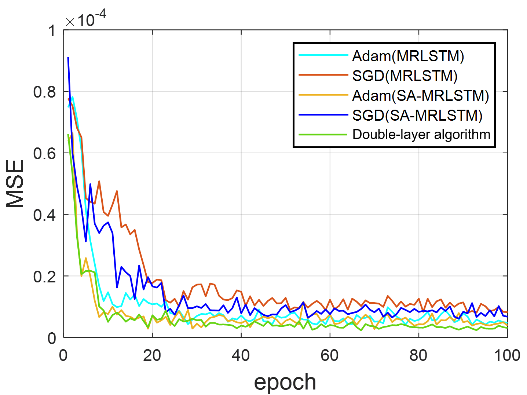
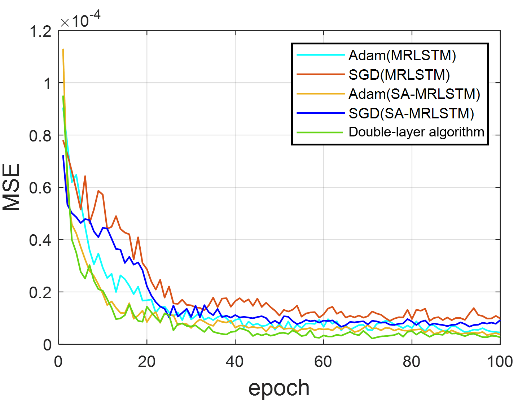
(a) pH中和过程 (b) CSTR 过程
图3 不同优化算法的训练误差对比
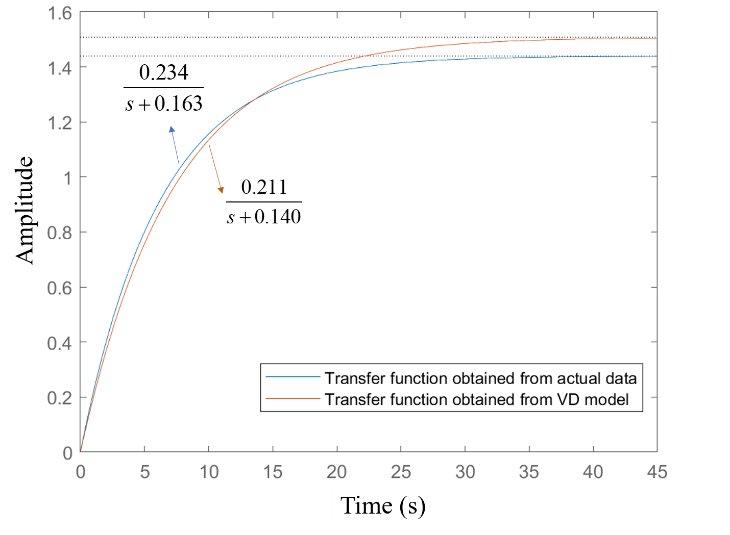
图4 pH值对q2的传递函数和阶跃响应曲线
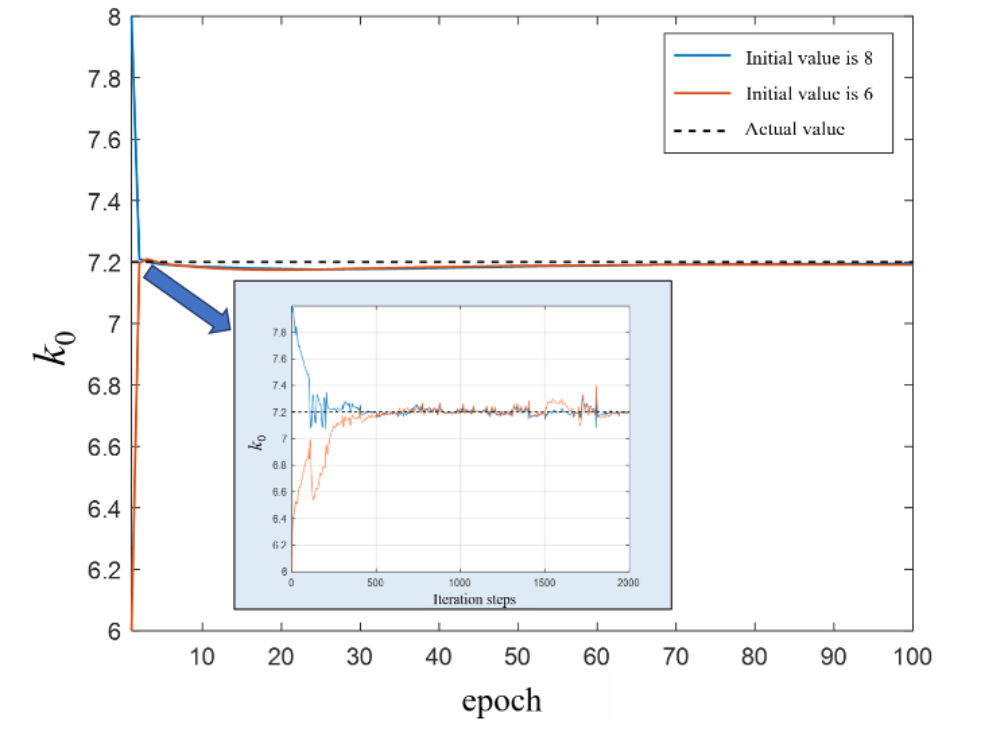
图5 CSTR过程参数k0估计曲线
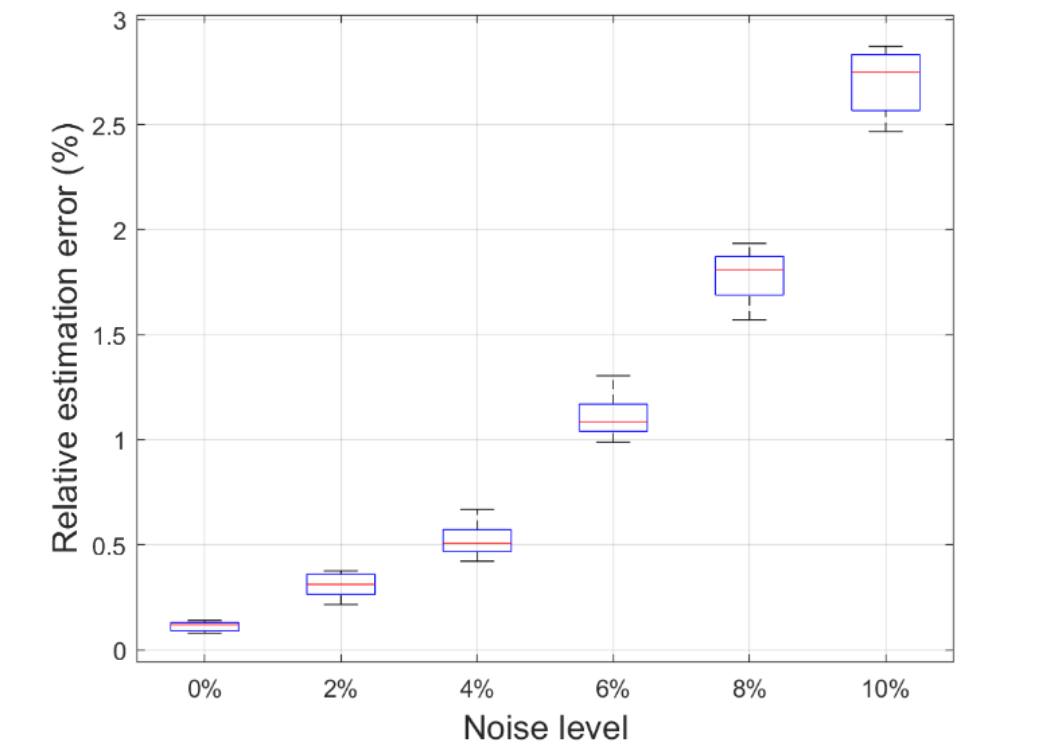
图6 CSTR过程不同测量噪声下参数k0估计精度
表2 不同测量噪声下的模型训练和测试结果
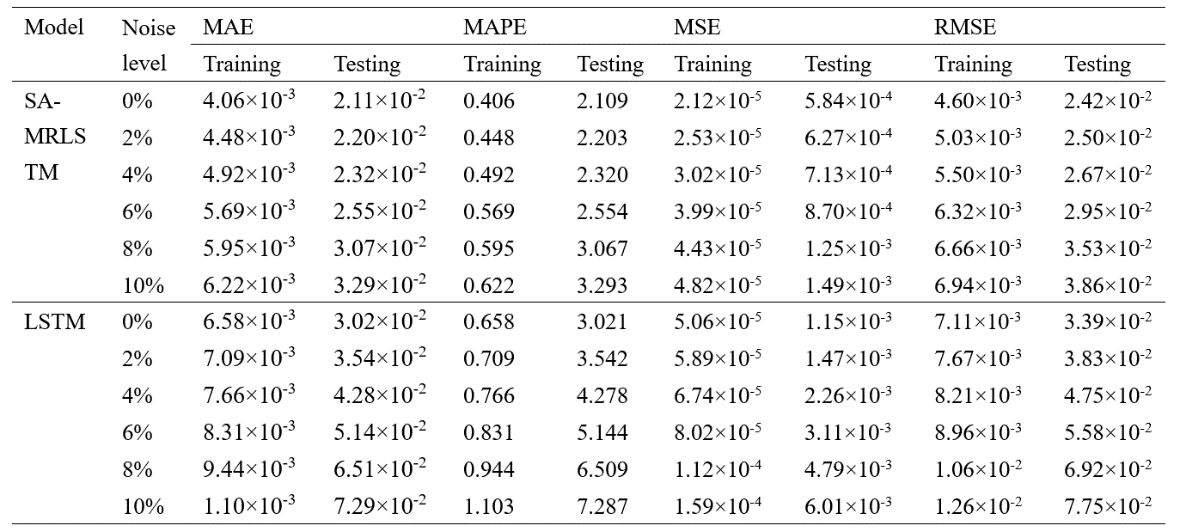
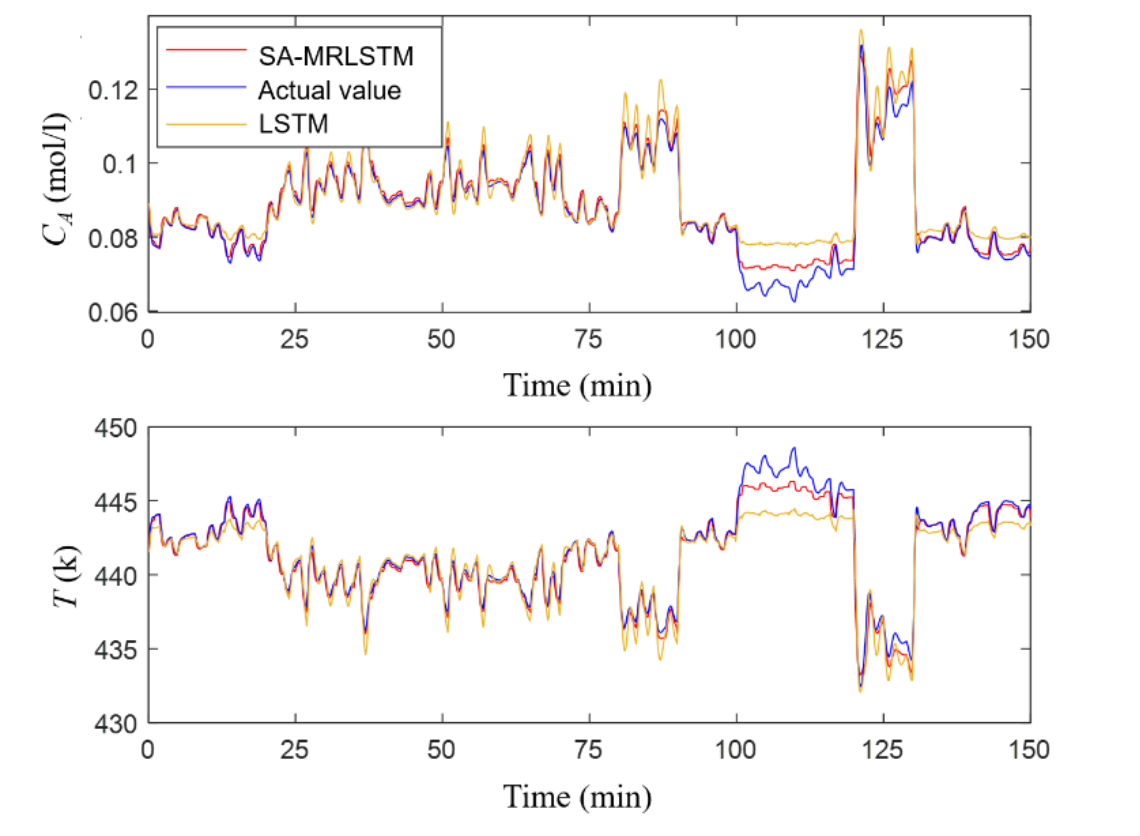
图7 CSTR过程LSTM和SA-MRLSTM泛化能力测试结果
考虑到化学过程的复杂性和传统辨识方法的局限性,本文提出了一种基于SA-MRLSTM的结合机理和过程数据的化工过程动态模型辨识方法。为了在训练数据的信息不充分时获得准确的模型,引入微分方程作为正则化项来约束神经网络的输出,迫使网络满足微分方程描述的物理或化学机理。在训练过程中,将自适应权值引入损失函数,通过最小化损失和最大化自适应权值来训练神经网络,以获得更好的拟合结果。此外,还讨论了当机理方程中存在未知参数时,神经网络的训练和参数估计方法。VD模型使用初始条件和MV作为模型输入,可以有效地获得先进控制器所需的传递函数模型,避免辨识实验对实际生产过程的干扰。在pH中和与CSTR过程上的实验结果表明,SA-MRLSTM网络适用于化工过程辨识,具有较强的鲁棒性和泛化能力。
徐宝昌,副教授,博士生导师/硕士生导师。长期从事复杂系统的建模与先进控制;钻井过程自动控制技术;井下信号的测量与处理;多传感器信息融合与软测量技术等方面的研究工作。现为中国石油学会会员,中国化工学会信息技术应用专业委员会委员。曾参与多项国家级、省部级科研课题的科研工作,并在国内外核心刊物发表了论文70余篇;其中被SCI、EI、ISTP收录30余篇。