
基于类内类间优化元学习的小样本故障诊断
中文题目:基于类内类间优化元学习的小样本故障诊断
论文题目:Meta-Learning With Intraclass and Interclass Optimization for Few-Shot Fault Diagnosis
录用期刊/会议:IEEE Transactions on Industrial Informatics (中科院大类1区,CAA A+类期刊)
原文DOI:10.1109/TII.2024.3458091
原文链接:https://ieeexplore.ieee.org/abstract/document/10704056
录用/见刊时间:2024年
作者列表:
1)李 康 中国石油大学(北京)人工智能学院 自动化系教师
2)叶 昊 清华大学 信息科学技术学院 自动化系教师
3)高小永 中国石油大学(北京)人工智能学院 自动化系教师
4)张来斌 中国石油大学(北京)安全与海洋工程学院 安全工程系教师
摘要:
本文提出了一种类内类间优化元学习(Meta-Learning with Intraclass and Interclass Optimization)方法,旨在解决小样本工业系统故障诊断问题。所提MLIIO通过设计类内聚集损失(IAL)和类间判别损失 (IDL),优化了特征空间中同类样本的紧凑性和异类样本的分离度。IAL通过拉近样本与其类别中心的距离来增强类内紧凑性,而IDL则通过最大化不同类别间的距离来提升类间可分性。该方法采用情景训练机制,通过多个辅助任务来训练模型,使其能够快速适应新任务。在公开的滚动轴承数据集和实际的铁路转辙机数据集上进行的实验表明,MLIIO在小样本故障诊断任务上优于多种代表性方法,具有更好的泛化能力和诊断性能。这项研究为工业设备的安全和可靠运行提供了一种有效的智能诊断工具。
背景与动机:
随着工业自动化和信息化的快速发展,故障诊断技术对于保障工业系统安全、可靠运行至关重要。然而,在实际工业应用中,由于故障发生的低频性和采集难度,收集到的故障数据往往十分有限,这限制了传统数据驱动方法的应用。针对这一挑战,本文提出了一种类内类间优化元学习方法,旨在利用有限的故障数据训练出有效的故障分类器。MLIIO通过优化类内聚集损失和类间判别损失,增强了特征空间中同类样本的紧凑性和异类样本的分离度,从而提升了模型的泛化能力。这种方法不仅能够应对数据稀缺的问题,还能适应新的故障场景,对于提高工业系统的智能化水平具有重要意义。
设计与实现:
本文提出MLIIO方法通过结合类内聚集损失(IAL)和类间判别损失(IDL)来优化模型的特征学习过程。IAL负责拉近同一类别内样本特征与类别中心的距离,以增强类内的紧凑性,而IDL则通过最大化不同类别间的距离来提升类间的可分性。MLIIO采用了情景训练机制,每个episode由支撑集和查询集组成,其中支撑集用于生成类别原型,查询集用于评估模型性能。在每个episode中,模型通过最小化综合损失函数来更新参数,该损失函数是IAL和IDL的加权和,其中权重系数λ用于平衡两个损失函数的贡献。这种方法使得模型能够在有限的样本下快速适应新任务,提升了模型对新故障场景的识别能力。在实验部分,选择了公开的滚动轴承数据集和实际的铁路转辙机数据集来验证MLIIO方法的有效性,并通过与多种代表性方法比较,证明了MLIIO在小样本故障诊断任务上具有优越的性能。该方法不仅有助于解决实际工业应用中的样本稀缺问题,也提高了故障诊断的准确性和鲁棒性。
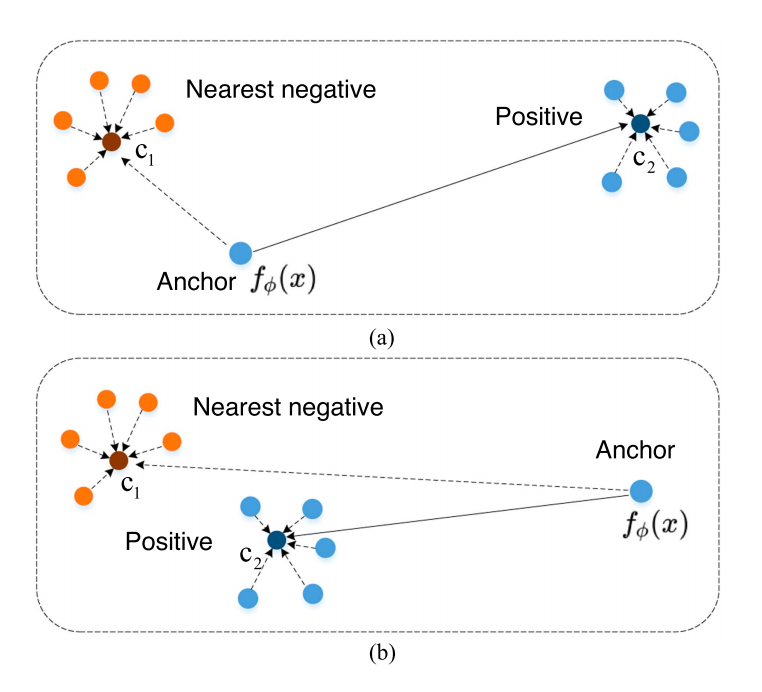
图1 小样本故障诊断典型优化场景
如上图所示,上图a中,锚点样本与其对应的正样本之间的距离比最近的负样本之间的距离更近,这种情况是容易处理的情况。但是在图b中,尽管与正样本之间的距离更近,但是距离却很远这种情况下,模型可能难以准确学习到类别之间的区分边界,因为锚点样本的特征表示可能不如其类别原型那样具有代表性。因此,本文提出MILO方法,结合IAL和IDL两个关键损失函数优化模型的训练过程,最终学习到一个具有更好泛化性的模型。
主要内容:
一、类间判别损失(Interclass Discriminative Loss)
类间判别损失旨在使得每个类别内部的样本特征尽可能靠近该类别的原型,同时确保不同类别的原型之间的距离足够大,以此来提高模型在特征空间中的分类能力。
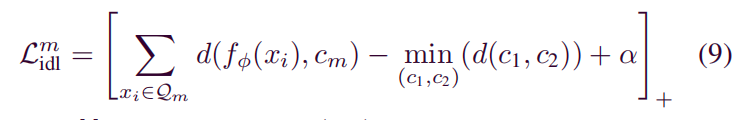
上方类间判别损失的计算方法是将锚点样本的特征表示到类别原型的距离减去最小类间距离,并加上一个强迫的边界。
![]()
然后对每个类的损失函数求和得到总类间判别损失,通过最小化总类间判别损失,使得模型在样本有限的情况下,也能学习到具有较好区分度的特征表示。
二、类内聚集损失(Intraclass Aggregation Loss)
类内聚集损失旨在提高同一类别样本特征的聚合,使得同一类别的样本在特征空间中更加紧凑,减少样本特征与其对应类别原型之间的距离,从而增强同一类别内样本的相似性。
![]()
上方类内聚集损失的计算方法是对查询集中每个样本的特征表示与其原型之间的距离求平均,此平均值反映了类内样本特征与其原型之间的紧密程度。
然后对每个类的损失函数求和得到总类内聚集损失,通过最小化总类内聚集损失将有助于将同一类别的样本特征拉向它们的中心原型,在特征空间中形成更加紧凑的类别簇。最终提高模型泛化能力。
三、基于MLIIO的小样本故障诊断流程
在训练阶段,根据总损失函数采用情景训练方式学习MLIIO模型。
![]()
在测试阶段,利用新类故障样本的支撑集对模型进行微调,然后测试询问集样本的故障类型。
![]()
实验结果及分析:
一、CWRU数据集
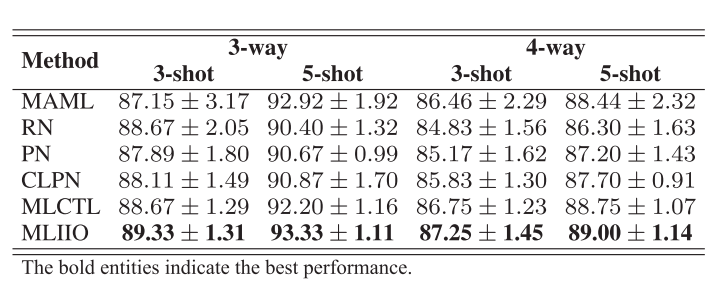
为验证所提方法的有效性,在公开CWRU轴承数据集上对比了多种代表性方法(MAML、RN、PN、CLPN和MLCTL),结果表明所提出的元学习方法在小样本故障诊断的平均诊断精度方面更加出色。在3-way 5-shot设置下,所有方法的平均诊断准确率超过了90%,这表明即使在样本数量有限的情况下,MLIIO方法也能学习到有效的特征表示。在其他设置下,平均准确率也大多在80%到90%之间,显示了该方法在少样本学习问题上的鲁棒性。
表1 不同方法采用不同设置时的故障诊断对比结果
从表2中可以看出,MLIIO方法在变工况场景下都能保持较高的诊断准确率,表明该方法具有良好的泛化能力。

表2 变工况场景下不同方法采用不同设置时的故障诊断对比结果
此外,图2给出了 t-SNE特征可视化结果,表明MLIIO方法具有更好的特征判别能力,也验证了类内聚集损失和类间判别损失的有效性。

图2 不同方法所学特征的t-SNE可视化效果. (a) MAML. (b) RN. (c) PN. (d) CLPN. (e) MLCTL.(f) MLIIO.
二、高铁道岔转辙机数据集
高铁道岔转辙机电流数据集记录了108 S700K型道岔转换设备的三相电流数据,每个样本由三相电流数据组成,每个相位包含120-150个采样点,采样频率为25 Hz,为了确保输入样本具有统一的维度,较短的曲线被零填充至200个采样点,三相电流数据被连接起来形成一个600维的输入样本。类似地,我们对比了所提MLIIO方法与5种代表性方法的故障诊断表现。如表3所示,相较于代表性方法,MLIIO方法的平均故障诊断准确率更高,性能更优。
表3 不同方法采用不同设置时的故障诊断对比结果

结论:
本论文提出了一种类内类间优化元学习方法,旨在解决实际工业应用中因数据稀缺而导致的故障诊断难题。通过在类内聚集损失和类间判别损失的联合优化下,所提方法能够有效地学习区分不同故障类别的特征表示,即便在样本数量有限的情况下也表现出色。在CWRU轴承数据集和高速铁路道岔数据集上的实验结果表明,MLIIO方法在多种少样本故障诊断场景下均优于代表性方法,这些结果不仅证明了MLIIO在不同工作条件下的泛化能力,也展示了其在跨场景故障诊断中的稳定性和可靠性。此外,通过t-SNE特征可视化和混淆矩阵分析,进一步验证了MLIIO在提高故障诊断准确性和区分容易混淆故障类型方面的优势。
MLIIO方法为少样本故障诊断领域提供了一种有效的解决方案,尤其适用于工业场景中数据难以获取的情况。未来的工作将集中在设计更精细的机制来处理难以诊断的故障类型,并尝试将过程机制知识融入模型训练中,以减少对大量高质量支撑集的依赖,进一步提升模型的诊断性能。这项研究不仅推动了故障诊断技术的发展,也为工业智能化和预测性维护提供了有力的技术支持。
作者简介:
李康,师资博士后,博士,中国石油大学(北京)人工智能学院自动化系教师,主要研究方向为故障诊断与容错控制。