
面向边缘计算推荐系统的联邦学习激励机制设计
中文题目:面向边缘计算推荐系统的联邦学习激励机制设计
论文题目:Incentive Mechanism Design of Federated Learning for Recommendation Systems in MEC
录用期刊/会议:IEEE Transactions on Consumer Electronics (中科院大类2区,JCR Q2)
原文DOI:10.1109/TCE.2023.3342187
原文链接:https://ieeexplore.ieee.org/abstract/document/10356897
录用/见刊时间:2023-12-13
作者列表:
1)黄霁崴 中国石油大学(北京)信息科学与工程学院/人工智能学院 教授
2)马博闻 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
3)王 名 中国联通 工程师
4)Xiaokang Zhou Shiga University Faculty of Data Science Associate Professor
5)Lina Yao CSIRO's Data61 Senior Principal Research Scientist
6)Shoujin Wang University of Technology Sydney Data Science Institute Lecturer
7)齐连永 中国石油大学(华东)计算机科学与技术学院 教授
8)陈 莹 北京信息科技大学 计算机学院 教授
摘要:
随着消费电子产品和通信技术的快速发展,网络边缘的终端用户产生了大量数据,现代推荐系统充分利用这些数据来训练各种人工智模型。然而,传统的集中式模型训练必须将所有数据传输到云端服务器,存在隐私泄露和资源短缺的问题。因此,移动边缘计算(MEC)与联邦学习相结合被认为是解决这些问题的一种有前途的模式。智能设备可以为联邦学习提供数据和计算资源,并将本地模型参数传输到配备边缘服务器的基站,以聚合成一个全局模型。然而,由于物理资源有限和隐私泄露的风险,用户并不愿意自愿参与联邦学习。为解决这一问题,本文利用博弈论提出了一种基于两阶段Stackelberg博弈的激励机制,以激励用户为联邦学习贡献计算资源。本文为用户和基站定义了两个效用函数,并提出了效用最大化问题。通过理论分析,得到了用户的纳什均衡策略和效用最大化问题的Stackelberg均衡。此外,本文还提出了一种基于博弈的激励机制算法(GIMA)来实现Stackelberg均衡。最后,本文提供了仿真结果来验证GIMA算法的性能。实验结果表明,与其他激励方法相比,本文提出的算法收敛速度快,能获得更高的效用值。
背景与动机:
在本文中,为了激励用户贡献更多计算资源以提高联邦学习模型的性能,本文利用博弈论将基站和用户之间的联邦学习培训建模为一个两阶段的Stackelberg博弈,其中基站是领导者,用户是追随者。配备服务器的基站发起联邦学习任务并支付费用。基站覆盖范围内的用户通过贡献计算资源和本地数据样本参与联邦学习。基站和用户的目标是最大化各自的效用。本文从理论上分析了效用最大化问题的Stackelberg均衡的存在性,并提出了一种基于博弈的激励机制算法(GIMA)来解决用户和基站的效用最大化问题。
主要内容:
本文考虑蜂窝网络环境下推荐系统的典型联邦学习场景,如图1所示。它由一个带有边缘服务器的基站和多个用户组成。每个用户使用本地原始数据训练自己的本地推荐模型。然后,只将局部模型的参数上传到边缘服务器进行聚合,即可获得全局模型。最后,聚合的全局模型被发送回用户设备进行推理和下一次迭代训练。
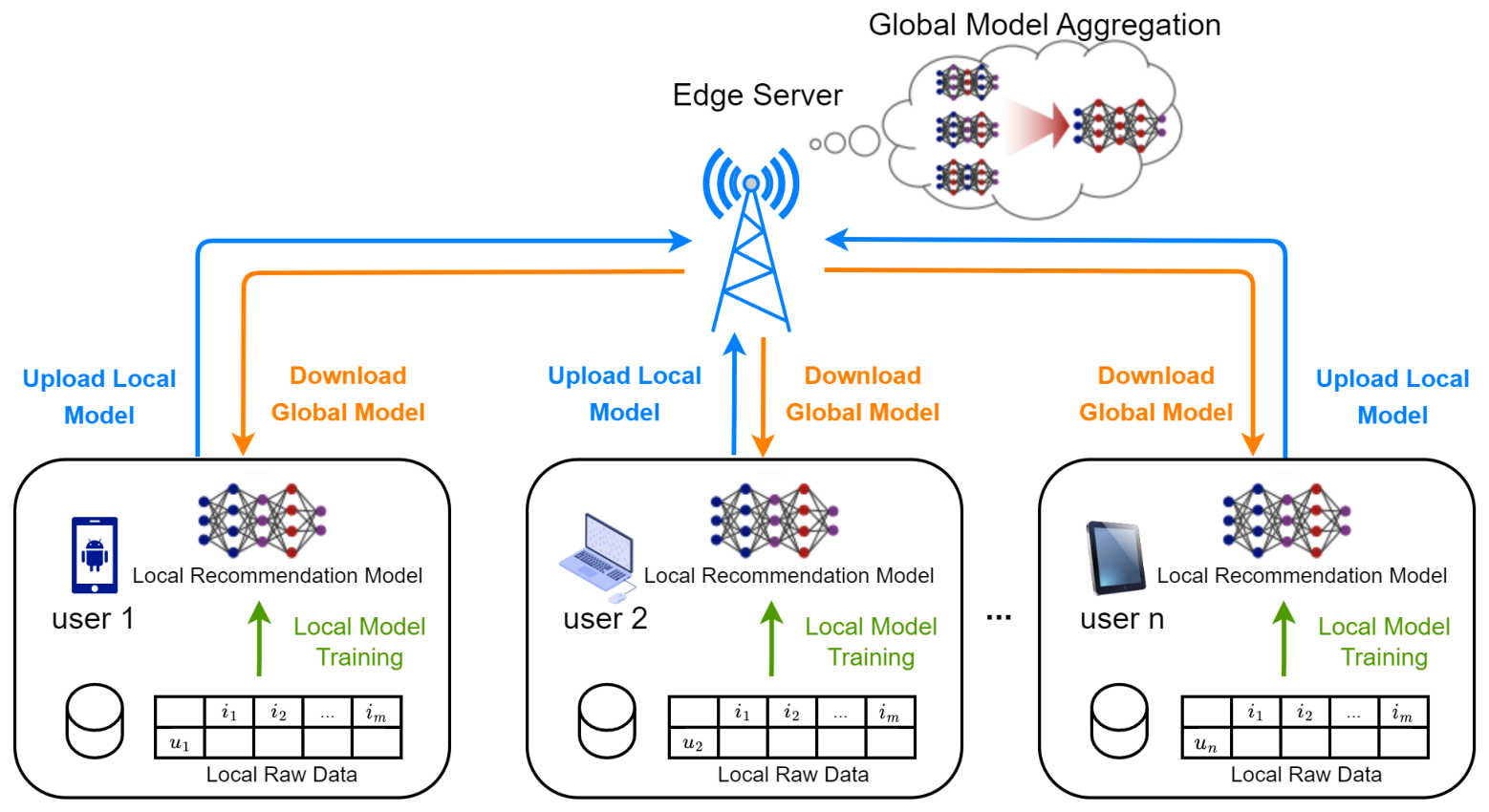
图1 MEC中推荐系统的联邦学习系统模型
本文定义了基站和用户的效用函数,随后提出两阶段Stackelberg博弈框架来捕获参与联邦学习的各方之间的复杂互动。基站需要决定一个适当的激励方式来吸引用户参与,以获得高质量的模型。用户需要决定他们的参与程度,以最大化他们的效用。因此,优化问题可表示为
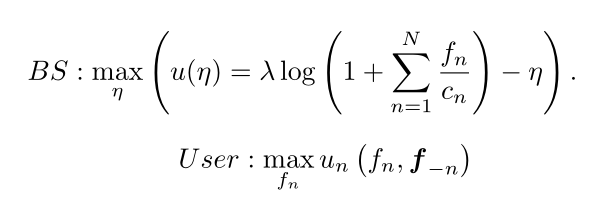
随后证明了纳什均衡的存在性以及Stackelberg均衡的存在,并且提出了一种基于博弈的激励机制算法(GIMA)来实现Stackelberg均衡,算法伪代码如下所示:

实验结果及分析:
从图2可以看出,基站和用户存在唯一的Stackelberg均衡策略。为了验证唯一Stackelberg均衡的存在性,在用户数量和用户策略固定的情况下,将支付从0变化到50。基站的效用曲线呈凸形,曲线最高点为Stackelberg均衡的最佳响应。本文还验证了用户间的唯一纳什均衡,对于每个用户根据其他用户和基站支付的固定策略改变频率。值得注意的是,每个用户的效用曲线都是凸的。在这种情况下,用户可以通过确定计算资源的策略来最大化效用。
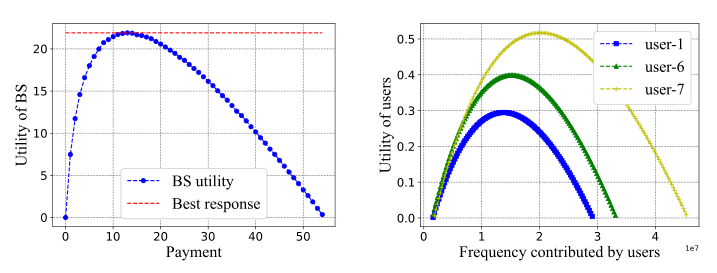
图2 纳什均衡及Stackelberg均衡
图3显示了基站和用户的效用变化情,展示了不同用户数下Random算法、GIMA算法和Fix算法效用。本文提出的的GIMA算法的基站效用是三种算法中最大的。随着用户数量的增加,GIMA算法与其他两种算法之间的效用差距越来越大。此外,GIMA算法的增长速度比线性增长慢。实际上,随着用户数量的进一步增加,越来越多的用户参与到联邦学习训练中,基站可以获得大量的计算资源。但是,为了获得最大的效用,基站所需的计算资源量会趋于稳定。此外,随着用户数量的增加,用户的平均效用减少。这是因为随着用户数量的增加,参与联邦学习训练的用户越来越多,而奖励的增长速度却持平。因此,用户的平均效用变小。可以明显看出,GIMA算法的基站效用是三种算法中最大的,GIMA算法与另外两种算法的用户平均效用差距越来越大。
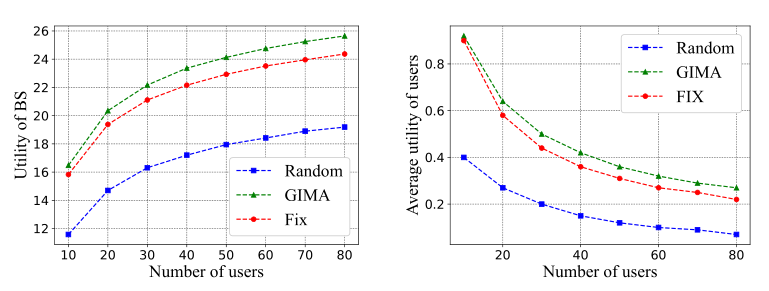
图3 不同用户数量下的基站效用及用户平均效用
结论:
本文研究了一种与联邦学习合作的MEC系统,用于基站覆盖范围内的推荐系统。基站有偿发布联邦学习任务,用户通过贡献计算资源和本地数据竞争获利。本文为用户和基站设计了两个效用函数,还将效用最大化问题表述为两阶段Stackelberg博弈,并从理论上证明了Stackelberg均衡的存在。然后,本文提出了GIMA算法,以在有限的迭代次数内获得用户和基站的均衡策略。通过模拟实验说明,与其他激励方法相比,GIMA算法能快速收敛并获得更高的效用值。在今后的工作中,我们将考虑数据新鲜度的影响,鼓励用户提供新鲜数据,以训练出更精确的模型。我们将进一步考虑数据样本不足的问题,并研究联邦学习的自适应激励机制框架。此外,我们还将从经济学角度探索各种激励机制设计方法,如反向拍卖等。
通讯作者简介:
黄霁崴,教授,博士生导师,中国石油大学(北京)信息科学与工程学院/人工智能学院副院长,石油数据挖掘北京市重点实验室主任。入选北京市优秀人才、北京市科技新星、北京市国家治理青年人才、昌聚工程青年人才、中国石油大学(北京)优秀青年学者。本科和博士毕业于清华大学计算机科学与技术系,美国佐治亚理工学院联合培养博士生。研究方向包括:物联网、服务计算、边缘智能等。已主持国家自然科学基金、国家重点研发计划、北京市自然科学基金等科研项目18项;以第一/通讯作者在国内外著名期刊和会议发表学术论文60余篇,其中1篇获得中国科协优秀论文奖,2篇入选ESI热点论文,4篇入选ESI高被引论文;出版学术专著1部;获得国家发明专利6项、软件著作权4项;获得中国通信学会科学技术一等奖1项、中国产学研合作创新成果一等奖1项、广东省计算机学会科学技术二等奖1项。担任中国计算机学会(CCF)服务计算专委会委员、秘书,CCF和IEEE高级会员,电子学报、Chinese Journal of Electronics、Scientific Programming等期刊编委。