
别再使用黑箱模型--可解释人工智能在钻速预测的应用
中文题目:别再使用黑箱模型--可解释人工智能在钻速预测的应用
论文题目: Stop Using Black-box Models: Application of Explainable Artificial Intelligence for Rate of Penetration Prediction
录用期刊/会议:SPE Journal (中科院大类3区)
原文DOI:https://doi.org/10.2118/223622-PA
原文链接:https://onepetro.org/SJ/article-abstract/doi/10.2118/223622-PA/580238/Stop-Using-Black-Box-Models-Application-of?redirectedFrom=fulltext
录用/见刊时间:October 23 2024
作者列表:
1)孟 翰 中国石油大学(北京)人工智能学院 智能科学与技术系教师
2)林伯韬 中国石油大学(北京)人工智能学院 智能科学与技术系教师
3)金 衍 中国石油大学(北京)石油工程学院 油气井工程系教师
文章简介:
机械钻速预测对提高钻井效率、降低钻井成本至关重要。现有人工智能模型虽然在预测精度上表现出色,但其黑盒特性限制了实际应用。本文引入了一种基于神经网络的可解释钻速预测模型,不仅保持了高预测精度,还能清晰展示钻井参数对预测结果的影响机制,旨在促进可解释人工智能在油气领域的应用。
摘要:
准确预测钻速对提高钻井效率和降低钻井成本至关重要。目前的人工智能模型虽然能够准确预测钻速,但其黑箱模型的本质,导致其决策过程难以理解,在实际应用中受到限制。本研究引入的可解释神经网络模型不仅能准确预测钻速,还能清晰展示各项钻井参数是如何影响预测结果的。通过公开数据集的对比实验,该模型展现出优异的预测性能,不仅预测精度高,并且能够提供清晰的决策依据。
背景与动机:
机械钻速的预测直接关系到钻井效率优化和总体成本控制。目前ROP预测模型主要分为三类:物理模型、数据驱动模型和混合模型。物理模型虽然具有良好的解释性,但由于其建立在实验室条件下,难以准确刻画实际钻井过程中的复杂非线性关系。数据驱动模型特别是深度学习模型虽然预测精度较高,但其黑盒特性阻碍了在高风险的石油工业中的实际应用。混合模型试图结合两者优势,但其假设的物理规律在不同地层条件下的普适性存疑,且其数据驱动部分仍存在解释性问题。因此,开发一种既能保持数据驱动模型灵活性又具备清晰解释能力的ROP预测模型具有重要意义。本研究提出将可解释人工智能引入ROP预测中,旨在打开石油工程领域AI应用的新途径。
设计与实现:
方法设计:
1. 模型架构设计:本文采用基于广义加性模型的NBM(Neural Basis Model),其核心创新在于通过共享神经网络学习基函数。模型结构主要包含三个关键组件:
l基函数学习网络:采用共享神经网络处理输入特征,学习一组基函数来捕捉特征间的关联性
l特征映射层:通过特定权重组合基函数,构建每个输入特征的贡献函数
l线性组合层:将各特征贡献进行线性组合得到最终预测结果
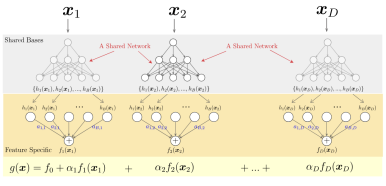
图1 NBM 网络结构
主要创新点包括如下三点:
l共享网络设计提高了对特征间相关性的捕捉能力
l基函数的学习机制提供了稳定的模型解释性
l并行训练架构显著提升了计算效率
数据集合与预处理方法:
数据集描述:
本研究基于Tunkiel等人处理和清洗的挪威Volve油田的公开钻井数据集,一共有7口井数据。共包含198,928个数据点,每个数据点包含12个特征:测量深度(MD)、钻压(WoB)、立管压力(ASP)、地面扭矩(AST)、转速(ARS)、泥浆流量(MFI)、泥浆密度(MDI)、钻头直径(D)、平均吊重(AH)、井深(HD)、伽马值(Gamma)和机械钻速(ROP)。
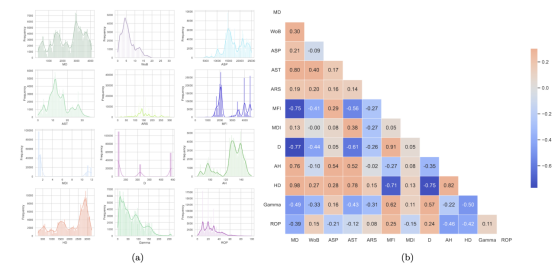
图2 数据集特征分布和相关性分析
数据集划分:
本研究设计了连续学习和全井预测两种训练场景,以模拟实际钻井作业中的不同应用需求。
连续学习:旨在模拟单井钻进过程中的实时优化,初始使用前90米数据(前30米训练,中间30米验证,最后30米测试)建立基础模型,并随着钻井深度每增加30米(约一个钻杆长度)就更新一次模型,这种设计特别适用于指导同一口井后续井段的钻进参数优化。
全井预测:则模拟利用已钻井的经验来指导新井钻进的情况,从7口井中选择1口作为测试井,1口作为验证井,其余井的数据用于训练,采用滚动选择方法确定验证井和测试井,这种设计适用于油田开发后期利用已积累的钻井经验指导新井的钻进策略。
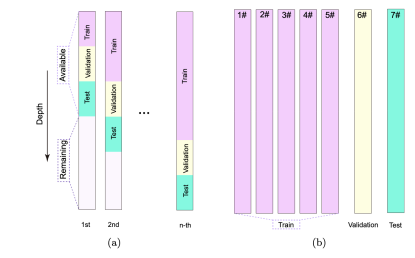
图3 (a)连续学习 和(b)全井预测的数据集划分
可解释ROP预测:
可解释模型的一个重要优势在于其能够为预测结果提供清晰的解释,这种解释能力体现在对预测结果的可视化上。图4展示了使用Well-1钻井数据训练的模型结果。图中红线表示每个输入特征所对应的学习函数。蓝点代表一个具体输入样本的参数:测量深度1187.98米,钻压13.42 kkgf,立管压力10967.83 kPa,地面扭矩9.56 KN.m,转速194.19 rpm,泥浆流量1927.46 L/min,泥浆密度1.20 g/cm³,钻头直径215.90 mm,吊重86.43 kkgf,伽马值25.37 gAPI。图中标注了各学习子函数与其对应系数相乘后的值。模型对该输入的最终预测值由这些值的相加得出得出,具体为41.285 m/h(包含学习到的常数项f₀=0.245)。
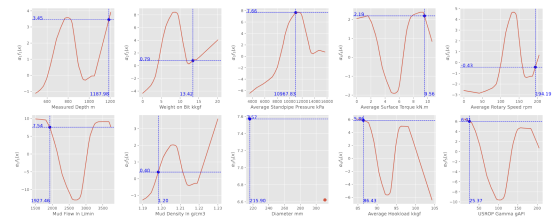
图4 模型预测可视化
关于连续学习和全井段预测的讨论
研究结果表明,NBM模型在连续学习场景下的预测性能显著优于全井预测场景,这个现象值得深入探讨。这种性能差异主要反映了数据驱动模型在知识迁移方面的局限性。在连续学习场景中,由于是在同一口井的数据上进行训练和预测,模型能够有效捕捉到该井特定的钻井参数与机械钻速之间的关系模式。这些关系模式在同一口井的不同深度区间表现出较好的一致性,这与地层的连续性特征相符。然而,当模型应用于多井情况下的全井预测场景时,虽然钻井操作参数(如钻压、转速等)的数值范围可能相似,但可能是因为由于缺乏详细的地层特征信息,模型难以准确理解不同井之间的地质差异对机械钻速的影响,学习到的知识完全不同。这也说明了当前模型学习到的更多是数据集特定的解释(dataset-specific explanations),而非可迁移知识(transferable knowledge)。这一认识对未来研究具有重要指导意义:要提高模型在不同井之间的预测能力,需要补充更多地层特征信息,以帮助模型建立起更本质的物理关联,而不是仅仅停留在表面的数据相关性层面。
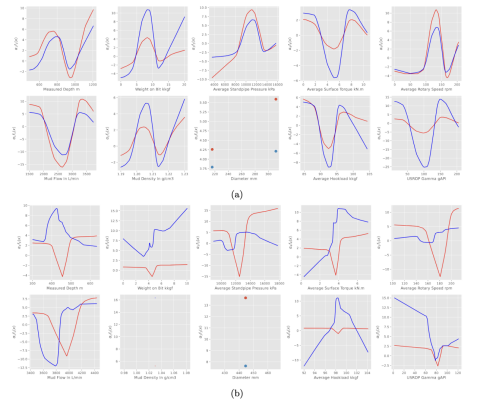
图5 (a)well-1 和(b)well-2 井上的数据训练得到的模型的可视化解释
结论:
本研究采用了自解释神经网络模型构建机械钻速预测。通过与已有方法的对比实验表明,采用的模型不仅达到了与黑箱模型相当的预测精度,更重要的是具备了清晰的可解释性,能够增强用户对预测结果的信任度并提供更深层的洞察。本研究的更广泛意义在于为石油工程领域引入可解释AI模型提供了示范。
代码:
本研究的部分代码可从https://github.com/IPE-lab/NBMROP获取。
作者简介:
孟翰,中国石油大学(北京)人工智能学院副教授。本科和硕士毕业于中国石油大学(北京),分别获得石油工程和油气井工程学位,于英国诺丁汉大学获得计算机科学博士学位。2024年加入中国石油大学(北京)人工智能学院。研究方向包括可解释人工智能、生成式模型、时间序列分析等。
通讯作者简介:
林伯韬,人工智能学院教授,博士生导师,长期致力于智能石油工程与工业数字孪生等领域的教学和科研工作。
金衍,石油工程学院教授,博士生导师,长期致力于岩石力学、智能油田、井壁稳定和水力压裂等油气井工程领域方面的教学和科研工作,国家杰出青年科学基金获得者。