
SEGAL时间序列分类 - 基于生成模型与自适应加权的稳定LIME解释方法
中文题目:SEGAL时间序列分类 - 基于生成模型与自适应加权的稳定LIME解释方法
论文题目:SEGAL time series classification — Stable explanations using a generative model and an adaptive weighting method for LIME
录用期刊/会议:Neural Networks(中科院大类1区 TOP)
原文DOI:10.1016/j.neunet.2024.106345
原文链接:https://www.sciencedirect.com/science/article/pii/S0893608024002697?via%3Dihub
录用/见刊时间:May 10 2024
作者列表:
1)孟 翰 中国石油大学(北京)人工智能学院 智能科学与技术系教师
2)Christian Wagner 英国诺丁汉大学 计算机科学学院 教授
3)Isaac Triguero 英国诺丁汉大学 计算机科学学院 副教授
文章简介:
在复杂系统的多变量时间序列分类任务中,深度学习模型展现了强大的性能,但其“黑箱”特性限制了模型在关键领域中的应用。LIME(Local Interpretability Model-agnostic Explanation)是一个强大的解释黑箱模型解释器,但是其在解释时间序列问题时经常产生不稳定的解释。为解决这一问题,本研究提出了一种基于生成模型的LIME解释框架,利用生成式模型生成分布内的邻居样本,并引入自适应加权方法以提高解释的稳定性。通过在对多个真实数据集的实验表明本方法显著提升了解释的稳定性。
摘要:
LIME是一种广泛使用的事后解释方法,用于解释黑盒模型。但是最近的研究表明LIME提供的解释面临不稳定的挑战,提供的解释不可重复,这让人对其可靠性产生怀疑。本文研究了 LIME 在应用于多变量时间序列分类问题时的稳定性。研究表明,LIME 中使用的传统邻居生成方法存在创建“假”邻居的风险,这些邻居与训练模型不符,并且远离要解释的输入。由于时间序列数据具有很大的时间依赖性,这种风险尤其明显。我们讨论了这些不符分布的邻居如何导致不稳定的解释。此外,LIME 根据用户定义的超参数对邻居进行加权,这些超参数依赖于问题并且难以调整。我们展示了不合适的超参数如何影响解释的稳定性。我们提出了一种双重方法来解决这些问题。首先,使用生成模型来近似训练数据集的分布,从中可以为 LIME 创建分布内样本,从而创建有意义的邻居。其次,设计了一种自适应加权方法,其中的超参数比传统方法更容易调整。在真实数据集上的实验证明了该方法的有效性,它能够使 LIME 框架提供更稳定的解释。此外,本文还深入讨论了这些结果背后的原因。
背景与动机:
多变量时间序列分类(MTSC)在网络安全异常检测和医疗健康监控等领域有广泛应用。近年来,深度学习在MTSC任务中表现出色,广泛应用于各种场景。然而,深度学习模型作为黑箱模型,缺乏足够的可解释性,严重限制了其在需要可靠解释的关键领域中的应用。
为了应对这一挑战,诸如LIME等方法被广泛用于解释复杂的深度学习模型。然而,LIME方法在多次运行中可能产生不稳定的解释。稳定性对于解释方法至关重要,因为不稳定的解释会使模型用户对其可靠性产生怀疑。虽然已有研究尝试通过增加样本数量、改进采样方法或优化超参数来提升LIME的稳定性,但这些方法忽略了生成样本时未考虑训练数据的分布,从而可能生成超出分布的样本,从而导致了解释结果不稳定的问题。
为了解决上述问题,本文提出了一种基于生成式模型的LIME解释框架,利用Transformer生成符合训练数据分布的样本,并引入自适应加权方法,以优化解释的稳定性。与现有工作相比,该方法在生成高质量样本和提升解释稳定性方面取得了显著进展。本文的动机在于通过解决生成超出分布样本的问题,提升LIME在多变量时间序列数据上的应用效果,进而提高机器学习模型的可解释性。
设计与实现:
本文提出了一种名为 SEGAL(基于生成模型和自适应加权的LIME稳定解释方法)解释方法,旨在提高LIME在解释MTS)任务中的稳定性。SEGAL主要解决两个关键问题:(1) 生成遵循训练数据分布的邻居样本,使其更加真实和有意义;(2) 优化LIME框架中的超参数,降低超参数优化的复杂度。
为了解决第一个问题,SEGAL引入了一种基于Transformer架构的生成模型,用于生成符合训练数据分布的邻居样本。这些样本真实地反映了模型的学习内容,从而为解释提供了有意义的邻居样本。
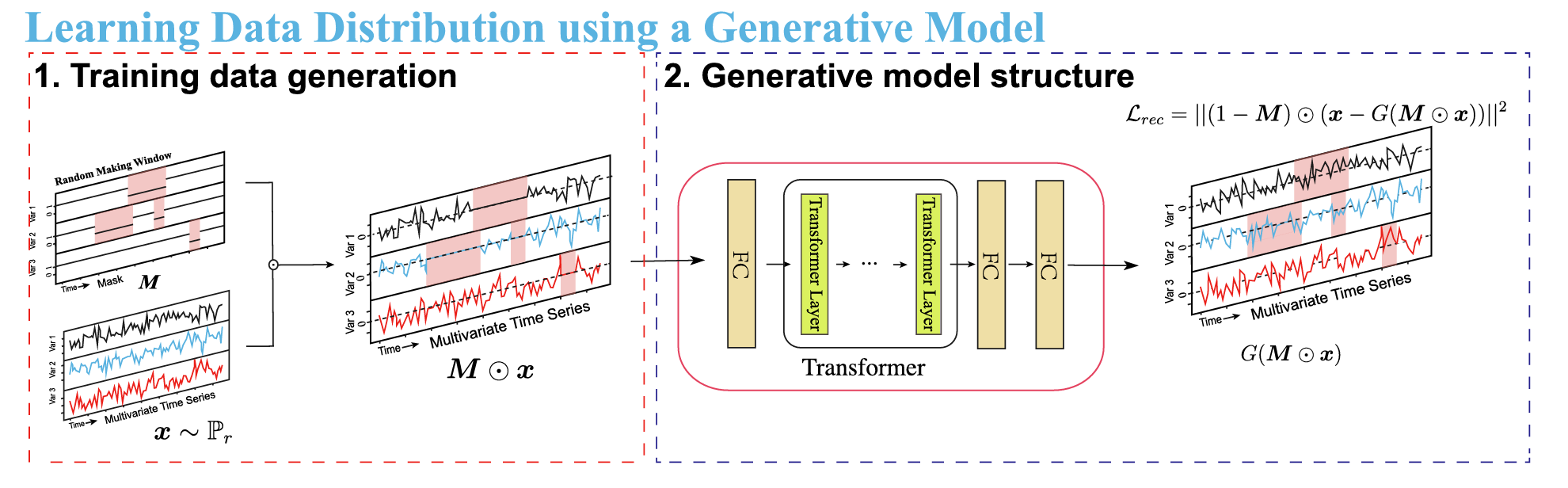
图1 基于Transformer的邻居样本生成方法
针对第二个问题,SEGAL提出了一种自适应加权方法,根据邻居样本与目标样本的距离动态调整加权方式,从而提升解释过程的可靠性。
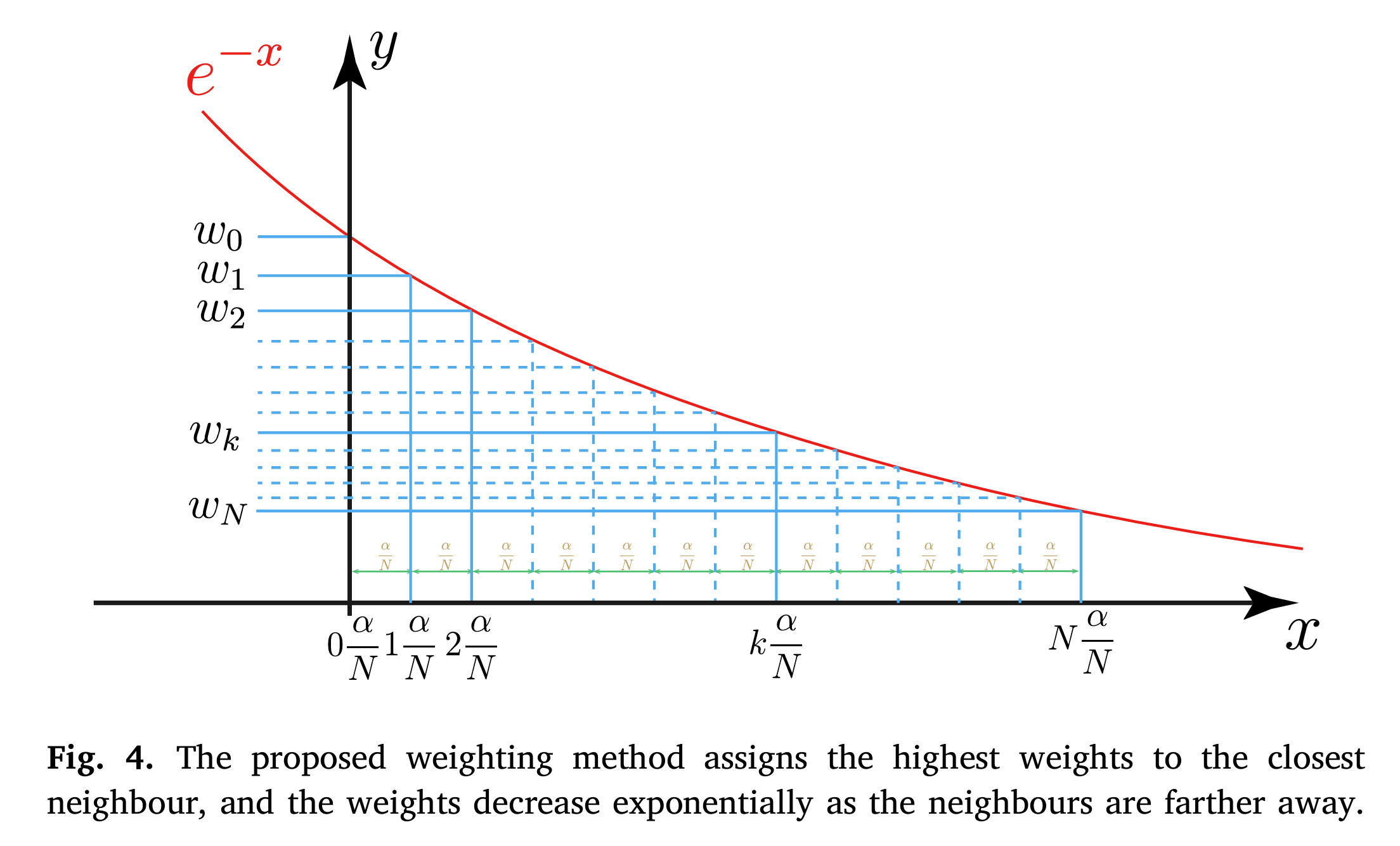
图2 自适应加权方法
SEGAL的工作流程如下:
1. 使用训练数据训练分类器和生成模型。
2. 利用生成模型为目标输入生成邻居样本。
3. 使用训练好的分类器对生成的邻居样本进行预测。
4. 采用自适应加权方法,根据邻居与目标样本的距离对样本进行加权。
5. 在加权后的数据上拟合可解释模型,生成最终的解释结果。
方法实现:
1. 使用生成模型和局部采样生成邻居
LIME的解释核心是通过分析模型对邻居样本的响应来解释其对目标输入的行为。为了确保生成的邻居样本既真实又接近目标输入,SEGAL采用了一种基于Transformer的生成模型,结合“分布内采样”和“局部采样结合”,确保邻居样本来自与训练数据相同的分布。
2. 自适应加权方法
在LIME中,控制邻居样本加权的超参数对解释的稳定性至关重要。传统LIME采用固定的加权策略,可能导致解释结果不一致。SEGAL提出了一种自适应加权方法,根据邻居与目标样本的距离动态调整加权,通过引入了一个标量参数,决定解释过程中考虑的邻居样本范围。并且在给定的搜索区间内优化该参数,确保只有最相关的邻居参与解释,从而进一步提升解释的稳定性。
实验结果及分析:
在本实验中,针对提出的SEGAL方法进行了多角度的实验设计和分析。在“邻居生成“方面,实验结果显示,传统方法生成的邻居样本与目标样本之间的距离较大,难以为解释过程提供有效的邻近样本。而生成模型结合局部采样策略的方法显著改善了这一问题,生成的邻居样本更接近目标样本,确保了解释的局部性和有效性。
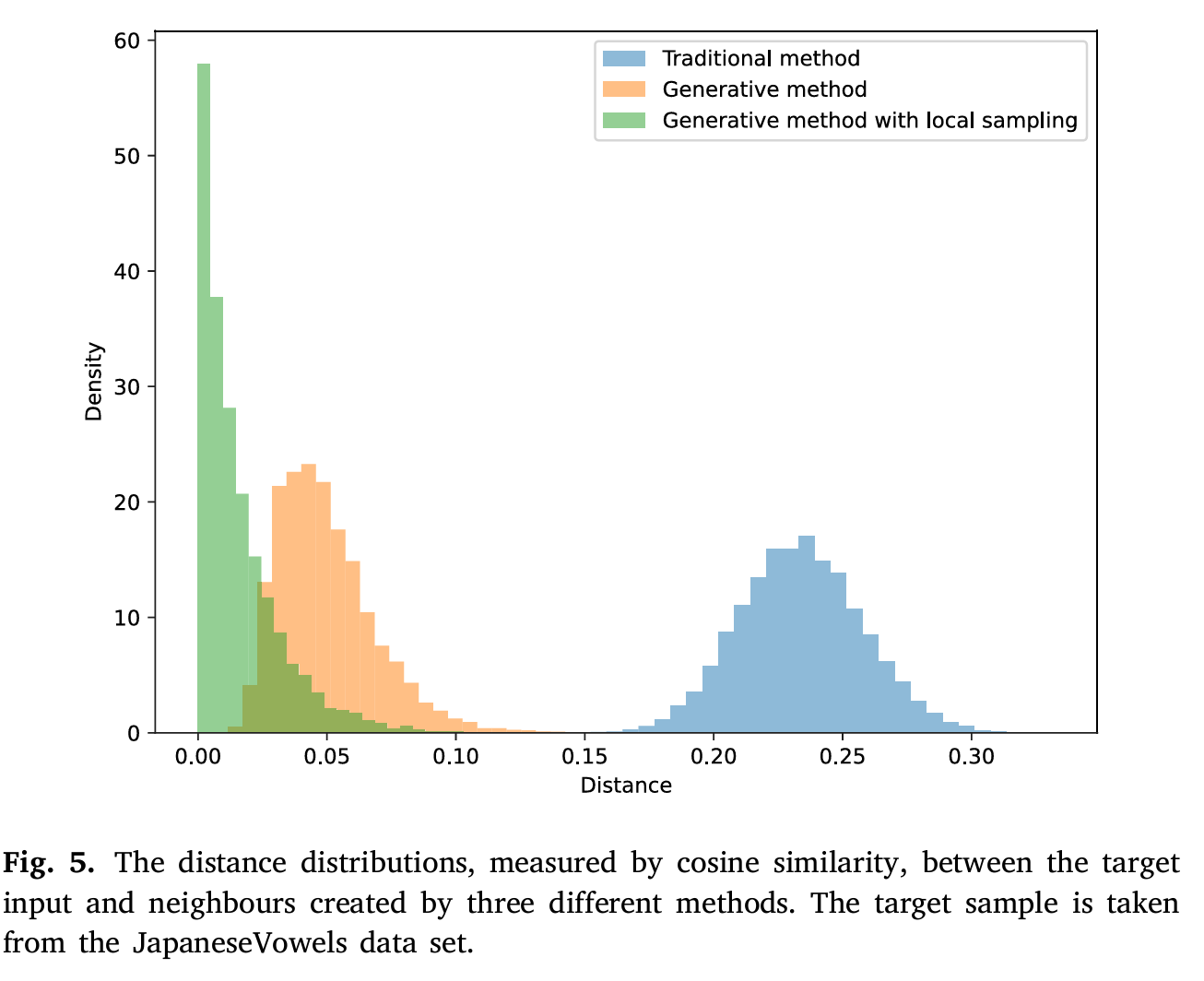
图3 提出的邻居生成方法产生了更接近于目标样本的数据
通过与基准方法的比较表明,SEGAL在稳定性评估中表现突出,其解释结果在多个数据集中表现优异。在Jaccard相似性指数的评估中,SEGAL在大部分数据集上都取得了较高的分数,证明了其在生成稳定解释方面的能力。
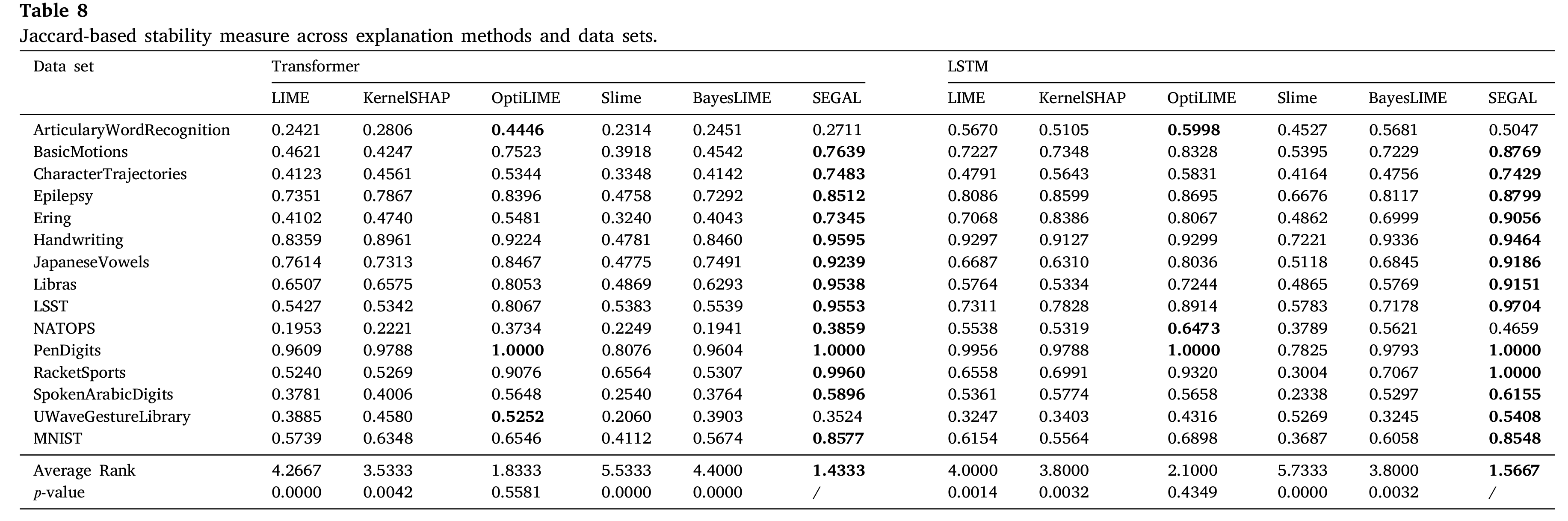
结论:
在本文中,我们针对LIME在多变量时间序列分类问题中的稳定性进行了深入研究,特别是传统邻居生成方法引发的分布外问题(The Out-Of-Distribution Problem)对解释结果的影响。为了缓解这一问题,我们提出在LIME的邻居生成过程中引入生成模型,以生成分布内的样本。实验结果表明,采用该生成模型后,LIME提供的解释变得更加稳定。同时,我们提出的自适应加权方法进一步提高了解释过程的计算效率。
分布外问题是可解释人工智能领域中公认的重要问题,对最终的解释性能有着显著影响。本研究首次系统地探讨了该问题对LIME解释稳定性的影响。由于在解释过程中通常需要生成样本,这不仅适用于LIME,还应引起其他类似解释方法的重视。我们希望本研究的发现能够为未来的研究提供启发,继续解决这一关键问题。
作者简介:
孟翰,中国石油大学(北京)人工智能学院特任岗位副教授。本科和硕士毕业于中国石油大学(北京),分别获得石油工程和油气井工程学位,随后在英国诺丁汉大学获得计算机科学博士学位。于2024年加入中国石油大学(北京)人工智能学院。研究方向包括可解释人工智能、生成式模型、时间序列分析等。专注于将前沿AI技术应用于石油行业的挑战性问题。