
数据稀缺情况下的情景识别研究
中文题目:数据稀缺情况下的情景识别研究
论文题目:Grounded Situation Recognition under Data Scarcity
录用期刊:Scientific Reports (中科院二区)
作者列表:
1) 周 静 中国石油大学(北京)人工智能学院 计算机科学与技术 硕22
2) 刘志强 中国石油大学(北京)人工智能学院 计算机科学与技术 硕23
3) 胡思颍 中国石油大学(北京)人工智能学院 计算机科学与技术 硕22
4) 李晓雪 中国石油大学(北京)人工智能学院 计算机科学与技术 硕23
5) 王智广 中国石油大学(北京)人工智能学院 计算机科学与技术系 教师
6) 鲁 强 中国石油大学(北京)人工智能学院 智能科学与技术系 教师
摘要:
情景识别(Grounded Situation Recognition,GSR)是一项生成图像结构化描述的任务。对于给定的图像,GSR需要识别出关键动词、角色所对应的名词及其边界框。然而,目前的GSR研究需要大量精心标注的图片,这需要耗费许多的人力和时间,使得扩大检测类别成本高昂。我们的研究旨在提高模型在数据稀缺场景下检测和定位的准确率,显著降低模型对数据量的需求,进而为后续扩大检测类别的工作奠定基础。在本文中,我们提出了Grounded Situation Recognition under Data Scarcity(GSRDS)模型,该模型以CoFormer模型作为基线,并对图像特征提取、动词分类和边界框检测三个子任务进行优化,以适应数据稀缺场景。具体来说,我们利用EfficientNetV2-M替代ResNet50来提取高级图像特征,并设计了Transformer 与 CLIP 相结合的动词分类(Transformer Combined with CLIP for Verb classification,TCCV) 模块,利用CLIP图像编码器提取的特征来辅助提升动词分类精度。同时,我们设计了多源动词角色查询(Multi-source Verb-Role Queries,Multi-VR Queries)和双并行解码器(Dual Parallel Decoders,DPD)模块来提升边界框检测精度。经过广泛的对比实验和消融实验,证明了我们的方法能够在稀缺的数据样本上取得更高的检测精度。
背景与动机:
情景识别(GSR)作为计算机视觉领域的重要任务,旨在生成图像的结构化描述。近年来,随着深度学习技术的发展,研究者们在GSR任务上取得了一定的进展,然而大多数研究依赖于大量精心标注的数据集,如SWiG。这些数据集虽然为模型提供了丰富的训练数据,但其构建成本高昂且耗时,限制了GSR在实际应用中的推广和实施。在许多实际场景中,尤其是在专业领域,标注数据的稀缺性成为了研究的一大挑战。例如,在医疗、自动驾驶等领域,相关图像往往难以获取大量标注样本,但这些领域的GSR应用却具有极大的潜力,通过精准的场景识别和对象定位,可以极大提高决策的智能化和准确性。因此,研究如何在数据稀缺的情况下进行GSR任务变得尤为重要。通过探索在数据稀缺条件下的GSR,我们可以降低对大规模标注数据的依赖,减轻数据标注的成本,同时为未来在各种实际应用场景中的推广打下基础。这不仅能够推动GSR研究的深入发展,也能在特定领域的智能化系统构建中发挥重要作用。
设计与实现:
我们在SWiG数据集上利用随机抽样策略,构建了原数据集1∕2、1∕4、1∕8、1∕12和1∕16数据量的小规模数据集以用于模拟数据稀缺的场景。本文提出的GSRDS模型架构如图1所示,主要包括三个部分:图像特征提取,动词预测,名词及边界框预测。GSRDS利用EfficientNetV2-M提取图像特征并与位置编码相加作为输入。TCCV模块利用Transformer和CLIP编码器提取的特征对动词进行分类。Multi-VR Queries模块融合了动词、角色及其定义作为对象查询,与Glance Transformer输出的聚合图像特征一起作为DPD的输入。DPD包括Gaze-Step2 Transformer和Transformer Con-Decoder,用于预测语义角色所对应的名词和边界框,它们的输出将会被取均值,然后输入到三个前馈网络(FFN)分支中得到预测的结果。
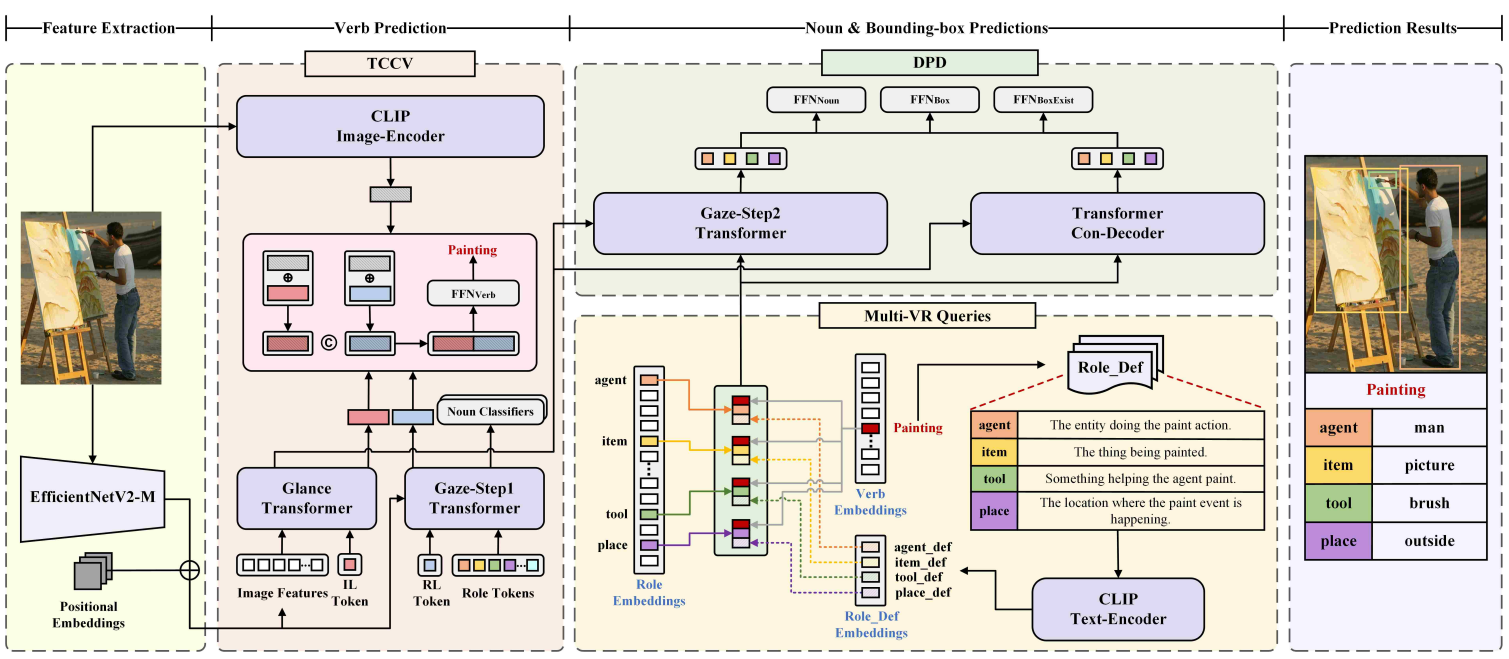
图1 GSRDS 模型架构
实验结果及分析:
表1的结果展示了在五种不同规模数据量的设置下,GSRDS与其他三个模型在14个指标上的对比结果。我们针对其中5个关键性指标绘制了折线图如图2所示,(a),(b)和(c)图分别代表在Top-1 Predicted Verb设置下verb , value 和grnd value 指标在五种数据量级上的实验结果;(d)和(e)图代表在Ground-Truth Verb设置下value 和 grnd value指标在五种数据量级上的实验结果。可以看出,随着数据量的量级减小,GSRDS模型的优势愈发明显。表2展示了消融实验结果。
表1 GSRDS与不同模型的对比实验结果
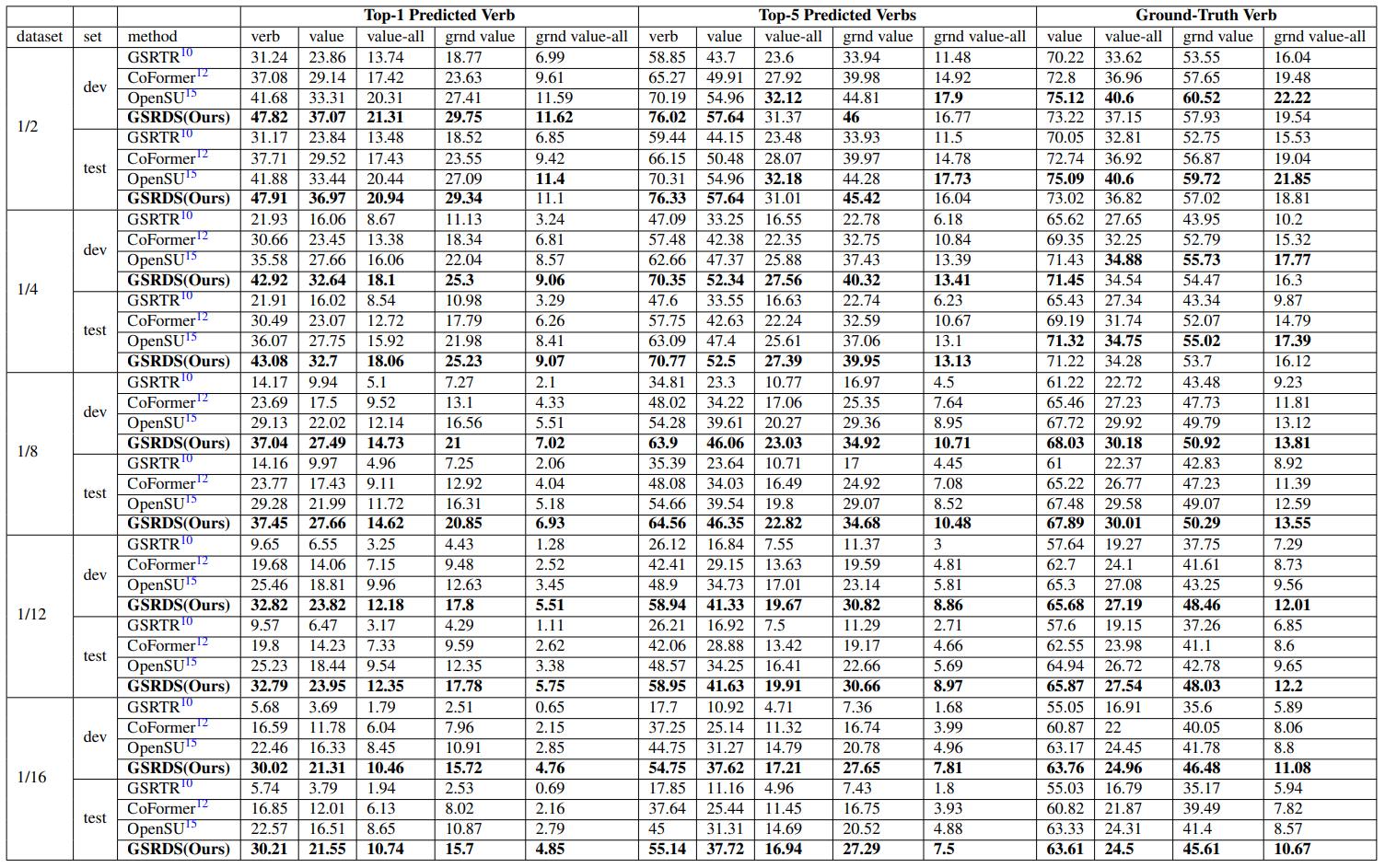
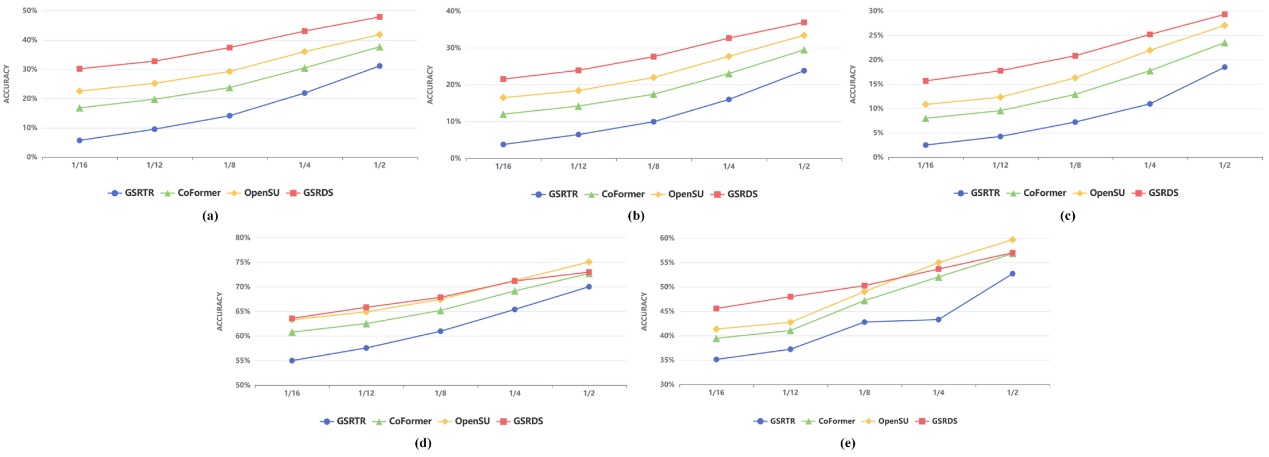
图2关键性指标实验结果折线图
表2 GSRDS模型在1/8数据量级上的消融实验结果

结论:
在本文中,我们针对数据稀缺场景下的GSR任务进行研究,设计了GSRDS模型。具体来说,我们利用EfficientNetV2-M来替代ResNet50提取图像特征,并设计TCCV模块,结合CLIP图像编码器提取的特征,得到了更准确的动词分类结果。同时,我们设计了Multi-VR Queries和DPD模块来共同改进边界框检测精度。我们分别在五种数据量设置的条件下进行了对比实验和消融实验,验证了我们模型在数据量较小的场景下,可以取得较为优异的表现性能。
尽管GSRDS模型在数据稀缺场景下相对于其他模型有较显著的精度提升,但是与使用全部数据集训练的模型仍有差距。在未来的工作中,可以进一步探索以下改进:
• 更合适的特征提取方法:经实验证明,高级图像特征会影响GSR任务的整体性能。未来的工作可以探索更适合数据稀缺场景的主干特征提取网络。
• 更全面的特征学习方法:本研究加入CLIP模型提取的特征来弥补数据稀缺造成的特征表示不足问题,未来的工作可以挖掘更多预训练模型的优势,充分利用数据信息,减少数据量造成的差异。
• 更优异的边界框检测模型:尽管GSRDS针对边界框检测子任务做出了改进,但其还有很大的改进空间。未来的工作可以从提高名词分类精度和提升目标检测精度两方面对边界框检测模型进行改进。
• 更广泛的检测范围:本研究主要关注于对模型的改进,所使用的数据是从SWiG数据集中抽样而得,未来的工作可以不局限于SWiG数据集的504个类别,可以进一步扩大到更多的类别。
通讯作者简介:
王智广,教授,博士生导师,北京市教学名师。中国计算机学会(CCF)高级会员,全国高校实验室工作研究会信息技术专家指导委员会委员,全国高校计算机专业(本科)实验教材与实验室环境开发专家委员会委员,北京市计算机教育研究会常务理事。长期从事分布式并行计算、三维可视化、计算机视觉、知识图谱方面的研究工作,主持或承担国家重大科技专项子任务、国家重点研发计划子课题、国家自然科学基金、北京市教委科研课题、北京市重点实验室课题、地方政府委托课题以及企业委托课题20余项,在国内外重要学术会议和期刊上合作发表学术论文70余篇,培养了100余名硕士博士研究生。