
ScalFrag:面向GPU的高效自适应启动与分块MTTKPRP方法
中文题目:ScalFrag:面向GPU的高效自适应启动与分块MTTKPRP方法
论文题目:ScalFrag: Efficient Tiled-MTTKRP with Adaptive Launching on GPUs
录用期刊/会议:IEEE International Conference on Cluster Computing (CCF-B类会议)
原文DOI:10.1109/CLUSTER59578.2024.00036
原文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10740878
录用/见刊时间:07 November 2024
作者列表:
1) 林文清 中国石油大学(北京)人工智能学院 计算机科学与技术 本21
2) 王赫萌 中国石油大学(北京)人工智能学院 先进科学与工程计算 博23
3) 邓昊东 中国石油大学(北京)人工智能学院 计算机技术 硕24
4) 孙庆骁 中国石油大学(北京)人工智能学院 计算机系教师
摘要:
本文旨在加速稀疏张量的MTTKRP(矩阵化张量乘以Khatri-Rao积)计算,首先在GPU平台上动态选择最佳的内核启动配置,以适应输入张量的独特特征;再通过共享内存减少数据访问时间,采用流水线并行技术允许多个计算任务并行执行,从而降低整体计算时间。ScalFrag缓解了稀疏张量模式不规则造成的瓶颈和数据计算等待时间过长的问题,在处理不同特征的稀疏张量时表现优于先进库ParTI,且在较小的张量上,性能提升更为显著。实验结果表明,MTTKRP的性能提高了1.2倍至2.2倍。
背景与动机:
张量分解是从大量高维稀疏数据集中挖掘潜在模式的关键技术,在揭示复杂数据中的潜在结构方面发挥着至关重要的作用。在张量分解的各种方法中,张量典范分解(CPD)因其在捕捉多元线性关系方面的有效性,在众多科学学科和实际应用中被广泛采用。然而,CPD的计算效率由MTTKRP(矩阵化张量乘以Khatri-Rao积)所主导。由于张量数据的多样性和复杂性,以及计算环境的多变性,几乎不可能为MTTKRP计算找到一组通用且最优的参数配置。且现实世界的张量数据通常很大,从主机到设备传输数据会花费大量时间。本文旨在加速GPU平台上的稀疏MTTKRP计算,通过自调优启动策略和流水线并行策略,缓解稀疏张量模式不规则性相关的瓶颈。
设计与实现:
一、自调优启动策略:
该策略的核心在于动态选择最优的参数组合,以适应不同特征的矩阵化张量。通过分析张量的维度和分布特征,提取张量的关键特征参数,包括张量的全局特征和局部特征,以预测MTTKRP操作的执行情况。利用提取的特征参数,通过机器学习训练不同的启动参数选择模型,输出张量启动参数的最优组合。在内核计算过程中,将频繁访问的数据和中间结果存储在共享内存中,以减少数据访问的延迟。
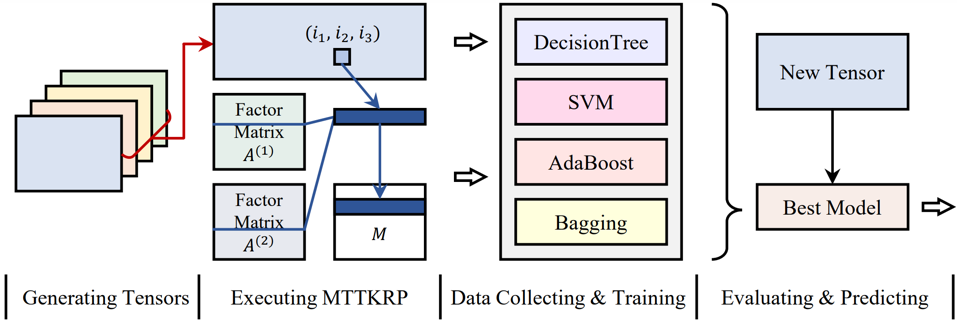
图1 自调优启动参数选择策略
二、流水线策略:
该策略首先对COO格式的稀疏张量进行分段,每个分段包含一部分非零元素及其相应的坐标信息。然后根据GPU的性能和内存容量以及段的数量创建不同数量的CUDA流,每个流负责传输和处理一个或多个特定的数据段。当一个数据段从CPU传输到GPU时,GPU可以处理之前已经传输完成的数据段,从而减少等待时间,提高资源利用率。
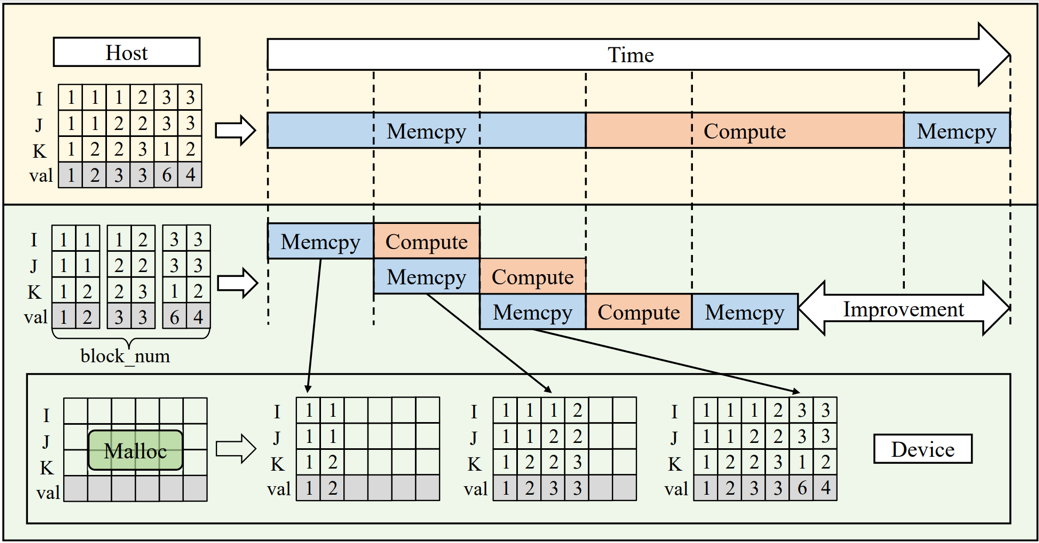
图2 用于MTTKRP计算的流水线并行策略
实验结果及分析:
一、MTTKRP内核性能对比
使用ScalFrag后,稀疏张量MTTKRP的平均加速比为1.2倍(最高为2.2倍)。对于较小的稀疏张量,性能加速更为明显,因为它们在仅非零元素的数量上就存在显著差异。实验表明,固定参数GFlops并不总能达到最佳计算性能。ScalFrag通过为每个输入稀疏张量选择最佳启动设置,有效提高了MTTKRP的计算效率。
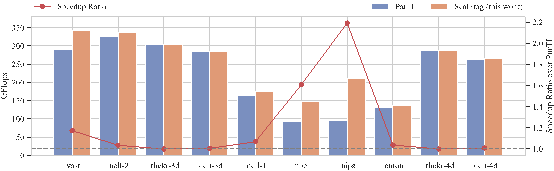
图3 ScalFrag和ParTi的MTTKRP内核性能对比
二、MTTKRP端到端性能对比实验表明,大多数张量都能通过流水线并行实现性能提升,平均加速比为1.5倍,最大加速比约为2.0倍。输入的稀疏张量越小,流水线能覆盖的传输时间就越多,性能加速就越明显,ScalFrag缓解了前文提到的数据计算等待时间过长的问题。
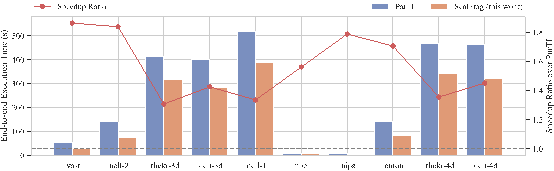
图4 ScalFrag和ParTi的MTTKRP端到端性能对比
结论:
本文深入探讨了针对GPU平台的MTTKRP优化方法,并设计了一种自适应启动策略,该策略根据张量的稀疏特征动态选择最佳的启动参数组合,以确保充分利用GPU的计算资源。本文还引入了一种流水线并行技术,通过优化任务之间的依赖关系,使多个计算任务能够并行执行,从而显著减少总体计算时间。实验结果表明,ScalFrag比先进库ParTI表现更好,并且能够在短时间内找到更合适的内核启动参数配置。
通讯作者简介:
孙庆骁,中国石油大学(北京)计算机系副教授,硕士生导师,CCF体系结构专委会执行委员,CCF高性能计算专委会执行委员。2023年博士毕业于北京航空航天大学计算机学院,入选首届“CCF体系结构优秀博士学位论文激励计划”,获得“ACM SIGHPC China优秀博士学位论文”。从事任务运行时系统、深度学习系统和性能建模调优等方面的研究,主持国家自然科学基金青年项目和国家重点研发计划子课题各1项。以第一作者及通讯作者在SC、IPDPS、TC、TPDS等高水平国际会议和期刊上发表论文10余篇,获得IEEE Computer亮点论文和CLUSTER’21会议最佳论文提名。担任IEEE TC/TPDS/TCC、ACM Computing Survey、Springer SUPE/FCS、CCF THPC、计算机工程与科学等国内外期刊的审稿人。
联系方式:qingxiao.sun@cup.edu.cn