
Cuper:利用定制数据流和感知解码加速的高带宽内存FPGA上的稀疏矩阵-向量乘
中文题目:Cuper:利用定制数据流和感知解码加速的高带宽内存FPGA上的稀疏矩阵-向量乘
论文题目:Cuper: Customized Dataflow and Perceptual Decoding for Sparse Matrix-Vector Multiplication on HBM-Equipped FPGAs
录用期刊/会议:2024 Design, Automation and Test in Europe Conference (DATE) (CCF-B类会议)
原文链接:https://ieeexplore.ieee.org/document/10546672
录用/见刊时间:2024-3-25(录用时间)
作者列表:
1)伊恩鑫 中国石油大学(北京)人工智能学院 计算机技术 硕21
2)段懿洳 中国石油大学(北京)人工智能学院 计算机科学与技术 硕21
3)柏一诺 中国石油大学(北京)人工智能学院 电子信息工程 本19
4)赵 康 北京邮电大学集成电路学院 集成电路系教师
5)金 洲 中国石油大学(北京)人工智能学院 计算机系教师
6)刘伟峰 中国石油大学(北京)人工智能学院 计算机系教师
摘要:
稀疏矩阵-向量乘(SpMV)是许多科学计算和工程应用的重要组成部分。考虑到SpMV的不规则数据访问模式,其加速通常受限于有限的带宽。 新兴的高带宽内存(HBM)为加速SpMV提供了良机。然而,如何确保高带宽利用率和低内存访问冲突仍是具有挑战的。 在本文中,我们介绍了配备HBM的FPGA上的高性能SpMV加速器Cuper。通过定制HBM兼容的数据流和以感知解码器为中心的硬件架构,充分提高带宽利用率和向量重用性。实验结果表明,Cuper的几何平均吞吐量、带宽效率和能效比配备HBM的FPGA上四种最新的SpMV加速器:HiSparse、Graphlily、Sextens和Serpens有显著提升。与NVIDIA Tesla K80 GPU相比,Cuper实现了2.51倍的吞吐量提升和7.97倍的能效优化。
背景与动机:
FPGA被认为是加速SpMV的极具吸引力的平台。与传统的CPU和GPU平台相比,FPGA可以通过定制数据流和内存结构充分发挥SpMV的并行潜力。并且,FPGA通常具有较低的功耗。然而,在配备DDR内存系统的传统FPGA平台上加速SpMV存在一定局限。与传统的DDR内存相比,高带宽内存(HBM)具有更多的内存通道和更大的内存带宽,这为加速SpMV带来了巨大的机遇。但充分利用配备HBM的FPGA的高带宽优势设计高性能通用SpMV加速器还面临着多项挑战,主要包括以下几个方面:(1)现有的稀疏存储格式对充分利用HBM的高带宽潜力构成了挑战;(2)固有的RAW冲突导致计算占用率低;(3)缺乏对输入向量和片上存储器的有效利用。
设计与实现:
一、稀疏存储格式
我们使用稀疏切片作为基本单位,确保PE间相对负载平衡,为了利用向量重用性,我们用CSC格式来存储稀疏切片;为了减少额外控制开销,我们利用COO格式存储每个稀疏切片中的非零元信息。
二、重排算法和数据流处理方案
我们设计了一种两步重排序算法:(1)冲突感知的行重排算法,利用无冲突滑动窗口减轻了RAW的影响;(2)重用感知的排重排算法,通过收集可重用元素提高了向量的重用性。此外,我们采用循环数据流分配方式,以减少并发访问带来的HBM通道冲突。
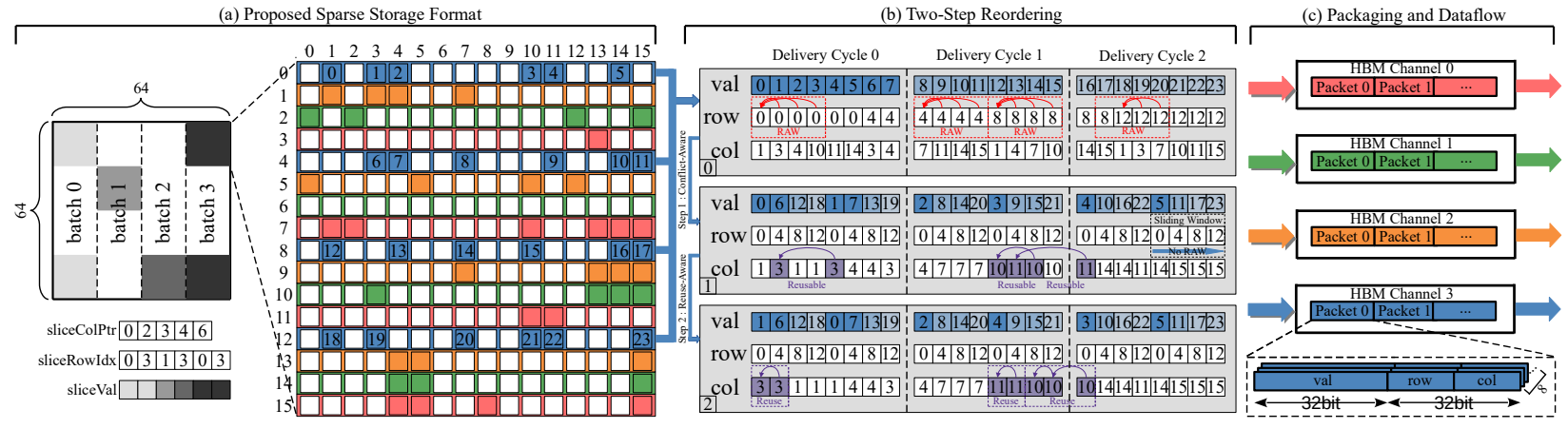
图 1:稀疏存储格式、两步重排序算法和数据流处理方案
三、Cuper的硬件架构设计
我们精心规划了HBM通道的分配方案,以充分利用内存带宽。以感知解码器为中心的硬件架构可以跳过稀疏矩阵中的空白结构,以减少冗余的向量片上内存写入。灵活的重用寄存器暂存可复用向量元素,以提高向量重用性。此外,我们还设置了Ping-Pong缓冲区,以掩盖不同批次之间的内存切换延迟。
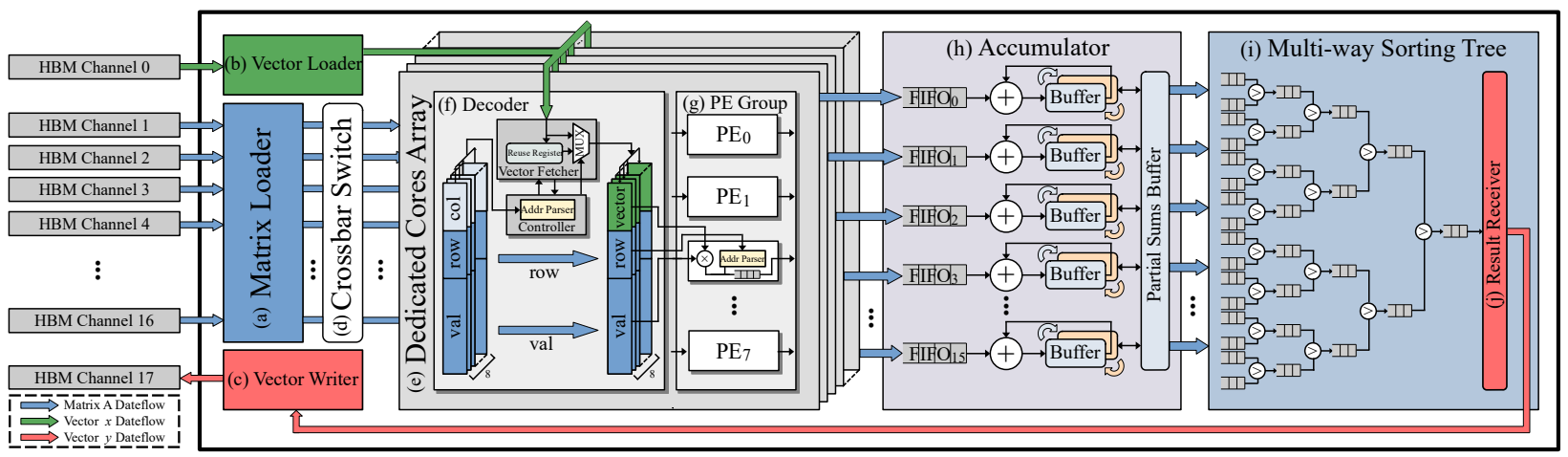
图 2:Cuper的硬件架构设计
实验结果及分析:
一、 Cuper与FPGA上的SpMV加速器对比
Cuper的几何平均吞吐量分别比最新的SpMV加速器HiSparse、GraphLily、Sextans和Serpens高出3.28倍、1.99倍、1.75倍和1.44倍。此外,几何平均带宽效率分别提高了3.28倍、2.20倍、2.82倍和1.31倍,而几何平均能效则分别优化了3.59倍、2.08倍、2.21倍和1.44倍。
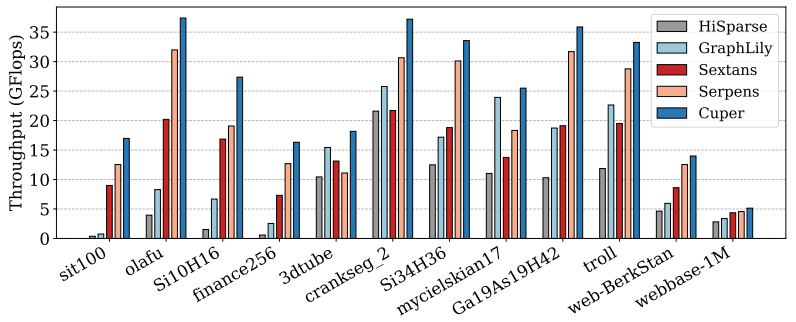
图 3:五种SpMV加速器的吞吐量对比
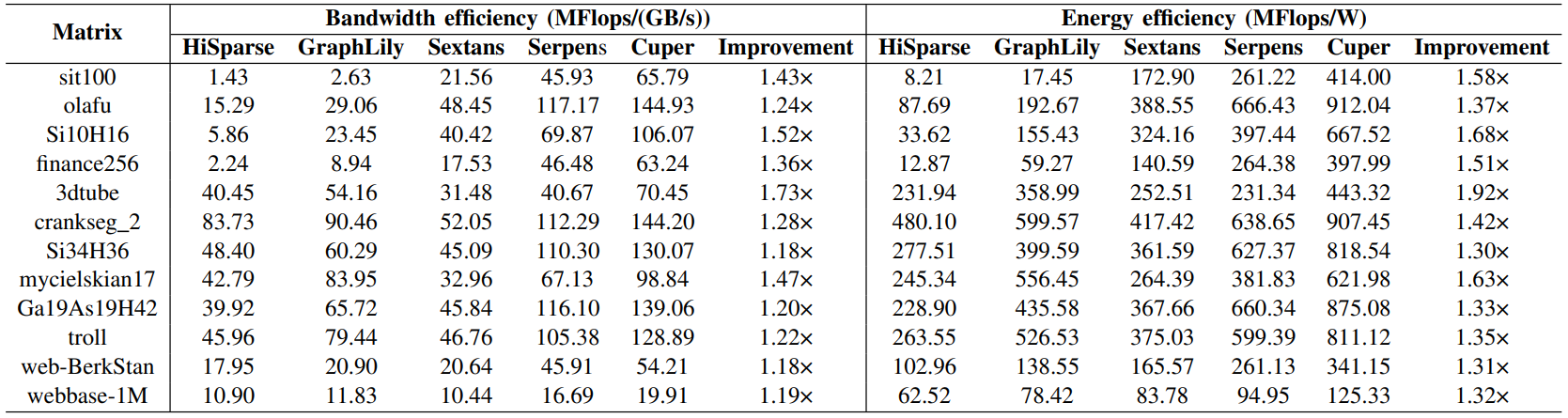
表 1:五种SpMV加速器在12个评估矩阵上的带宽效率和能效对比
二、 Cuper与K80 GPU对比
K80 GPU和Cuper的最大吞吐量分别为24.81 GFlops和46.74 GFlops。与K80 GPU相比,Cuper在2,757个SuiteSparse矩阵上的吞吐量和能效分别提高了2.51倍和7.97倍。
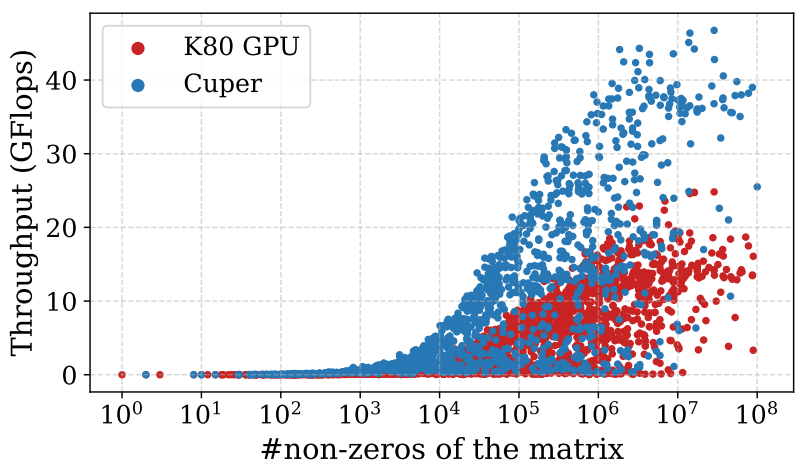
图 4:K80 GPU和Cuper在2,757个评估矩阵上的吞吐量对比
结论:
本文中,我们在配备HBM的FPGA上提出了一种新颖的高性能SpMV加速器Cuper。定制稀疏格式的非零元存储和稀疏块结构充分利用了HBM的优势。重排算法有效缓解了SpMV累加阶段的写后读冲突并提高了向量重用性。以感知解码器为中心的硬件架构设计进一步改善了重用性和片上内存利用率。评估结果表明,与四种最先进的高带宽SpMV加速器和K80 GPU相比,Cuper在吞吐量、带宽效率和能效方面都更具优势。
通讯作者简介:
金洲,中国石油大学(北京)计算机系副教授,入选北京市科协青年人才托举工程、校青年拔尖人才。主要从事集成电路设计自动化(EDA)、面向科学计算的DSA软硬件协同设计等方面的研究工作。主持并参与国家自然科学基金青年项目、重点项目,科技部重点研发微纳电子专项、高性能计算专项青年科学家项目,国家重点实验室开放课题、企业横向课题等。在DAC、TCAD、TODAES、SC、PPoPP、IPDPS、TCAS-II、ASP-DAC等重要国际会议和期刊上发表60余篇高水平学术论文。获EDA2青年科技奖、SC23最佳论文奖、ISEDA23荣誉论文奖、IEEJ九州支部长奖等。
联系方式:jinzhou@cup.edu.cn