
面向多核MCU的低延迟深度学习推理调度
中文题目:面向多核MCU的低延迟深度学习推理调度
论文题目:Low-Latency Deep Learning Inference Schedule on Multi-Core MCU
录用期刊/会议:The International Joint Conference on Neural Networks (CCF C)
作者列表:
1)徐朝农 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机系教师
2)刘 民 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
3)孔维明 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机技术专业 硕21
4)李 超 之江实验室
文章简介:
随着智能物联网(AIoT)的持续发展,深度学习(DL)正逐渐成为其服务中不可或缺的一部分。深度学习使得智能处理和分析物联网设备产生的大量数据成为可能,并且正成为这些系统的重要工具。AIoT的典型应用包括监测机械振动以预测机器故障、视觉任务中的人员检测,以及实时语音识别等。传统上,这些应用依赖于丰富的云端或雾端计算资源来满足高响应性要求。然而,云端或雾端推理在延迟、能耗、隐私保护和通信接入等方面引入了高昂的开销。随着AIoT 服务的急剧增加,云端或雾端推理变得过于昂贵且不可行。幸运的是,低成本、低功耗且高性能的多核微控制器(MMCU)的出现,使得在设备上进行DL推理成为可能。通过充分利用硬件的资源来最小化推理延迟,深度学习推理框架可以满足AIoT系统的高响应性要求。目前可用的推理框架,如 TFLM、CMSIS-NN、CMix-NN 和 CIMAX-Compiler,采用了核友好的优化措施,例如剪枝、量化和循环优化,以减少推理延迟。尽管这些方法极大地改进了神经网络(NN)推理性能,但它们没有为 NN 中的每个算子选择合适的数据布局,也没有充分利用 MMCU 的硬件资源。因此,本文旨在研究如何为部署在 MMCU 上的 NN 选择合适的数据布局,并充分挖掘 MMCU 的硬件资源以加速 NN 的推理过程。
摘要:
随着基于微控制器(MCU)的智能物联网(AIoT)服务的兴起,深度学习(DL)被广泛应用以提升用户体验。这类由深度学习辅助的服务依赖于快速的神经网络(NN)执行来实现高响应性,要求小型物联网设备通过有效利用其底层硬件资源来最小化 NN 的执行延迟。然而,现有的推理框架无法为多核微控制器(MMCU)实现令人满意的实时性能。我们指出可以通过两种改进方法来加速NN推理:1) 为 NN 中的每个算子选择合适的数据布局;2) 通过适当地将每个算子分配到多个核上来发挥 MMCU 的能力。
在本文中,我们提出了一种针对 MMCU 的低延迟深度学习推理的新思路,即联合数据布局和算子内并行性(IOP)。我们基于自建的延迟预测器来建模这一问题,该预测器能预测每个NN 算子的执行延迟。此外,我们提出了一个时间复杂度为 ![]() 的算法,以寻找最优的调度计划,其中
的算法,以寻找最优的调度计划,其中 ![]() 和
和 ![]() 分别代表算子可能的最大布局数和 IOP 策略数。实验评估结果表明,我们的调度计划能为 CMSIS-NN(一种先进的边缘推理软件栈)实现1.52倍至3.37倍的加速。此外,与最先进的 IOP 执行系统相比,我们的调度计划大约实现了1.67倍的加速。
分别代表算子可能的最大布局数和 IOP 策略数。实验评估结果表明,我们的调度计划能为 CMSIS-NN(一种先进的边缘推理软件栈)实现1.52倍至3.37倍的加速。此外,与最先进的 IOP 执行系统相比,我们的调度计划大约实现了1.67倍的加速。
主要内容:
本研究的目的是充分利用MMCU的硬件资源加速计算图![]() 的推理。由于张量数据布局和IOP策略极大地影响了每个算子的推理延迟,因此,我们将这个问题构建为一个联合优化问题,将推理调度策略
的推理。由于张量数据布局和IOP策略极大地影响了每个算子的推理延迟,因此,我们将这个问题构建为一个联合优化问题,将推理调度策略![]() 作为控制变量。因此,该问题可建模为:
作为控制变量。因此,该问题可建模为:
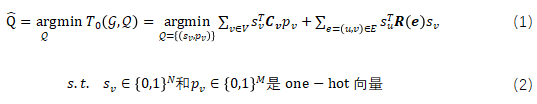
为求解该问题,本文提出节点消除和边消除技术简化原计算图,如图1所示。
节点消除:如果计算图![]() 的节点
的节点![]() 仅有一条入边
仅有一条入边![]() 和一条出边
和一条出边![]() ,且它们所对应张量的布局转换开销矩阵为
,且它们所对应张量的布局转换开销矩阵为![]() 和
和![]() ,那么节点消除技术可以从
,那么节点消除技术可以从![]() 中移除
中移除![]() 、
、![]() 和
和![]() 并插入新边
并插入新边![]() ,其所对应张量的布局转换开销矩阵是:
,其所对应张量的布局转换开销矩阵是:
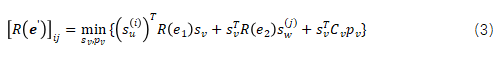
边消除:如果计算图![]() 有两条同源节点和目的节点的边
有两条同源节点和目的节点的边![]() 和
和![]() ,且它们所对应张量的布局转换开销为
,且它们所对应张量的布局转换开销为![]() 和
和![]() ,那么边消除技术可以移除
,那么边消除技术可以移除![]() 和
和![]() 并插入
并插入![]() ,该新边所对应的张量的布局转换开销矩阵为:
,该新边所对应的张量的布局转换开销矩阵为: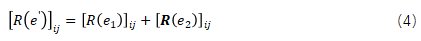
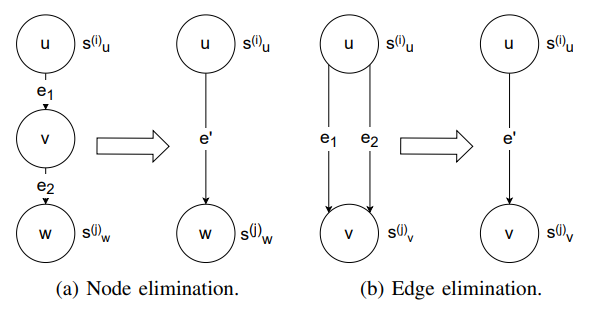
图 1 节点消除和边消除
通过节点和边的消除,我们可以得到一个通常只包含两个节点的简化计算图![]() 。因此,在常数时间复杂度内,我们可以得到简化计算图
。因此,在常数时间复杂度内,我们可以得到简化计算图![]() 的最优推理调度策略。随后,我们通过反转节点消除和边消除的过程即可获得被消除节点的最优推理调度策略。最终,我们可以得到原计算图
的最优推理调度策略。随后,我们通过反转节点消除和边消除的过程即可获得被消除节点的最优推理调度策略。最终,我们可以得到原计算图![]() 的最优推理调度策略
的最优推理调度策略![]() 。
。
此外,我们为常见的神经网络算子(如,矩阵乘法、卷积和池化等)建立了即轻量又准确的时延模型,以量化NN的不同推理调度策略所对应的推理延迟。
单核MCU的标准卷积算子的推理时延![]() 可以通过公式(5)建模。
可以通过公式(5)建模。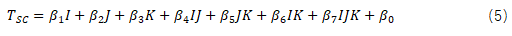
单核MCU的深度卷积算子的推理时延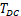
可以通过公式(6)和公式(7)进行建模。
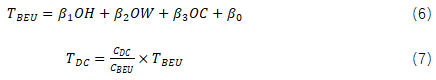
对于其它算子的单核MCU时延模型,如果算子基于GEMM实现,则该算子的时延模型与标准卷子算子的时延模型类似;如果算子直接基于BEU实现,则该算子的时延模型与深度卷积算子的时延模型类似。基于上述单核MCU的时延模型,我们可以通过公式(8)得到MMCU的算子时延模型。

基于上述算法和延迟预测模型,我们在CMSIS-NN上实现了一个算子内并行推理框架CoMCU。
实验结果及分析:
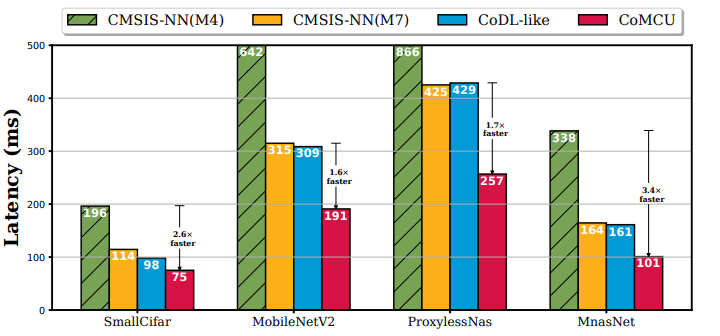
图 2不同NNs采用不同推理调度策略时在STM32H745平台上的推理延迟
我们首先在同构双核微控制器STM32H745上评估CoMCU的性能,如图2所示。从图中可以看出,相较于利用单核MCU进行模型推理的CMSIS-NN,CoMCU可以实现1.6倍的推理加速。此外,相较于现有的IOP系统,CoMCU也能够实现1.7倍左右推理加速。
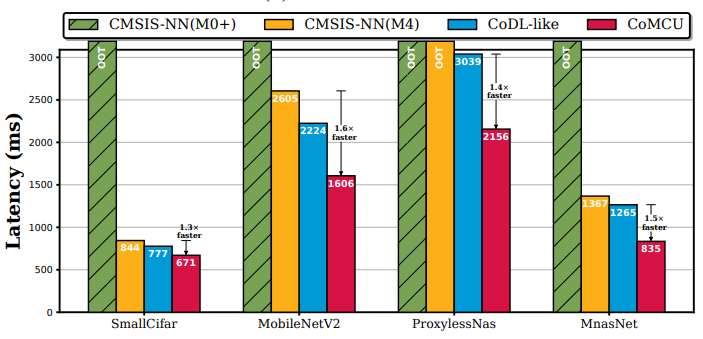
图 3 不同NNs采用不同推理调度策略时在STM32WL55JC平台上的推理延迟
其次,我们也在异构双核微控制器STM32WL55JC上评估了CoMCU,如图3所示。
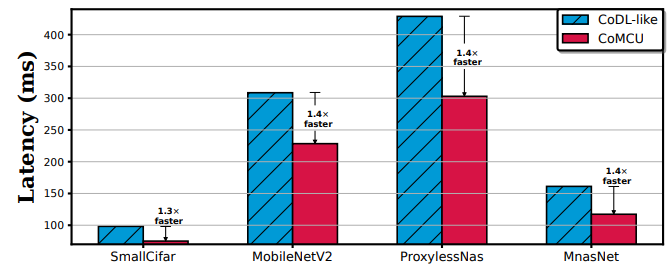
图 4 CoMCU与CoDL-like的IOP策略性能比较

图 5 CoMCU布局优化策略与贪心式布局优化策略的性能比较
此外,我们分别评估了CoMCU的IOP优化和数据布局优化的性能,如图4和图5所示。从图中可以看出,CoMCU的两种优化技术能够分别实现1.4倍和1.2倍左右的推理加速。
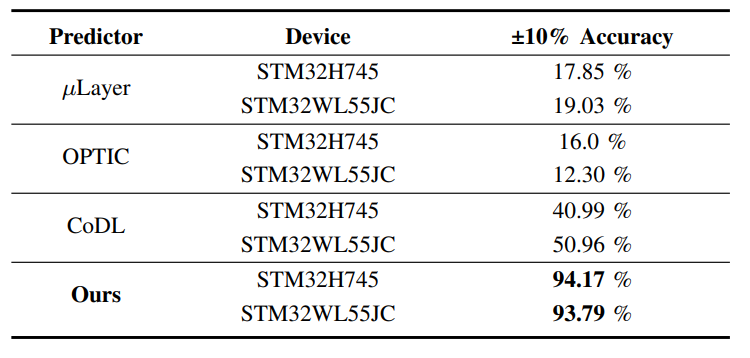
最后,我们评估了CoMCU的延迟预测模型的性能,如上图所示。由于该延迟预测模型考虑了MMCU的平台特性,因此能够实现93%以上的准确率。
结论:
本文分析了数据布局和IOP对算子推理性能的影响,并将神经网络中算子的数据布局优化和IOP优化视为一个联合优化问题进行考虑。为了解决这一问题,我们将其建模为公式(1),并构建了一个准确率约94%的延迟预测器以定量评估不同数据布局和IOP策略下的NN推理延迟。此外,我们提供了一个基于该预测器的动态规划算法以在公式(1)下找到最优的调度方案。我们基于此算法和最先进的边缘推理框架CMSIS-NN实现了端到端的CoMCU框架,并对其进行了评估。实验结果表明,与CMSIS-NN相比,CoMCU能够实现1.52倍至 3.37倍的加速,并且与最先进的 IOP 执行系统相比,其性能达到了1.67倍加速。
通讯作者简介:
徐朝农,博士,中国石油大学(北京)信息科学与工程学院/人工智能学院博士生导师,主要研究方向为无线通信、智慧物联网、边缘智能、嵌入式系统。