
Leda:利用分块数据流在高带宽内存FPGA上加速图神经网络中的稀疏矩阵-稠密矩阵乘
中文题目:Leda:利用分块数据流在高带宽内存FPGA上加速图神经网络中的稀疏矩阵-稠密矩阵乘
论文题目:Leda: Leveraging Tiling Dataflow to Accelerate SpMM on HBM-Equipped FPGAs for GNNs
录用期刊/会议:43rd ACM/IEEE International Conference on Computer-Aided Design (ICCAD '24) (CCF-B类会议)
原文DOI:https://doi.org/10.1145/3676536.3676773
录用/见刊时间:2024-10-27(录用时间)
作者列表:
1)伊恩鑫 中国石油大学(北京)人工智能学院 计算机技术 硕21
2)白佳睿 中国石油大学(北京)人工智能学院 计算机科学与技术 本21
3)聂怡婕 中国石油大学(北京)人工智能学院 电子信息工程 本22
4)牛 丹 东南大学 自动化学院
5)金 洲 中国石油大学(北京)人工智能学院 计算机系教师
6)刘伟峰 中国石油大学(北京)人工智能学院 计算机系教师
摘要:
图神经网络(GNNs)在从图结构中提取数据表征方面发挥着关键作用,推动了多个领域的发展。稀疏矩阵-稠密矩阵乘(SpMM)是GNN的核心运算之一。但是,由于图矩阵的高度稀疏性和非零元的随机分布,加速SpMM面临着巨大挑战。新兴的高带宽内存(HBM)的高并发能力为加速SpMM提供了新机遇。然而,由于负载不均衡和随机内存访问模式,在HBM FPGA上加速SpMM仍然困难重重。
在本文中,我们介绍了配备HBM的FPGA上的高性能SpMM加速器Leda。通过利用分块稀疏格式来平衡负载并增强数据局部性。最小相似度重排算法显著改善了写后读(RAW)依赖。此外,改进的外积数据流调度策略有效缓解了随机内存访问瓶颈。最后,我们提出了一种基于定制数据流的高度并行的硬件架构设计,并探索了输入矩阵的重用性。实验结果表明,Leda在几何平均吞吐量和能效方面,分别比当前最先进的SpMM加速器Sextans和SDMA,以及K80 GPU高出1.27倍和1.36倍、1.85倍和2.00倍、1.95倍和5.23倍。
背景与动机:
目前,现有研究已在通用计算平台(如CPU和GPU)上提出了SpMM的加速方案。然而,由于缺乏专用的内存结构和数据流设计,这些方案在访存效率和计算资源占用率方面表现不佳。配备HBM的FPGA因其深度内存结构定制和高并发能力,已成为加速SpMM的极具吸引力的平台。然而,充分利用HBM来加速SpMM仍然充满挑战,主要包括以下几个方面:(1)现有的稀疏存储格式和并行方法导致处理单元(PE)间的负载高度不均衡;(2)图结构的幂律分布引入随机内存访问模式和较差的数据局部性;(3)RAW依赖导致的高延迟限制了计算资源占用率和吞吐量。
设计与实现:
一、分块稀疏存储格式
我们使用稀疏块作为基本单位,确保PE间相对负载平衡;为了利用输入稠密矩阵的重用性,我们用CSC格式来存储稀疏块;为了减少额外控制开销,我们利用列主序COO格式存储每个稀疏块中的非零元信息;设置16位无符号掩码数组,存储非零元位置信息。
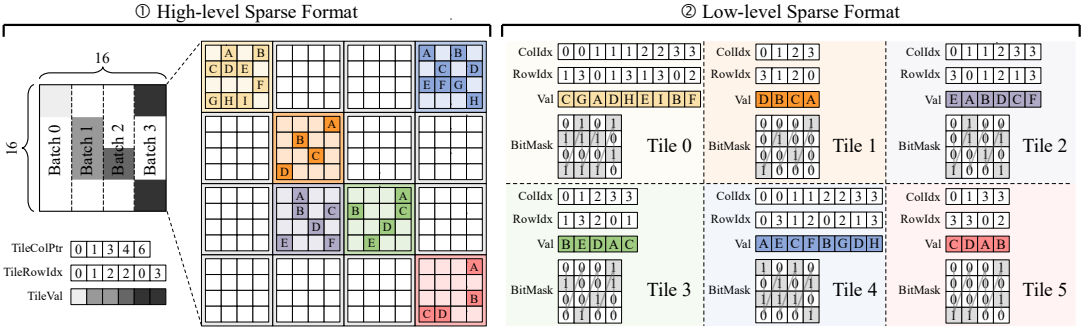
图 1:分块稀疏存储格式
二、最小相似度重排算法
我们提出了一种最小相似度重排算法。该算法利用掩码数组计算稀疏块中列间相似度,进而以列为单位进行非零元重排,同时结合插值操作,有效消除原始数据流中的RAW依赖。
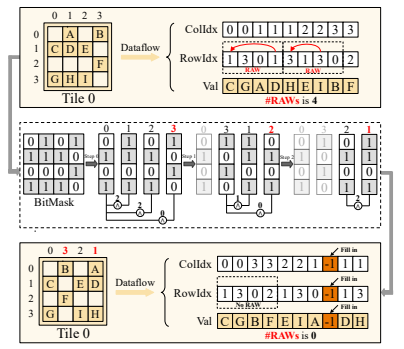
图 2:最小相似度重排算法
三、改进的外积数据流
我们以16×16固定分区大小的稀疏块作为外积数据流的基本单元。由于中间积规模较小,片上缓冲区可完全容纳,既避免了大量片外流量,又提高了输入矩阵的重用性。
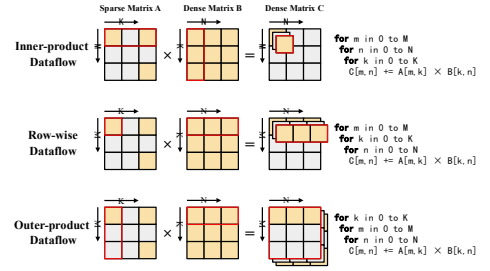
图 3:改进的外积数据流
四、Leda的硬件架构设计
我们精心规划了HBM通道的分配方案,以充分利用内存带宽;专用计算核心阵列中的矩阵乘法单元(MMU)可以跳过稀疏矩阵中的空白结构,以减少冗余的片上内存写入,灵活的重用队列暂存可复用元素,以提高稠密矩阵重用性,设置多个PE组以提高计算并行性;累加器中的矩阵累加单元(MAU)平衡了传输与计算速度,并且支持快速随机读写。
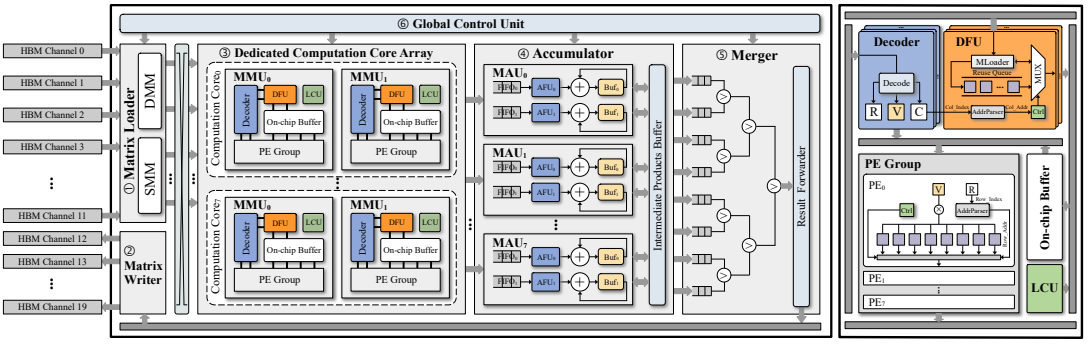
图 4:Leda的硬件架构设计
实验结果及分析:
一、Leda与FPGA上的SpMM加速器对比
Leda的几何平均吞吐量分别比最新的SpMM加速器Sextans-hls和Sextans-tapa高出1.27倍和1.02倍。此外,几何平均能源效率分别提高了1.36倍和1.10倍。
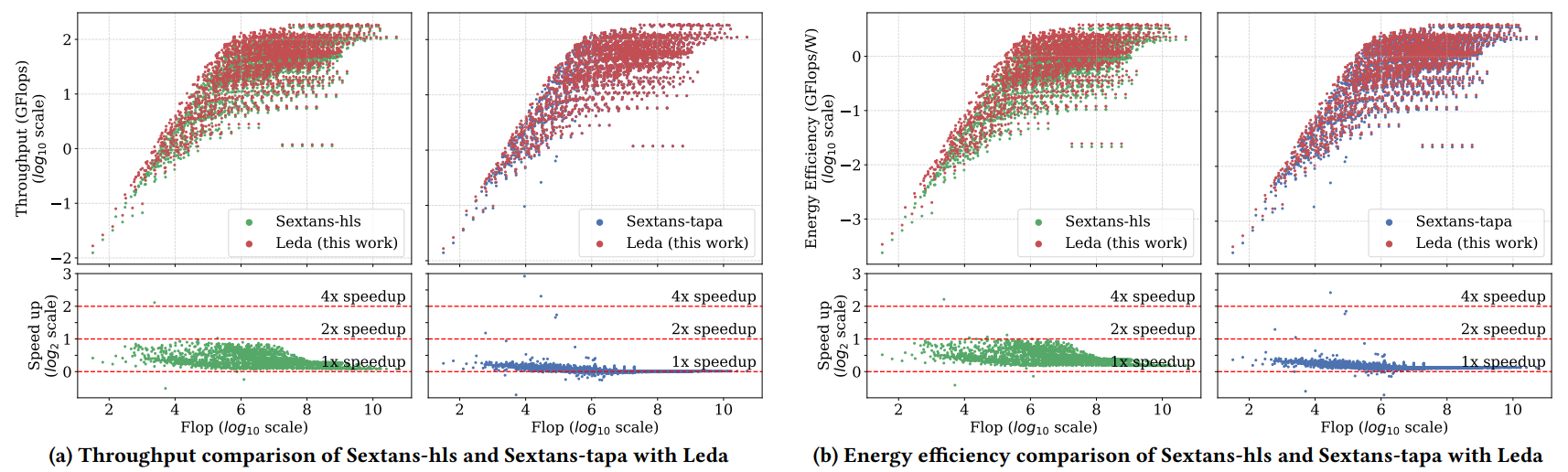
图 5:Leda与Sextans-hls和Sextans-tapa的吞吐量与能效对比
二、Leda与K80 GPU对比
Leda与K80 GPU上的cuSPARSE和GE-SpMM相比,几何平均吞吐量分别提高了1.95倍和1.58倍,几何平均能效分别提高了5.23倍和4.23倍。
三、Leda与2060 GPU对比
Leda与2060 GPU上的cuSPARSE和GE-SpMM相比,几何平均吞吐量分别提高了0.41倍和0.33倍(值得注意的是,2060 GPU的频率远高于Leda,几乎是其8倍左右),几何平均能效分别提高了1.49倍和1.18倍。
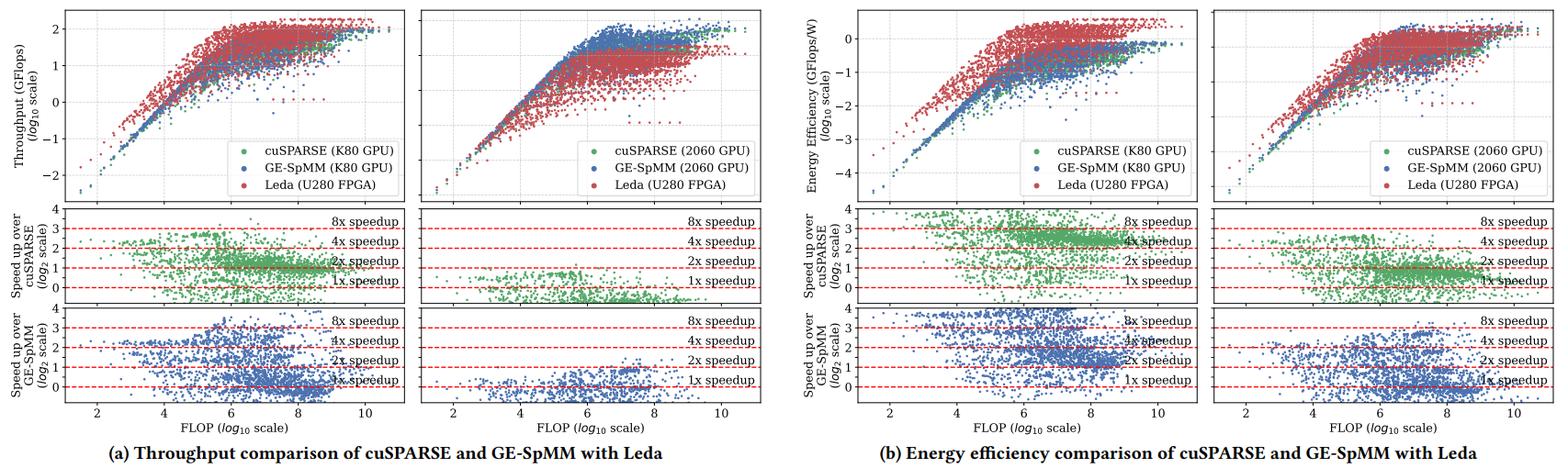
图 6:Leda与cuSPARSE和GE-SpMM在K80 GPU和2060 GPU上的吞吐量与能效对比
四、预处理开销分析
我们比较了Leda的预处理与CPU上单次SpMM的执行时间。在绝大多数矩阵上,预处理时间几乎等同于单次SpMM的时间。只有少数大型图矩阵的预处理时间略高于单次SpMM时间。不过,由于经过一次预处理后,在聚合阶段可以进行多次SpMM迭代,因此Leda的预处理开销可以忽略不计。
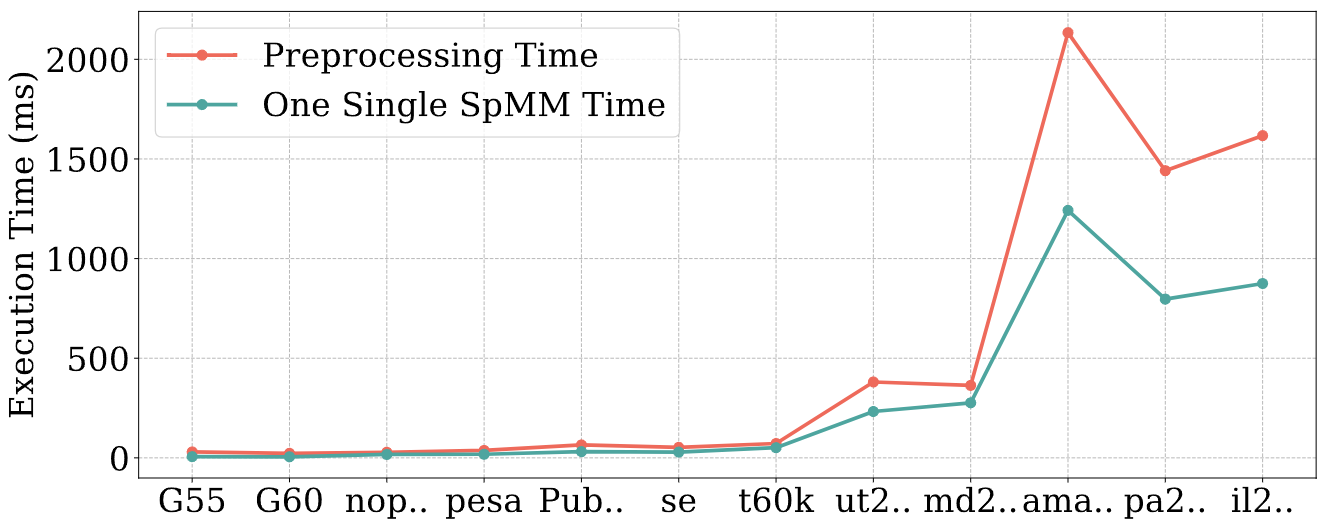
图 7:12个图矩阵上的预处理时间和单次SpMM执行时间的对比
结论:
本文中,我们在配备HBM的FPGA上提出了一种用于GNNs的高性能SpMM加速器Leda。采用分块稀疏格式的定制数据流充分利用了HBM的优势。最小相似度重排算法显著改善了累加阶段的RAW依赖。改进的外积数据流缓解了随机访存瓶颈。以MMU为中心的硬件架构设计进一步提高了并行性和数据重用性。实验结果表明,与当前最先进的SpMM加速器和GPU实现相比,Leda在吞吐量和能效方面展现出了显著的提升。
通讯作者简介:
金洲,副教授,中国石油大学(北京)计算机系副教授,入选北京市科协青年人才托举工程、校青年拔尖人才。主要从事集成电路设计自动化(EDA)、面向科学计算的DSA软硬件协同设计等方面的研究工作。主持并参与国家自然科学基金青年项目、重点项目,科技部重点研发微纳电子专项、高性能计算专项青年科学家项目,国家重点实验室开放课题、企业横向课题等。在DAC、TCAD、TODAES、SC、PPoPP、IPDPS、TCAS-II、ASP-DAC等重要国际会议和期刊上发表60余篇高水平学术论文。获EDA2青年科技奖、SC23最佳论文奖、ISEDA23荣誉论文奖、IEEJ九州支部长奖等。
联系方式:jinzhou@cup.edu.cn