
面向异构集群的大模型高吞吐量混合并行推理
中文题目:面向异构集群的大模型高吞吐量混合并行推理
论文题目:Hybrid Parallel Inference for Large Model on Heterogeneous Clusters for High Throughput
录用期刊/会议:IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS) 2023 (CCF C)
原文链接:https://ieee-cybermatics.org/2023/icpads/icpads-2023-accepted.htm
录用时间:2023年10月27日
作者列表:
1) 徐朝农 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机系教师
2) 孔维明 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机技术专业 硕 21
3) 刘 民 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕 21
4) 张明明 中国石油大学(北京)信息科学与工程学院/人工智能学院 计算机技术专业 硕 21
5) 李 超 之江实验室
6) 宫禄齐 之江实验室
文章简介:
深度学习技术在各种工业场景中被广泛使用以提高工作效率。在高吞吐量场景中,深度神经网络模型(DNN)的输入数据生成速度远快于其消耗速度。模型需要快速推理并尽可能快地做出实时决策。现有的模型推理加速方法,比如模型压缩、自适应推理和神经架构搜索,都是通过牺牲精度来减少模型推理所需的计算量。在不损失准确性的情况下,最有效的方法是数据并行(DP)推理。因为它可以同时处理多个批次,几乎可以线性增加推断速度。但是,数据并行的模型的大小受到设备内存的限制。对于无法由单一设备容纳的大型模型,通常使用流水线并行(PP)来加速过程。PP经常用于模型训练,并且也可以用于大模型推理。然而,PP中设备间的通信开销是主要的性能瓶颈,尤其是当PP中的阶段太多时。因此,DP或PP很难满足高吞吐量推断场景,我们必须结合这两种并行方法来开发一个合理的混合并行推理策略。而又由于近年来AI计算设备的快速迭代和进步,计算环境很可能包含具有不同计算能力、内存容量和通信带宽的设备以最小化成本。因此,异构集群的计算场景十分常见,这进一步加剧了寻找最佳混合并行策略的难度。
本文的主要内容如下:
(1)本文提出了一种混合并行推理策略,该策略将异构设备群集进行分组,执行组间数据并行、组内流水线并行。通过控制数据并行组数、组内设备分配和模型流水线分区比例,可以实现最短的推断时间。本文还基于该策略实现了一个高效的多设备调度推理运行时系统。
(2)提出了一种基于枚举和动态规划的最小化推理时延算法,用于生成最优的混合并行调度策略。
(3)在一个具有8块RTX3090的异构集群上的进行了实验评估,与PipeEdge相比,本文提出的混合并行策略的吞吐量提高了1.7倍到3.4倍。
摘要:
在高吞吐量智能计算场景中,基于数据并行或流水线并行的多设备并行策略已被广泛利用来加速大型深度神经网络模型推理。数据并行提供了几乎线性的推断速度改进,但它受到单个设备的内存容量限制,这限制了模型大小。另一方面,流水线并行可以支持更大的模型,但设备间激活数据的总通信量高,这限制了推理速度的提升。为了满足高吞吐量异构场景中模型高效推理的需求,本文提出了一种混合并行策略,结合了数据并行和流水线并行。该策略包括对异构设备群集进行分组,然后采用组间数据并行以及组内流水线并行推理。此外,本文提出了一种最小化单Batch推理时延的算法,以找到具有最大吞吐量的最优混合并行推理的调度方案。该算法的控制变量包括组的数量、组设备分配和模型分割比例。本文实验评估表明,与PipeEdge(一个针对异构集群的流水线并行推理框架)相比,本文的策略在一个拥有8块RTX 3090的异构集群中可以实现1.7倍到3.4倍的加速,且不损失模型精度。
设计与实现:
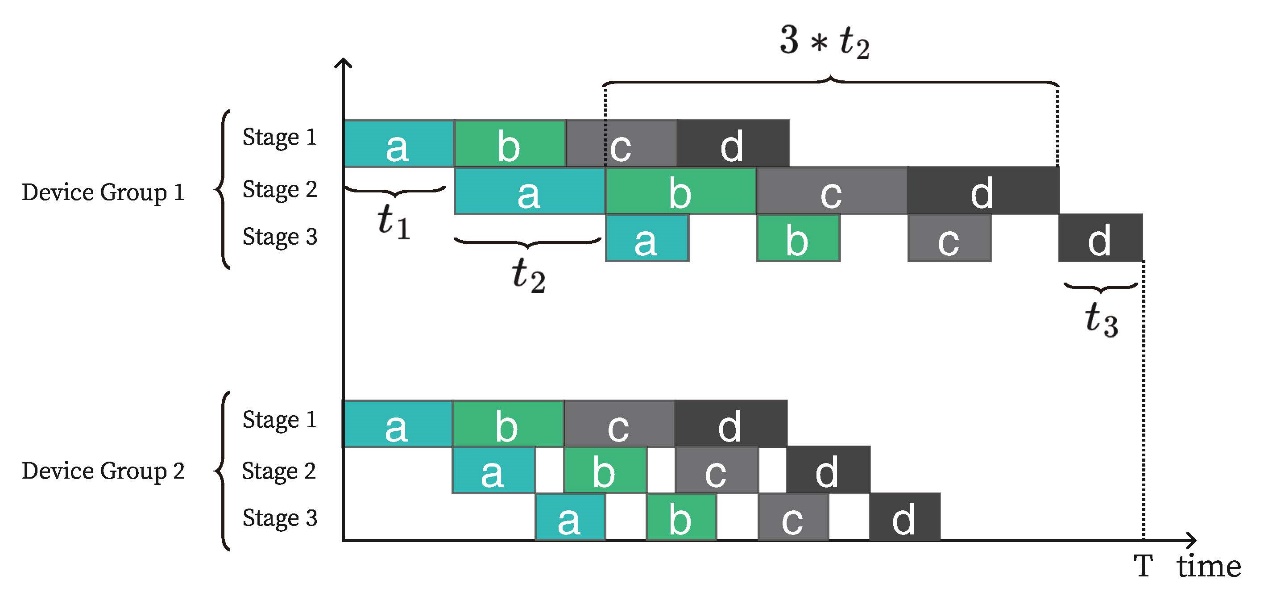
上图为组间数据并行组内流水线并行的混合并行推理的耗时示意图。通过分析可以发现耗时最长的数据并行组即为整个混合并行的推理耗时,而组内流水的微批数量也决定了组内的流水线并行的耗时。而通过优化最慢数据并行组并使其推理时间最短再找到最优的集群分组数就可以实现整个混合并行策略的最短推理时延。因此,可以建模为:
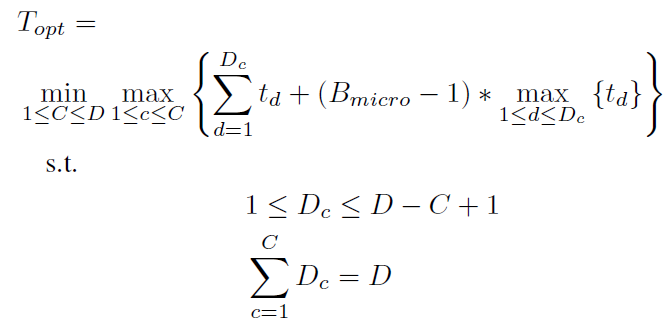
本文通过枚举的方法找到最优的设备分组数并配合第二斯特林数来找到各组的设备配置组合。然后通过三维动态规划来确定组内最佳的模型流水线划分方案。
由于现在的加速设备都为多核架构,因此,流水线并行推理时,每个设备的下一个微批计算任务和上一个微批的通信任务可以异步执行。本文取计算和通信的最大值为该设备上的推理耗时。本文将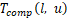 表示为在设备
表示为在设备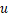 上执行层
上执行层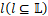 的计算时间。
的计算时间。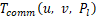 表示从设备
表示从设备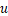 到设备
到设备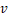 传输激活值数据
传输激活值数据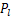 的通信时间。在确定异构设备集群被分为
的通信时间。在确定异构设备集群被分为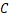 组,且第
组,且第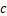 组包含的设备数量为
组包含的设备数量为![]() 之后,针对将
之后,针对将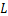 层DNN模型划分至每个数据并行组内的
层DNN模型划分至每个数据并行组内的![]() 台设备上以求最短推理时间的问题,可以转化为计算两个时间段最大值的问题。这两个时间段包括:在
台设备上以求最短推理时间的问题,可以转化为计算两个时间段最大值的问题。这两个时间段包括:在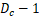 台设备上完成模型前
台设备上完成模型前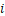 层推理的最短时间,以及在最后一台设备上完成模型剩余
层推理的最短时间,以及在最后一台设备上完成模型剩余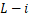 层推理的时间。通过进一步转化,模型分区问题可以转化为寻找在
层推理的时间。通过进一步转化,模型分区问题可以转化为寻找在![]() 台设备上对模型前
台设备上对模型前![]() 层进行推理所需的最短时间的子问题。基于子问题的最优分区结果,可以构建整个模型流水线分区方案的最优解。因此,该问题适合采用动态规划算法来解决,这种方法不仅提高了问题解决的效率,而且通过动态规划的策略,确保了在异构设备集群中实现DNN模型推理时的最优性能。为了解决每个数据并行组内的最优模型流水线分区问题,本文设计了一种三维动态规划算法,该算法记录了处理的子模型、使用的设备子集以及下一个流水线段所要使用的设备的所有状态。对于每个数据并行组中的
层进行推理所需的最短时间的子问题。基于子问题的最优分区结果,可以构建整个模型流水线分区方案的最优解。因此,该问题适合采用动态规划算法来解决,这种方法不仅提高了问题解决的效率,而且通过动态规划的策略,确保了在异构设备集群中实现DNN模型推理时的最优性能。为了解决每个数据并行组内的最优模型流水线分区问题,本文设计了一种三维动态规划算法,该算法记录了处理的子模型、使用的设备子集以及下一个流水线段所要使用的设备的所有状态。对于每个数据并行组中的![]() 台设备集合,让该组设备集合的所有子集
台设备集合,让该组设备集合的所有子集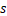 组成一个新的列表
组成一个新的列表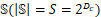 。
。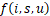 表示使用设备子集
表示使用设备子集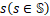 处理DNN模型前
处理DNN模型前![]() 层的最短推理时间并且流水线的下一个阶段使用设备
层的最短推理时间并且流水线的下一个阶段使用设备![]() 进行处理。
进行处理。![]() 是在设备子集
是在设备子集![]() 上推理前
上推理前![]() 层模型的最优解,即子问题的最优解,那么该分区问题的最终最优解为
层模型的最优解,即子问题的最优解,那么该分区问题的最终最优解为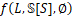 。进一步地,下一个状态
。进一步地,下一个状态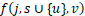 的计算需要使用最优子问题性质,该状态的模型推理时间由先前状态
的计算需要使用最优子问题性质,该状态的模型推理时间由先前状态![]() ,或者在设备
,或者在设备![]() 上执行模型的第
上执行模型的第![]() 层到第
层到第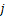 层的计算时间
层的计算时间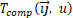 ,或者通信时间
,或者通信时间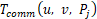 决定,组内模型分区算法的状态转移方程可以表述为:
决定,组内模型分区算法的状态转移方程可以表述为:
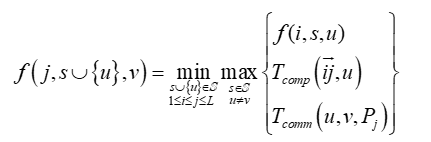
通过上述方法可以确定组间数据并行组内流水线并行的混合并行推理系统的最优数据并行组数、每个组内设备的数量与类型、设备的排序以及模型在各设备间的分配方案。
实验结果及分析:
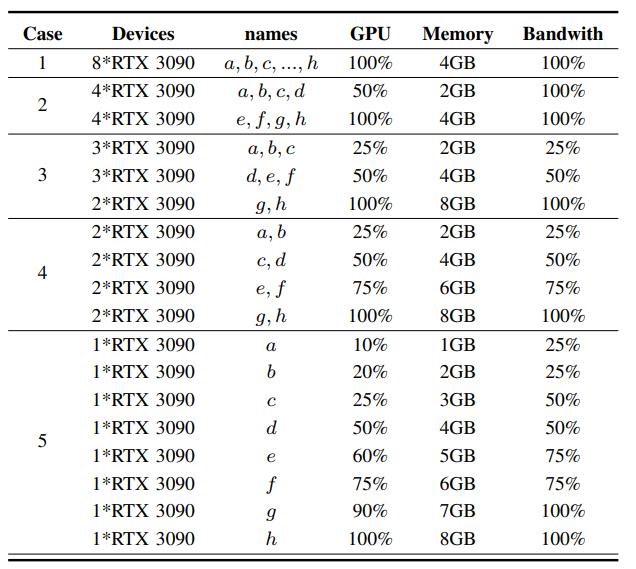
本文在8块RTX3090的集群上进行实验,通过软件工具限制其算力、带宽和内存将其设置为异构集群。下表展示了五种异构性逐渐增加的集群配置。
本文利用ViT-Large和ViT-Huge模型在五种异构配置下进行实验并和PipeEdge进行对比,实验结果如下:
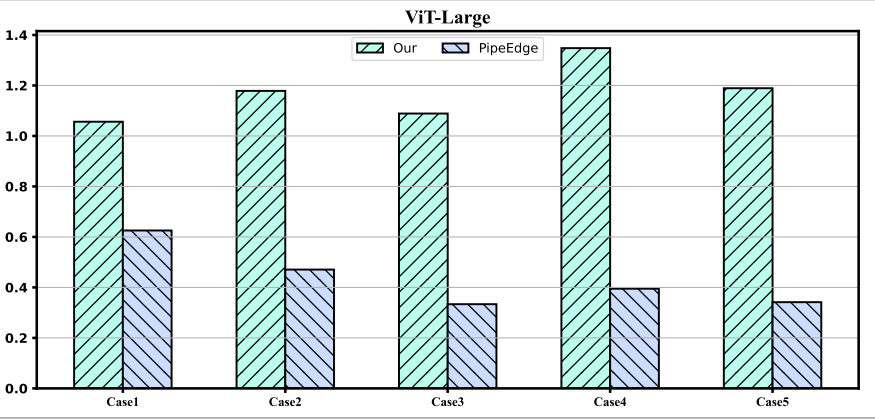
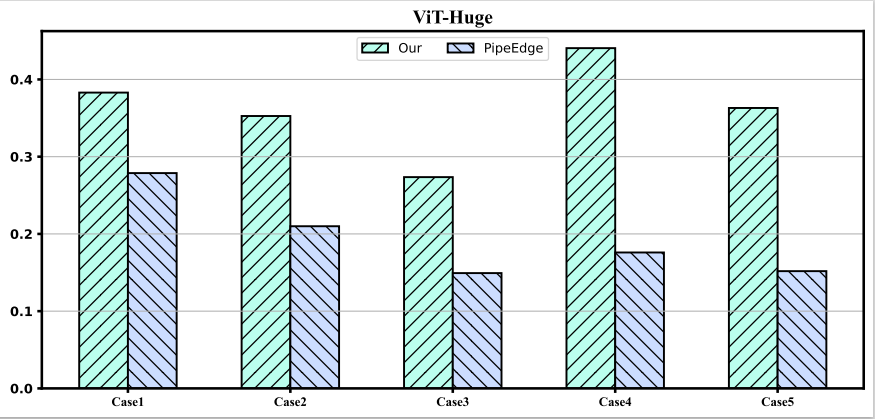
本文提出的多设备并行策略在每种异构情况下都优于PipeEdge,并且有1.7倍到3.4倍的提升。
结论:
本文提出的组间数据并行组内流水线并行的混合并行策略可以很好地适用于异构集群的大模型推理场景,并本文提出的算法可以感知大模型的最大峰值内存占用,可以分配最优的数据并行组数来大幅提升推理吞吐量。相关算法和多设备混合并行运行时系统可在https://github.com/kongweiming/hybrid_parallel_runtime获取。
作者简介:
徐朝农,博士,中国石油大学(北京)信息科学与工程学院/人工智能学院教师,主要研究领域为边缘智能、嵌入式系统、无线网络。