
加权k最近邻图拉普拉斯矩阵分解的不平衡样例选择
中文题目:加权k最近邻图拉普拉斯矩阵分解的不平衡样例选择
论文题目:Imbalanced Instance Selection Based on Laplacian Matrix Decomposition with Weighted k Nearest Neighbor Graph
录用期刊/会议:Neural Computing and Applications (中科院SCI 3区,JCR Q2)
原文DOI:https://doi.org/10.1007/s00521-024-09676-0
原文链接:https://link.springer.com/article/10.1007/s00521-024-09676-0
录用/见刊时间:2024.04.22
作者列表:
1)代 琪 中国石油大学(北京)信息科学与工程学院/人工智能学院 控制科学与工程 博20
2)刘建伟 中国石油大学(北京)信息科学与工程学院/人工智能学院 自动化系 教师
3)王龙辉 华北理工大学 理学院
摘要:
数据是构建机器学习模型的基本组成部分。线性可分的高质量数据有利于构建高效的分类模型。但是,在现实世界中,采集的数据并不是高质量的,他们的每个类的样本数量并非绝对一致。因此,在这些数据集上构建的模型容易受到类不平衡、类重叠和噪声等问题的影响。传统的样本选择算法主要是根据样本之间的近似程度,判断样本是否存在冗余或重叠。因此,这些方法只关注了数据集的局部信息,忽略了样本在数据集中的全局近似关系。在本文中,提出一种根据样本在数据集中的全局关系的样本选择方法,称为加权近邻图拉普拉斯矩阵分解的样本选择方法(LMD-WNG)。首先,该方法尝试使用加权k最近邻图构建一个新的距离加权拉普拉斯矩阵。然后,使用矩阵分解方法分解距离加权拉普拉斯矩阵。最后,根据分解后的实矩阵的特征值选择适合模型学习的训练数据集,并在新的训练数据集上构建分类器。
背景与动机:
目前已经提出了大量的处理类不平衡问题的预处理技术。部分研究者认为,过采样技术比欠采样技术更有效。然而,我们认为这样的描述并不全面,并不是在所有数据集上,过采样技术都是最优的方法。不妨简单的思考一下,当少数类样本过于稀疏且与多数类样本存在重叠时,直接使用传统的过采样技术,生成的人工样本仍然与多数类重叠,不利于传统分类器学习数据集的分类边界。除此之外,在实验室中使用过采样可能会提高评价指标的结果。在实际应用领域中,生成的伪少数类样本很可能不能代表实际的样本,导致分类模型无法识别新的未知样本。因此,我们认为对于重采样技术中的过采样技术和欠采样技术,他们之间并非占有绝对的优势,而是应该针对不同的问题共同发展。
拉普拉斯矩阵是图论中的常用方法。我们尝试将拉普拉斯矩阵的思想引入样本选择或欠采样技术中,解决类不平衡问题。使用度量学习方法,构建相似矩阵,利用正负惯性趋势搜索数据集的全局相似度趋势,从而实现数据集的欠采样。我们认为在数据集中越相似的不同类的样本越容易成为数据集中的重叠样本。
此外,k最近邻图的边并没有权重,当生成拉普拉斯矩阵时,我们直接将邻接矩阵中对应位置标注为1。使用这样的做法有一个潜在的假设,即认为与顶点连接的样本的权重是相同的,这样并不利于分辨近邻图中相邻样本点的距离远近。因此,我们使用距离度量的方式,计算出相邻样本之间的距离,将其作为k最近邻图中对应边的权重,并使用加权k最近邻图生成拉普拉斯矩阵。
设计与实现:
提出的加权k最近邻图拉普拉斯矩阵分解的样例选择(LMD-WNG)流程图如下所示。
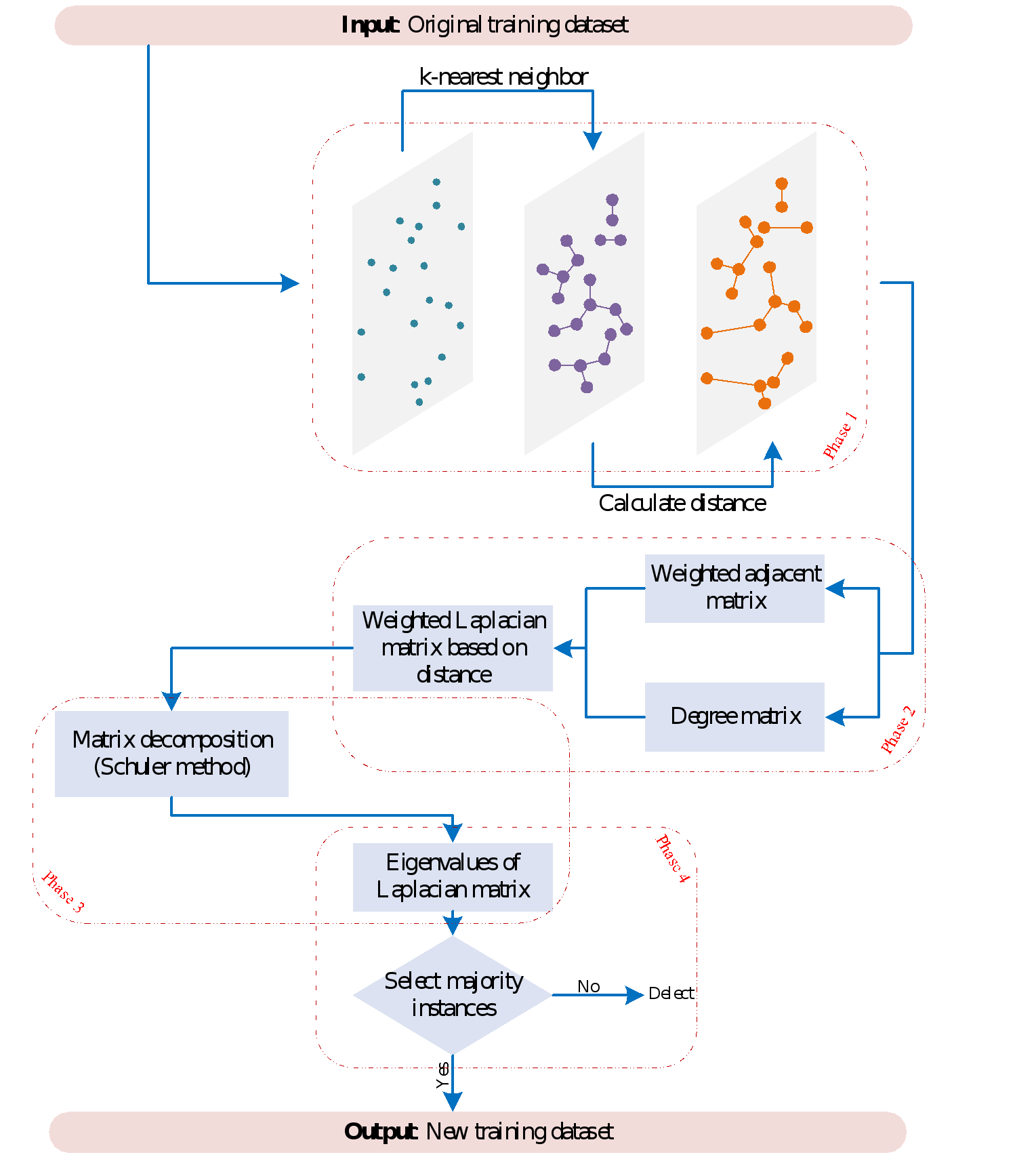
主要内容:
LMD-WNG是一种结合拉普拉斯矩阵和矩阵分解技术的样本选择方法,据我们所知,该方法是首次在类不平衡问题上结合拉普拉斯矩阵和矩阵分解技术的新方法。该方法分为四个阶段:构建k最近邻图、计算标准加权拉普拉斯矩阵、矩阵分解(Schur分解)和样本选择。
在第一阶段中,我们使用k最近邻方法搜索样本空间并形成最近邻图。
第二阶段则是根据k最近邻图计算邻接矩阵和度矩阵,并计算k最近邻图的标准加权拉普拉斯矩阵。
Schur分解则是在第三阶段进行,这个阶段主要是分解标准加权拉普拉斯矩阵,获取标准加权拉普拉斯矩阵对应的特征值。
第四阶段,样本选择则是根据拉普拉斯矩阵中对应位置的特征值的大小选择多数类中的样本。最后,将选择的多数类样本与训练集中的少数类样本合并,形成新的训练集。
实验结果及分析:
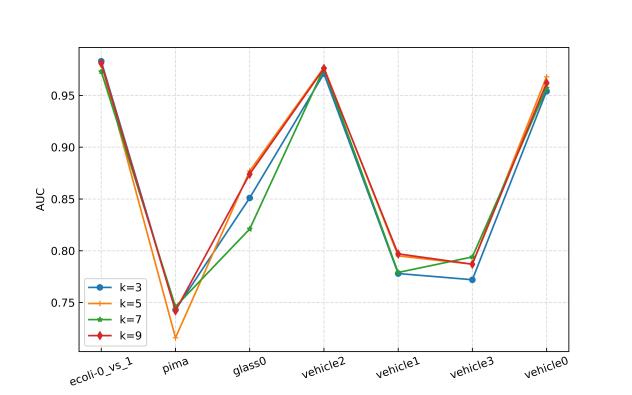
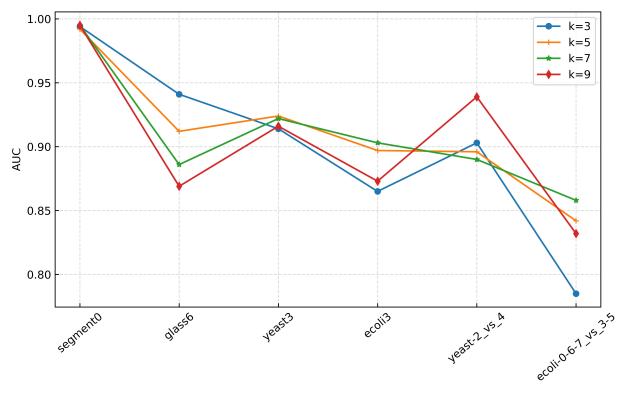
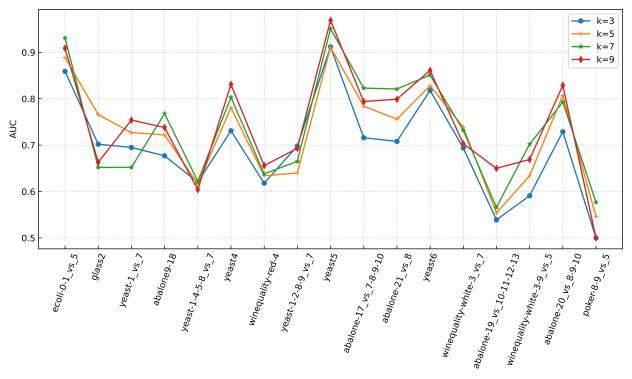
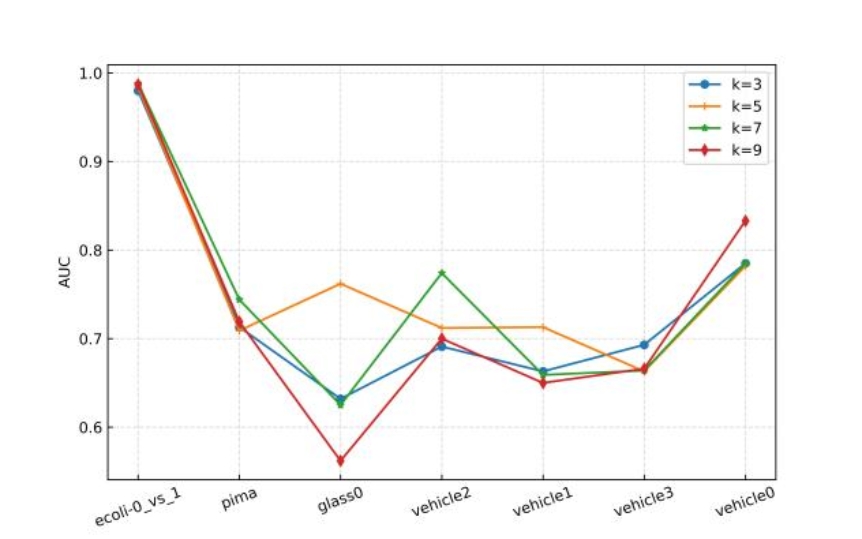
在30个不平衡数据集上进行参数敏感实验,并与其他先进方法进行对比实验,实验结果如下所示。
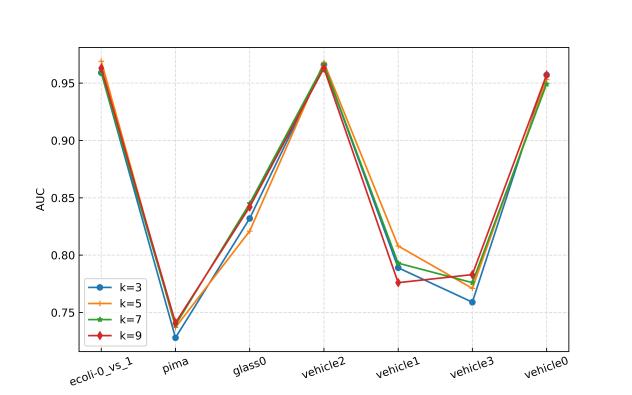
(a)轻度不平衡
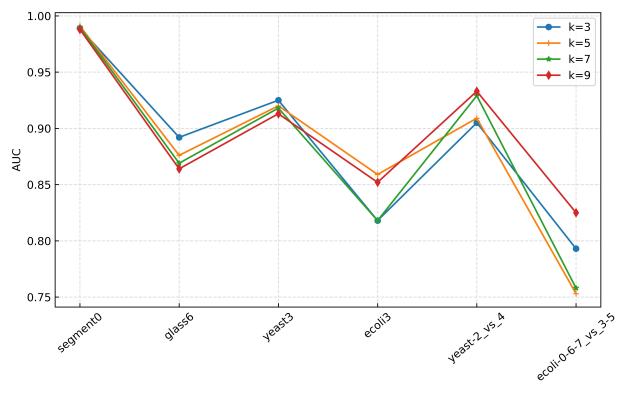
(b)中度不平衡
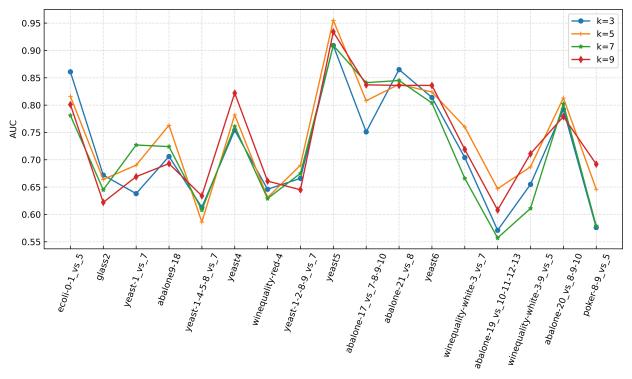
(c)高度不平衡
图1 使用GBDT时的参数敏感性分析
(a)轻度不平衡
(b)中度不平衡
(c)高度不平衡
图2 使用RF作为基分类器时的参数敏感性分析
(a)轻度不平衡
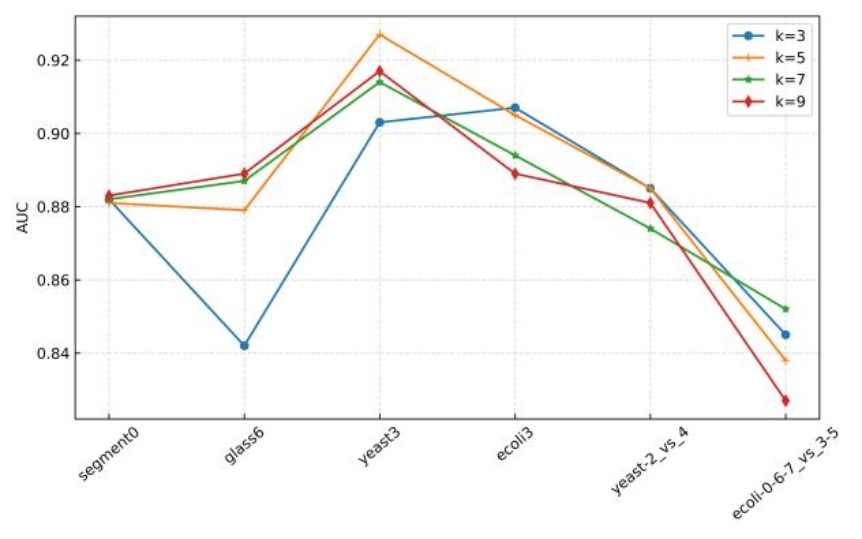
(b)中度不平衡
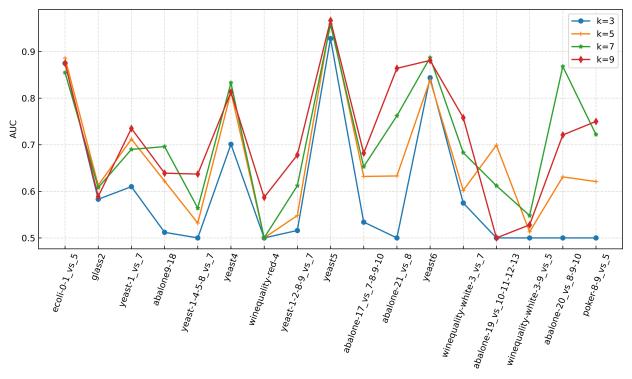
(c)高度不平衡
图3 使用SVM作为基分类器时的参数敏感性分析
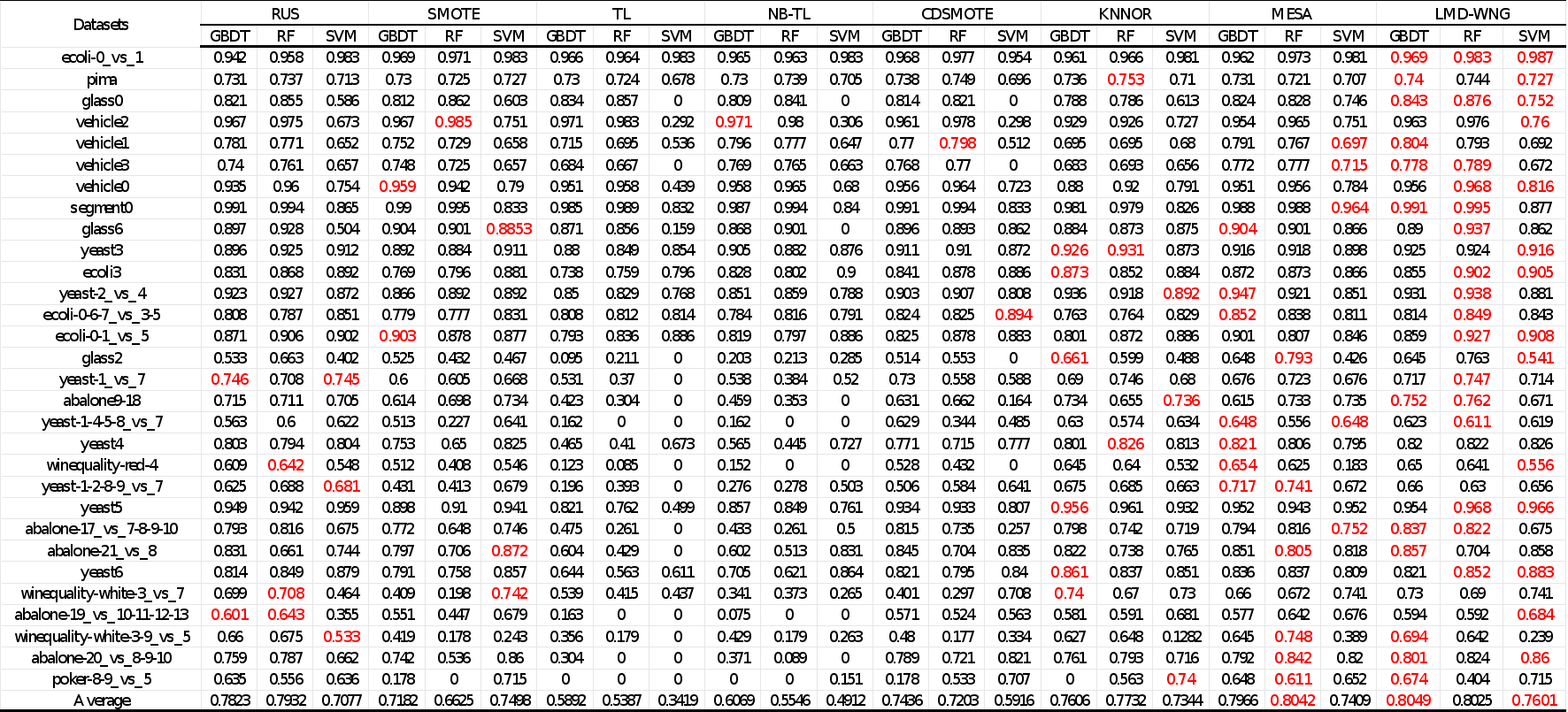
与先进样本选择或数据增强方法的对比实验结果如下所示:
表1 使用AUC评估模型时的性能结果

表2 使用G-mean评估模型时的性能结果
结论:
样本选择算法是解决类不平衡问题的研究方法之一,需要根据数据集中的样本信息,选择信息量较大的样本加入训练集。当数据集中少数类样本数量较多时,可以使用传统的重采样技术增强少数类或删除多数类,但是当数据集中的少数类样本较少时,需要筛选训练集中的多数类样本,从而提高模型的整体性能。对于高度不平衡数据集,LMD-WNG的性能更加稳定,并不会受到类不平衡问题的影响。然而,LMD-WNG样本选择算法的性能将会随着数据集不平衡比的增加而变得对超参数k更加敏感。因此,需要更高效的参数选择方法确定超参数。LMD-WNG是首次将数据转化为图结构并选择样本的算法。因此,在未来的工作中,可以将它与其他方法结合使用,并且能够充分探索根据数据结构选择样本。
通讯作者简介:
刘建伟,教师,学者。研究领域涉及在线学习(包括强化学习,赌博机算法,持续学习,长尾学习);图像视频显著性目标检测,解纠缠表示学习,光场和神经场模型,以及图像视频少样本变化检测;自然语言理解中的知识补全,图神经网络;不平衡数据处理;霍克斯点过程故障预测与诊断;非线性预测与控制。 是兵器装备工程学报第三届编辑委员会委员。历届中国控制会议(CCC)和中国控制与决策会议(CCDC)的程序委员会委员。担任过80多个国际会议的TPC。