
通过深度强化学习设计联邦学习的安全服务契约激励机制
中文题目:通过深度强化学习设计联邦学习的安全服务契约激励机制
论文题目:Secure Service-Oriented Contract Based Incentive Mechanism Design in Federated Learning via Deep Reinforcement Learning
录用期刊/会议:IEEE 2024 International Conference on Web Services (ICWS) (CCF B)
录用时间:2024年5月14日
作者列表:
1) 马博闻 中国石油大学(北京) 信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
2) 冯子涵 中国石油大学(北京) 信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕22
3) 高煜洲 中国石油大学(北京) 信息科学与工程学院/人工智能学院 计算机科学与技术专业 本20
4) 陈 莹 北京信息科技大学 计算机学院 教授
5) 黄霁崴 中国石油大学(北京) 信息科学与工程学院/人工智能学院 教授
摘要:
在联邦学习中,确保本地模型所有者的积极参与,同时保护数据隐私和服务安全是一项艰巨的挑战。我们的研究集中于两种不同的信息场景:弱不完全信息场景和强不完全信息场景,它们对联邦学习系统的完整性和效率提出了独特的挑战。在弱不完全信息场景中,我们需要解决本地模型所有者可能隐瞒其真实类型的问题。为此,我们使用契约理论及其自我揭示特性,确保本地模型所有者如实报告其类型。在强不完全信息场景中,我们认识到本地模型所有者的动态性质及其隐私需求。我们提出了基于契约的深度强化学习(Contract-based Deep Reinforcement Learning, CDRL)算法,该算法结合了契约理论的战略框架和深度强化学习的自适应能力。CDRL算法旨在动态环境中进行实时契约设计,使系统能够有效应对联邦学习的参与,确保激励措施与系统安全和学习目标保持一致。通过在真实世界数据集上的广泛实验,我们提出的机制在激励本地模型拥有者积极参与联邦学习方面表现出色,从而显著提高了系统性能。
背景与动机:
为了充分发挥联邦学习模型的价值,我们需要建立合理的激励机制,以确保系统参与者能够自愿、无私地完成高质量的数据计算工作。这一激励机制应能够量化不同任务的工作量,并匹配相应的奖励,从而实现本地模型拥有者和任务发布者的利益最大化。由于本地模型拥有者通常不会向公众披露其具体信息,因此实际应用场景多为信息不对称。然而,在现有研究中,激励机制都是在本地模型拥有者分布已知、本地模型拥有者数量不变的假设下,利用凸优化理论和契约理论进行优化设计的。此外,在本地模型拥有者分布未知且数量动态变化的情况下,激励机制的设计基本没有研究。
主要内容:
在这个框架中,我们有一个任务发布者,他将召集一些具有计算能力的本地模型拥有者来完成模型训练。具体来说,本地模型拥有者会根据其参与意愿,使其模型训练在数量和质量上有所不同。因此,我们根据参与意愿的不同对所有本地模型拥有者进行分类。在不失一般性的前提下,意愿越高,表明本地模型拥有者可以提供更高质量或更多的数据,为任务做出更大贡献,系统模型如如图 1 所示。
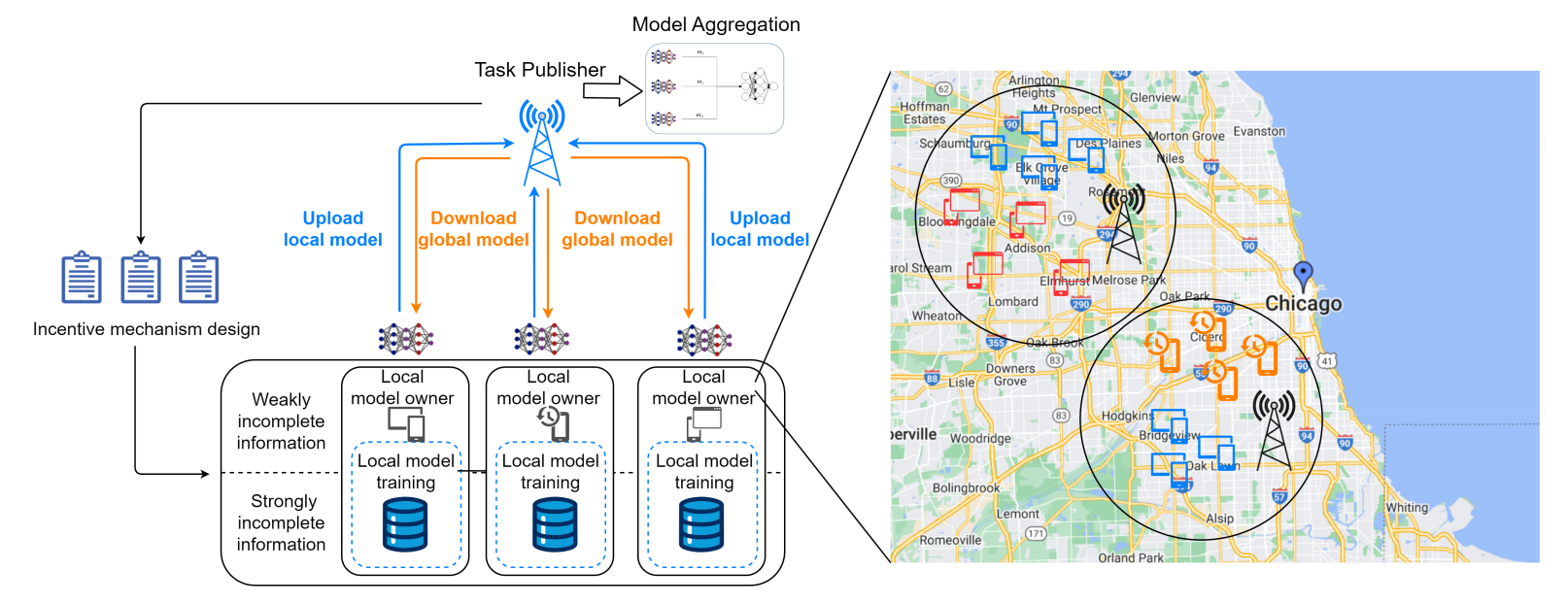
图1 系统模型
为了激励本地模型拥有者自愿无私地完成一定数量的任务,任务发布者需要设计合理有效的激励机制。本地模型拥有者有动机隐藏自己的类型,假装成其他类型的本地模型拥有者,以获取更高的回报。此外,由于本地模型拥有者的意愿作为单个本地模型拥有者的私有数据没有公开,因此任务发布者无法明确知道每个本地模型拥有者的具体类型。本地模型拥有者是自私而理性的,他们会在任务发布者提供的契约中选择自身利益最大化的契约。任务发布者的效用由两部分组成,即从模型训练中获得的收益和支付给本地模型拥有者的成本;本模型拥有者的效用由两部分组成,即从任务发布者的奖励和其模训练成本。定义为
![]()
![]()
在弱不完全信息情景中,本地模型拥有者的类型属于私人信息,任务发布者不知道具体的本地模型拥有者的类型。为了防止本地模型拥有者为了获得更高的效用而想隐瞒自己的类型,我们利用契约理论来解决这个激励不对称问题。通过契约理论,我们可以将原始优化问题简化为以下形式:
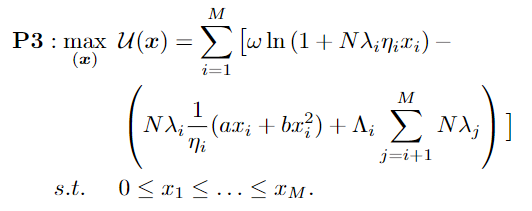
利用凸优化工具,我们可以轻松得出最优契约设计问题的最优解,而无需考虑单调性条件的约束。当本地模型拥有者的概率分布是均匀分布时,解自然满足单调性约束条件。否则,解有可能不满足单调性约束。我们需要进一步检查解的单调性约束,使用“Bunching and Ironing”调整算法来解决不可行子序列问题。

然而,在现实中,本地模型拥有者的数量和分布可能是动态的。本地模型拥有者的位置并不固定,可能会跨区域移动。此外,本地模型拥有者也可能遇到不可预见的故障和其他不可预测的事件。鉴于本地模型拥有者的动态性质和隐私问题,我们建立了一个马尔可夫决策过程(MDP)模型,并提出了一种深度强化学习算法CDRL,以应对强不完全信息场景的挑战。

实验结果及分析:
我们设计了大量模拟实验,以评估弱不完全信息情景下契约设计的最优性,以及强不完全信息情景下CDRL的性能。我们利用真实世界的数据Chicago Taxi Trips-2021进行实验。通过使用K-means算法进行区域划分,划分结果如图2所示。
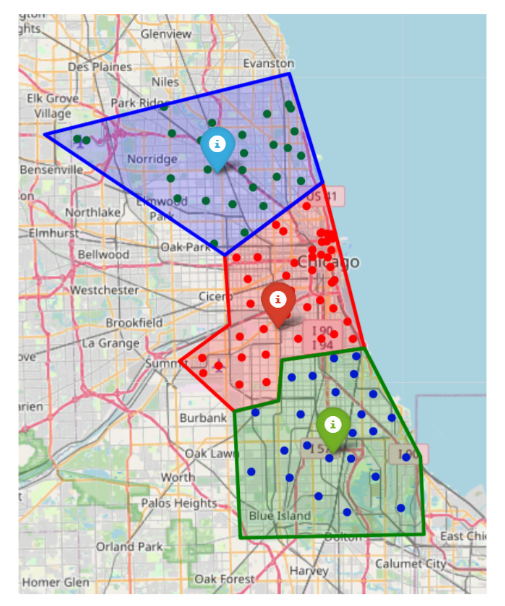
图2 Chicago Taxi Trips – 2021
图3显示了本地模型拥有者在选择任务发布者设计的不同契约条目时的效用。
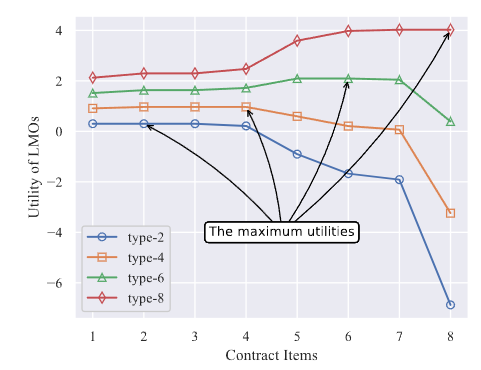
图3 本地模型拥有者的效用
图4展示了四种 DRL 算法的收敛性和性能。
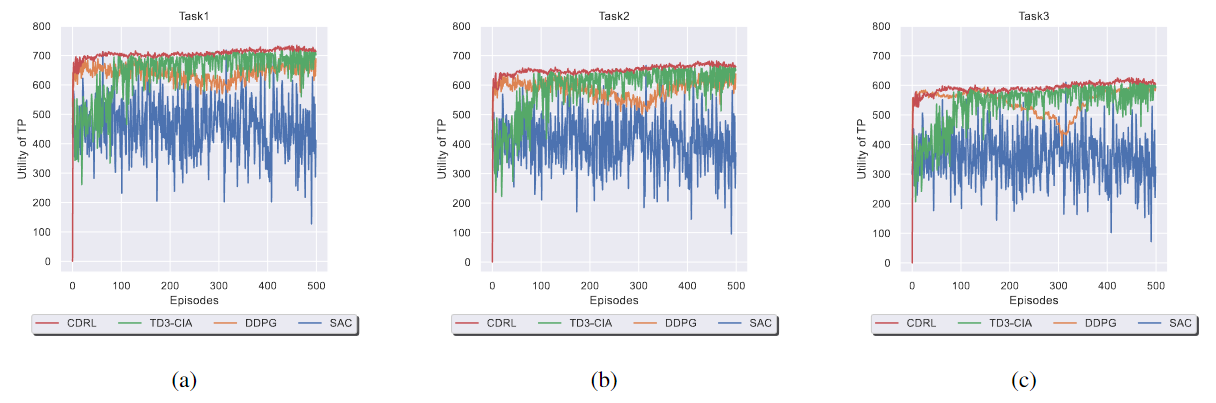
图4 随着训练回合数变化对性能的影响
(a) 任务1. (b) 任务2. (c) 任务3
结论:
在联邦学习场景中,我们解决了如何在确保本地模型拥有者积极参与的同时维护隐私和安全的难题。我们探讨了弱不完全信息和强不完全信息的场景,在前者中引入了契约理论等解决方案,在后者中引入了用于动态自适应的CDRL算法。我们的方法经过真实世界数据的验证,显著提高了本地模型拥有者的参与度和系统性能,展示了将博弈框架深度强化学习算法相结合以改进联邦学习系统的潜力。在今后的研究中,我们将改进本地模型拥有者的分类,以详细了解他们在联邦学习中的不同特点和作用。此外,我们还将探索使用包含离散和连续混合行动空间的深度强化学习算法,以改进激励机制的设计和灵活性。
通讯作者简介:
黄霁崴,教授,博士生导师,中国石油大学(北京)信息科学与工程学院/人工智能学院副院长,石油数据挖掘北京市重点实验室主任。入选北京市优秀人才、北京市科技新星、北京市国家治理青年人才、昌聚工程青年人才、中国石油大学(北京)优秀青年学者。本科和博士毕业于清华大学计算机科学与技术系,美国佐治亚理工学院联合培养博士生。研究方向包括:物联网、服务计算、边缘智能等。已主持国家自然科学基金、国家重点研发计划、北京市自然科学基金等科研项目18项;以第一/通讯作者在国内外著名期刊和会议发表学术论文60余篇,其中1篇获得中国科协优秀论文奖,2篇入选ESI热点论文,4篇入选ESI高被引论文;出版学术专著1部;获得国家发明专利6项、软件著作权4项;获得中国通信学会科学技术一等奖1项、中国产学研合作创新成果一等奖1项、广东省计算机学会科学技术二等奖1项。担任中国计算机学会(CCF)服务计算专委会委员,CCF和IEEE高级会员,电子学报、Chinese Journal of Electronics、Scientific Programming等期刊编委。
联系方式:huangjw@cup.edu.cn