
基于扩散模型和知识蒸馏技术的时间序列插补方法
中文题目:基于扩散模型和知识蒸馏技术的时间序列插补方法
论文题目:Diffusion Modeling and Transformer Knowledge Distillation Techniques for Time Series Imputation
录用期刊/会议:2024中国自动化大会 (CAA A类会议)
录用时间:2024.9.20
作者列表:
1) 阮丹灵 中国石油大学(北京)人工智能学院 控制工程 硕22级
2) 刘建伟 中国石油大学(北京)人工智能学院 自动化系 教师
摘要:
近年来,大数据分析十分热门,但数据在收集、存储等过程中常常会出现缺失的现象,进而影响到数据分析的效果。因此,本文提出用扩散模型来插补时间序列的缺失值,并且加入了Transformer结构来捕捉时间序列数据中的复杂依赖关系,为了提高插补的准确性,还将知识蒸馏用于扩散模型的逆向过程。我们在医疗数据集和空气质量数据集上进行了实验,比较了不同缺失值占比的情况下,模型的表现。结果表明,我们的模型在三个评价指标上均优于其他模型。
背景与动机:
近年来,大量的数据被用于分析和决策,许多领域用时间序列数据进行预测分析,例如,预测股票的价格,预测天气,预测医疗诊断,预测实时交通。但是收集的数据往往会存在缺失,时间序列数据的不完整会导致时间序列的建模出现偏差,进而影响到对时间序列数据分析的结果不准确,因此对时间序列的缺失值的处理也成为一个很重要的问题。缺失值的常用处理方法通常有删除法和插补法两种,但是删除会导致数据一些分布特征的丢失,对后续的时间序列数据的处理造成不良影响,所以如何用更准确的方法来对缺失数据进行填补是目前的热点问题。
主要内容:
本文选取了扩散模型作为时间序列缺失值插补的基础模型,并且在此基础上加入了Transformer和知识蒸馏,将其作为扩散模型反向去噪过程的一部分。用Transformer来捕捉时间序列之间的特征依赖和时间依赖关系。用知识蒸馏来指导去噪过程,将学生模型的去噪函数作为扩散模型的去噪函数,将学生模型和教师模型之间的预测噪声的差作为知识蒸馏的损失函数,并且将知识蒸馏的损失函数作为总损失函数的正则化项。将模型用于医疗和空气质量数据集,并且和基线进行比较实验,得到本文的模型插补的准确率大于基线的准确率。最后,讨论了本文的优势和不足之处,并且提出了之后应该如何改进。
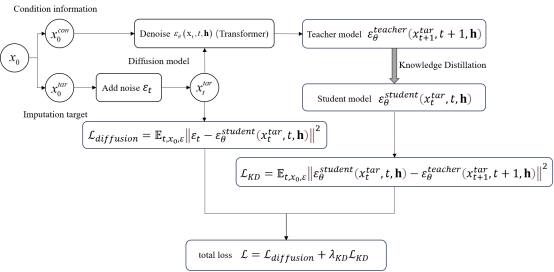
图2. 基于扩散模型和知识蒸馏的插补模型结构图
结论:
本文提出了一种扩散模型和知识蒸馏的时间序列插补的模型框架。该框架通过在扩散模型的反向过程中加入transformer,捕捉时间序列数据中的复杂依赖关系,提高模型的表现能力。通过引入条件信息,Transformer在去噪过程中能够考虑更多的上下文信息,从而提高预测精度。通过学习教师模型的预测,学生模型能够更快地收敛并获得更高的预测精度。此外,我们在医疗和空气质量数据上做了对比实验。结果表明,本文提出的框架更能准确的填补时间序列的缺失值,插补准确性更强。我们的研究仍有改进的余地。目前的研究仅仅在扩散模型反向过程中加入了最简单的知识蒸馏方法,未来的工作可以尝试更为复杂的知识蒸馏,并将其应用在扩散模型的不同环节。
作者简介:
刘建伟,教师,学者。