
移动边缘计算中隐私保护的任务卸载方法:一种基于深度强化学习的方法
中文题目:移动边缘计算中隐私保护的任务卸载方法:一种基于深度强化学习的方法
论文题目:Privacy-preserving task offloading in mobile edge computing: A deep reinforcement learning approach
录用期刊/会议:Software: Practice and Experience (CCF B, JCR Q2)
原文DOI:10.1002/spe.3314
原文链接:https://onlinelibrary.wiley.com/doi/10.1002/spe.3314
录用/见刊时间:2024年01月23日
作者列表:
1) 夏方略 中国石油大学(北京) 信息科学与工程学院/人工智能学院 计算机科学与技术专业 硕21
2) 陈 莹 北京信息科技大学 计算机学院 教授
3) 黄霁崴 中国石油大学(北京) 信息科学与工程学院/人工智能学院 教授
随着机器学习技术的不断演进,对训练数据的需求也在不断上升。通过移动群智感知的方式,从大量的终端用户中收集数据,能够有效改善模型性能与泛用性。然而,用户也会关注数据的隐私性,不愿意轻易提供隐私数据。因此,隐私保护是一个非常关键的问题。在机器学习中,联邦学习是一种常见的隐私保护方法,其通过在数据所有者本地完成模型训练过程的方式来保护隐私。然而,考虑到移动用户终端设备的计算能力与电池续航有限,随着模型复杂度的上升,这些设备无法支撑大量的模型训练计算任务。随着移动边缘计算技术的发展,用户能够将模型训练计算任务卸载到边缘服务器中,通过用户设备、边缘服务器同时训练的方式加速训练过程。然而,边缘服务器并非完全可行,在隐私数据上传与训练的过程中仍然会有隐私泄漏风险。为了解决这一问题,本文建立了一个使用移动边缘计算的分布式机器学习系统,建立了系统模型,设计了基于本地差分隐私的隐私保护算法,并提出了基于深度强化学习的任务卸载算法。上述算法不仅可以加速机器学习模型训练过程,还可以保护用户隐私并节约用户电量。最后,本文通过实验的方式验证了上述算法的有效性。
通过移动群智感知的方式从大量的用户移动终端中收集数据,能够有效改善模型的性能与泛用性。然而,传统的机器学习方法会将用户数据上传到云服务器中,不利于保护用户隐私。同时,联邦学习虽然能保护隐私,但用户设备的计算能力有限。因此,需要一种同时兼顾隐私性与效率的方法。
本文首先对本文首先提出了一个使用移动边缘计算的隐私保护分布式机器学习系统,该系统由多台用户移动终端设备、多台边缘服务器、单台云服务器组成。上述系统的工作流程如图1所示,首先用户会采集数据,然后在用户设备与边缘服务器同时进行机器学习模型训练过程,最后在云服务器聚合全局模型。
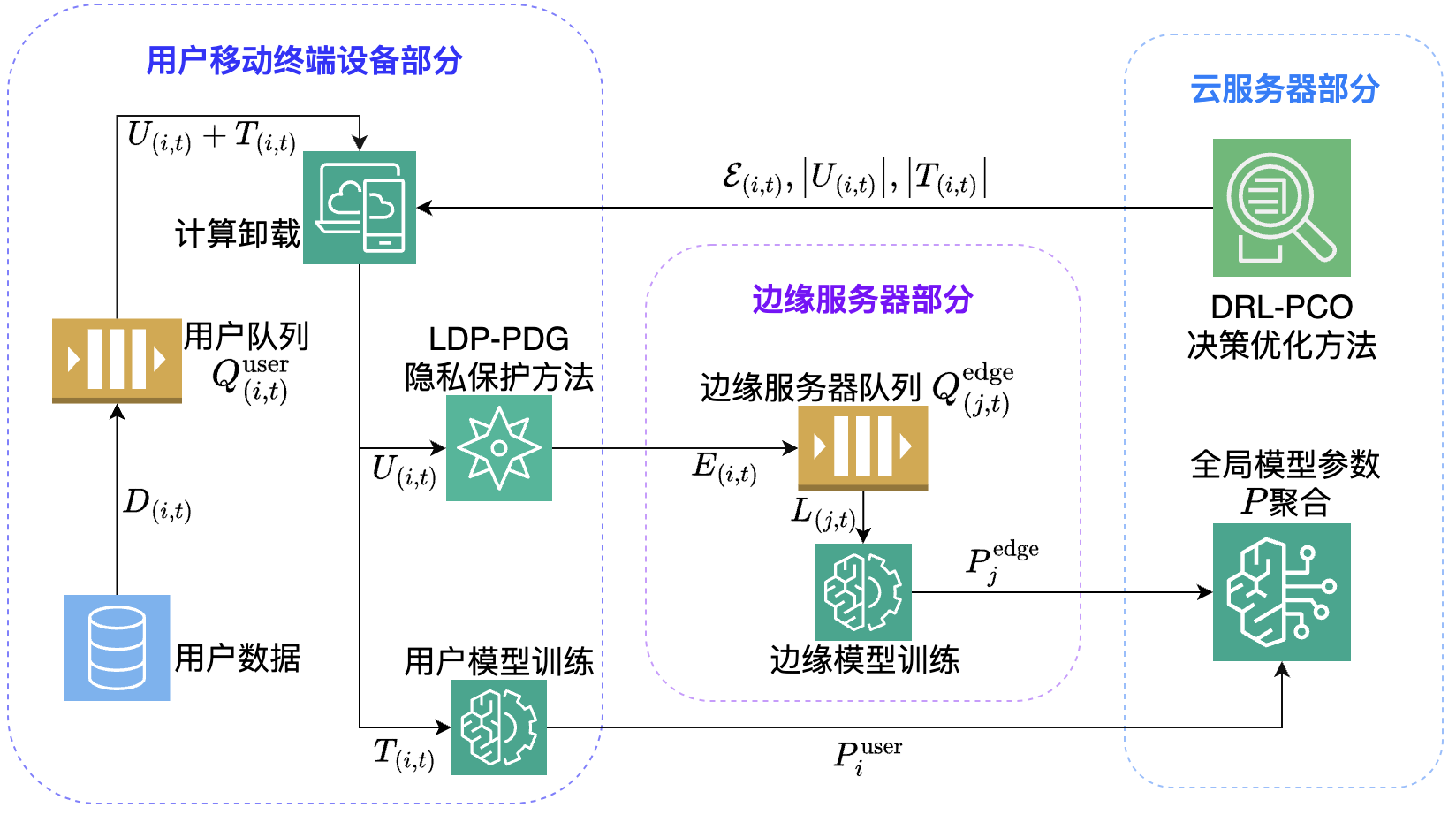
图1 系统工作流程
为了解决数据传输与模型训练过程中的隐私保护问题,本文提出了一种基于本地差分隐私的隐私保护算法(LDP-PDG),会通过拉普拉斯机制保护数据隐私性,能提供ϵ-DP。算法流程示意图如图2所示。
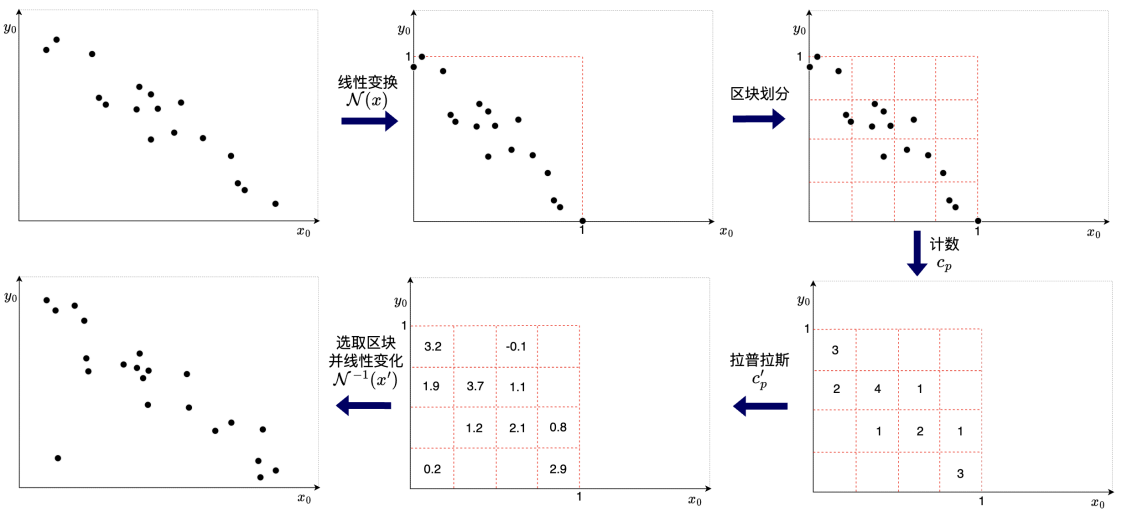
图2 隐私保护算法工作流程
然后,本文对上述分布式机器学习系统的训练任务排队过程、隐私保护传输过程、机器学习训练过程、移动设备电量消耗过程进行建模,将任务卸载的优化问题规约为:
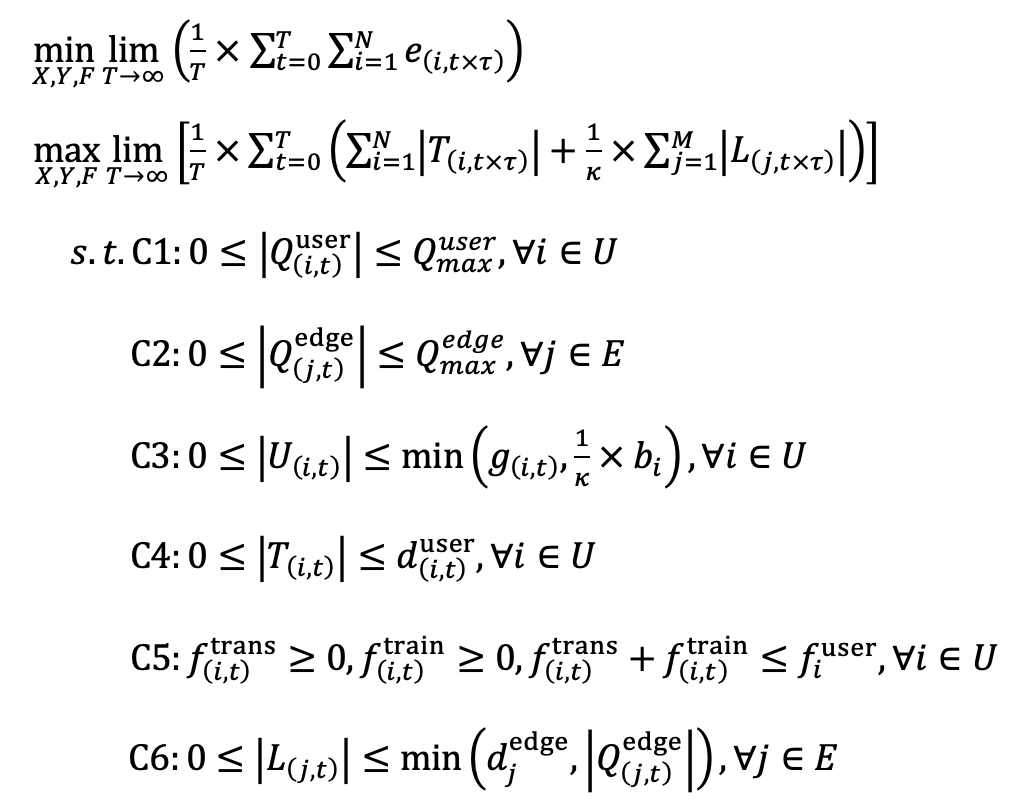
为了优化上述分布式机器学习系统的性能,本文针对移动边缘计算中的任务卸载问题提出了一种基于深度强化学习的优化算法(DRL-PCO),通过Actor与Critic的双网络方式学习知识。该算法的架构图如图3所示。
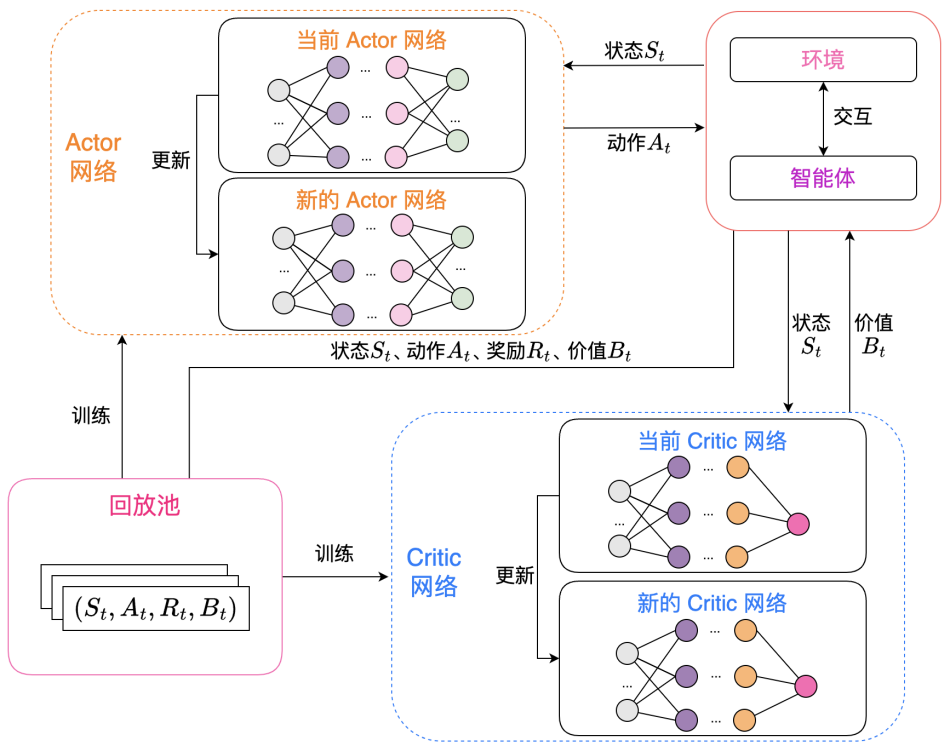
图3 任务卸载算法架构图
实验结果及分析:
在实验中,本文采取了平均训练计算量、训练任务丢弃量、移动设备平均能耗三个指标,将本文提出的方法与DDPG算法、贪心算法(GA)、联邦学习(FL)方法进行对比。
首先进行的是相同边缘服务器数量与用户移动终端设备下的对比,可以看出本文提出的方法优势明显
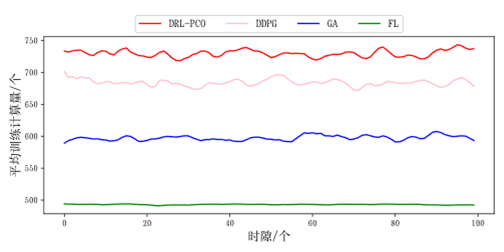
图4 平均训练计算量(相同用户数量与边缘服务器数量)
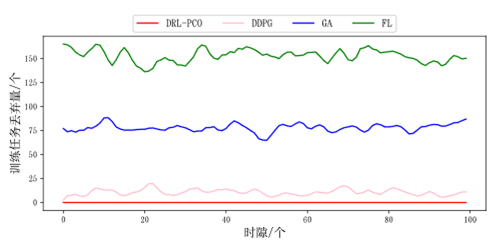
图5 训练任务丢弃量(相同用户数量与边缘服务器数量)
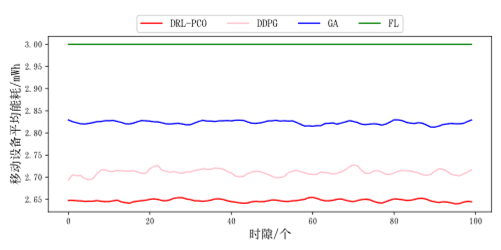
图6 移动设备平均能耗(相同用户数量与边缘服务器数量)
然后,还对比了不同边缘服务器下的情况,通过箱线图来展示数据。
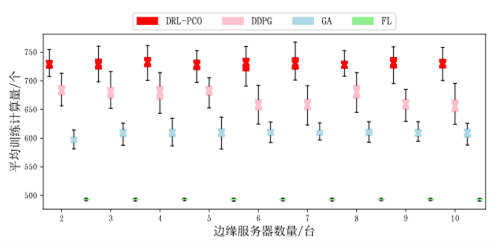
图7 平均训练计算量(不同边缘服务器数量)
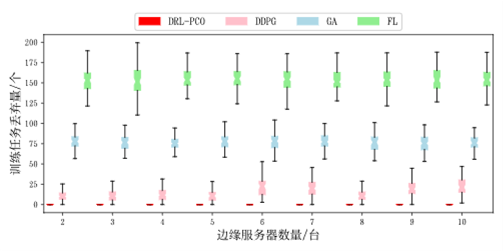
图8 训练任务丢弃量(不同边缘服务器数量)
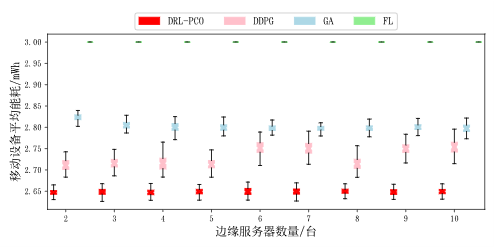
图9 移动设备平均能耗(不同边缘服务器数量)
最后,还比较了不同用户对算法性能造成的影响,也使用了箱线图展示数据。
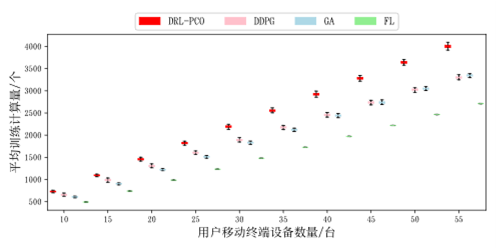
图10 平均训练计算量(不同用户数量)
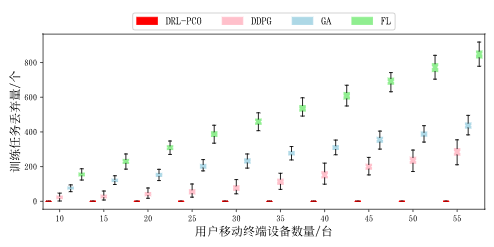
图11 训练任务丢弃量(不同用户数量)
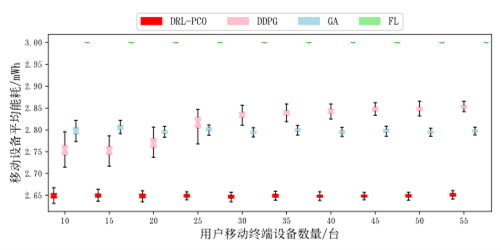
图12 移动设备平均能耗(不同用户数量)
通过上述实验,可以看出本文提出的方法能够满足不同场景下的性能需求,在绝大多数场景下都显著优于对比算法。
虽然近些年联邦学习已经成为了隐私保护机器学习的主流选择,但用户设备的计算性能限制了它的使用场景。为了在减轻用户设备的计算压力的同时保护用户隐私,本文提出了一个结合移动边缘计算的分布式机器学习系统。同时,本文设计了一个基于本地差分隐私的隐私保护算法与一个基于深度强化学习的任务卸载算法,能同时增强隐私与效率。最后,本文通过实验证明了本文算法的性能,它在计算性能与用户设备能耗中取得了较好的平衡。
黄霁崴,教授,博士生导师,中国石油大学(北京)信息科学与工程学院/人工智能学院副院长,石油数据挖掘北京市重点实验室主任。入选北京市优秀人才、北京市科技新星、北京市国家治理青年人才、昌聚工程青年人才、中国石油大学(北京)优秀青年学者。本科和博士毕业于清华大学计算机科学与技术系,美国佐治亚理工学院联合培养博士生。研究方向包括:物联网、服务计算、边缘智能等。已主持国家自然科学基金、国家重点研发计划、北京市自然科学基金等科研项目18项;以第一/通讯作者在国内外著名期刊和会议发表学术论文60余篇,其中1篇获得中国科协优秀论文奖,2篇入选ESI热点论文,4篇入选ESI高被引论文;出版学术专著1部;获得国家发明专利6项、软件著作权4项;获得中国通信学会科学技术一等奖1项、中国产学研合作创新成果一等奖1项、广东省计算机学会科学技术二等奖1项。担任中国计算机学会(CCF)服务计算专委会委员、秘书,CCF和IEEE高级会员,电子学报、Chinese Journal of Electronics、Scientific Programming等期刊编委。