
面向卷积神经网络协同推理的交错式算子划分
中文题目:面向卷积神经网络协同推理的交错式算子划分
论文题目:Cooperative Inference with Interleaved Operator Partitioning for CNNs
录用期刊/会议:International Conference on Intelligent Computing (ICIC) 2024 (CCF C)
原文链接:http://poster-openaccess.com/files/icic2024/2251
作者列表:
1)刘志邦 中国石油大学(北京)人工智能学院 控制科学与工程专业 博21
2)徐朝农 中国石油大学(北京)人工智能学院 计算机系 教师
3)刘志卓 中国石油大学(北京)人工智能学院 先进科学与工程计算专业 博22
4)黄乐楷 中国石油大学(北京)人工智能学院 计算机技术专业 硕22
5)魏嘉辰 中国石油大学(北京)人工智能学院 计算机科学与技术专业 硕22
6)李 超 之江实验室
文章简介:
目前,智能物联网(AIoT)已广泛应用于工业生产、自动驾驶、智能家电等多个领域。随着深度学习技术的兴起,智能模型在执行推理过程中对设备的计算和内存需求正在急剧增加。一方面,物联网设备的内存容量十分有限;另一方面,许多实际应用场景具有严格的实时响应需求。例如阀门泄漏的检测,需要毫秒级的响应时间,否则将会导致严重的安全隐患。协同推理是解决这一问题的重要方法。现有的协同推理方法通常将算子的输出通道或特征图的高和宽作为划分维度。由于算子的激活值分布在多个设备上,需要在传递给后继算子之前进行拼接操作,这将会引入额外的通信开销,增加推理延迟。针对这一问题,本文提出了一种新颖的AIoT协同推理方案——交错式算子划分(IOP)以减少智能模型的推理延迟。
本文的主要内容如下:
(1)提出了IOP,一种适用于CNN的协同推理加速方法,通过减少推理过程中所需的通信次数来降低推理延迟。
(2)基于IOP方案,对模型最小化推理延迟问题进行了建模。
(3)提出了一种启发式划分算法,该算法在所有包含两个算子的分段中应用IOP,以最小化协同推理延迟。
(4)使用多个CNN模型评估了IOP策略,表现出了优越的性能。
摘要:
分布式协同推理是解决在资源受限的智能物联网(AIoT)设备上部署深度学习模型的重要方法。现有的协同推理方法通常将算子的输出通道或特征图的高和宽作为划分维度。由于算子的输出激活分布在不同设备上,因此在传递给后继算子之前需要进行拼接,这将引入额外的通信开销,增加智能模型的推理延迟。针对这一问题,本文提出了一种适用于卷积神经网络(CNN)模型的交错式算子划分(IOP)策略。该策略通过基于输出通道维度对前级算子进行划分,并基于输入通道维度对其后继算子进行划分,避免了算子输出激活的拼接过程,从而减少了设备间建立通信连接的次数,降低了协同推理的延迟。此外,我们提出了一种模型划分算法,用于最小化协同推理时间,该算法通过基于推理延迟收益的贪婪算法来选择算子进行配对并应用IOP方案。实验结果表明,与CoEdge划分方法相比,IOP策略对LeNet,AlexNet和VGG11三个经典的图像分类模型实现了6.39%至16.83%的推理加速,并减少了21.22%至49.98%的设备峰值内存占用。
设计与实现:
我们假设所有设备的通信带宽和计算能力相对稳定。为了确保问题的准确表述,定义了以下必要的概念和符号:![]() 表示算子在推理过程中的执行顺序。
表示算子在推理过程中的执行顺序。![]() 表示可用设备的集合。
表示可用设备的集合。
![]() 用于描述可用计算设备
用于描述可用计算设备![]() 的信息,其中
的信息,其中![]() 表示设备的计算能力,
表示设备的计算能力,![]() 表示设备的存储能力,
表示设备的存储能力,![]() 表示设备间的通信带宽。
表示设备间的通信带宽。
![]() 用于表示可划分维度,其中
用于表示可划分维度,其中![]() ,
,![]() ,
,![]() ,表示算子
,表示算子![]() 所选择的划分维度,
所选择的划分维度,![]() 表示特征图的高维度,
表示特征图的高维度,![]() 和
和![]() 分别表示特征图的输入通道和输出通道维度。
分别表示特征图的输入通道和输出通道维度。
![]() 用于描述算子的属性。对于卷积算子,
用于描述算子的属性。对于卷积算子,![]() 表示输入通道数量,
表示输入通道数量,![]() 表示输出通道数量。
表示输出通道数量。![]() 表示卷积核的宽,
表示卷积核的宽,![]() 表示卷积核的高,
表示卷积核的高,![]() 表示步长,
表示步长,![]() 表示填充的大小。全连接算子作为一种特殊的卷积算子,
表示填充的大小。全连接算子作为一种特殊的卷积算子,![]() 表示输入维度大小,
表示输入维度大小,![]() 表示输出维度大小。
表示输出维度大小。
![]() 表示算子被划分成多个部分,其中
表示算子被划分成多个部分,其中![]() 部分被分配到设备
部分被分配到设备![]() 。
。![]() 表示设备
表示设备![]() 上算子
上算子![]() 的输入通道数量。
的输入通道数量。![]() 表示设备
表示设备![]() 上算子
上算子![]() 的输出通道数量。
的输出通道数量。![]() 和
和![]() 分别表示设备
分别表示设备![]() 上算子
上算子![]() 的权重和输出激活的内存占用大小。
的权重和输出激活的内存占用大小。
关于算子的划分维度和大小进行以下约束:
![]()
(1)
公式(1)表示部署在每个设备上的算子必须满足推理过程中的峰值内存占用小于设备容量。
![]()
(2)
公式(2)表示模型中的每个算子只能从H、IC和OC中选择一个划分维度。
![]()
(3)
![]()
(4)
![]()
(5)
公式(3)、(4)和(5)规定,在模型划分后,各部分算子在H、IC和OC维度的大小之和必须等于原算子在相应维度上的大小。![]() ,
,![]() 和
和![]() 的取值为0或1,分别代表是否选择算子的H、IC和OC维度进行划分。
的取值为0或1,分别代表是否选择算子的H、IC和OC维度进行划分。
![]()
(6)
![]()
(1), (2), (3), (4), (5)
模型的推理时间由两部分组成:计算延迟和通信延迟。其中,![]() 和
和![]() 分别表示算子
分别表示算子![]() 在设备
在设备![]() 上的计算延迟和通信延迟。
上的计算延迟和通信延迟。
![]()
(7)
![]()
(8)
其中,![]() 和
和![]() 分别表示在设备
分别表示在设备![]() 上执行算子
上执行算子![]() 所需要的计算量和通信量,这取决于所使用的算子划分方法;而
所需要的计算量和通信量,这取决于所使用的算子划分方法;而![]() 和
和![]() 的值由设备自身的属性决定。
的值由设备自身的属性决定。
为了找到最优划分方案以最小化协同推理延迟,设计了一种启发式算子配对算法。该算法从第一个算子开始,逐层搜索采用交错式划分方案的算子对。具体来说,对于算子![]() 及其后续算子
及其后续算子![]() ,比较使用IOP和CoEdge划分方法的推理时间。如果IOP方案实现了更短的推理时间,则将这两个算子配对形成一个新分段;否则,新分段仅包含算子
,比较使用IOP和CoEdge划分方法的推理时间。如果IOP方案实现了更短的推理时间,则将这两个算子配对形成一个新分段;否则,新分段仅包含算子![]() 。
。

实验结果及分析:
我们在三种典型的CNN模型中应用了IOP方案,分别为LeNet、AlexNet和VGG11。

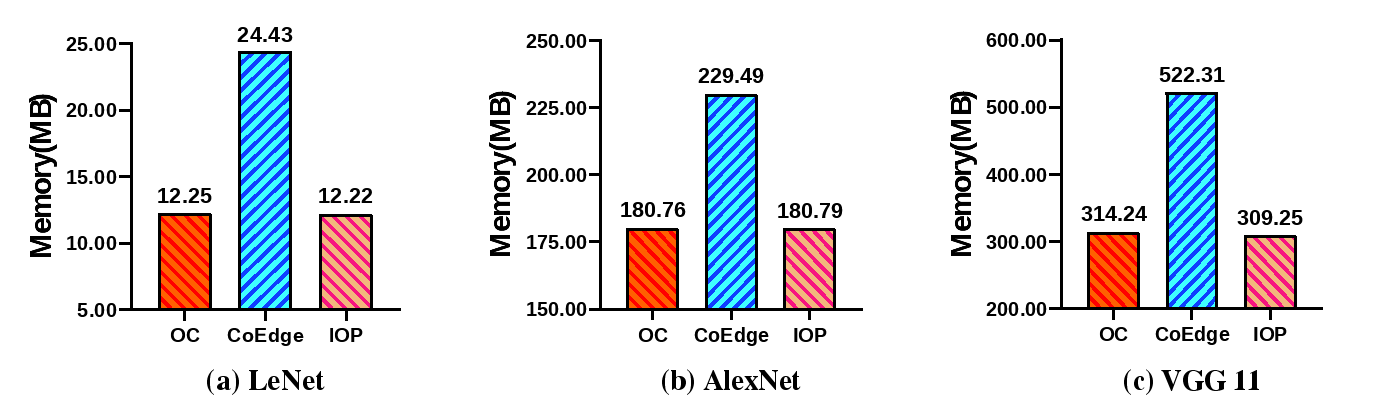
与OC方案相比,IOP在执行LeNet、AlexNet和VGG11模型推理时分别节省了31.53%、21.06%和12.82%的延迟。相较于CoEdge,IOP分别节省了12.05%、16.83%和6.39%的延迟。此外,与CoEdge方案相比,IOP在LeNet、AlexNet和VGG11执行推理过程中的峰值内存占用分别减少了49.98%、21.22%和40.79%。
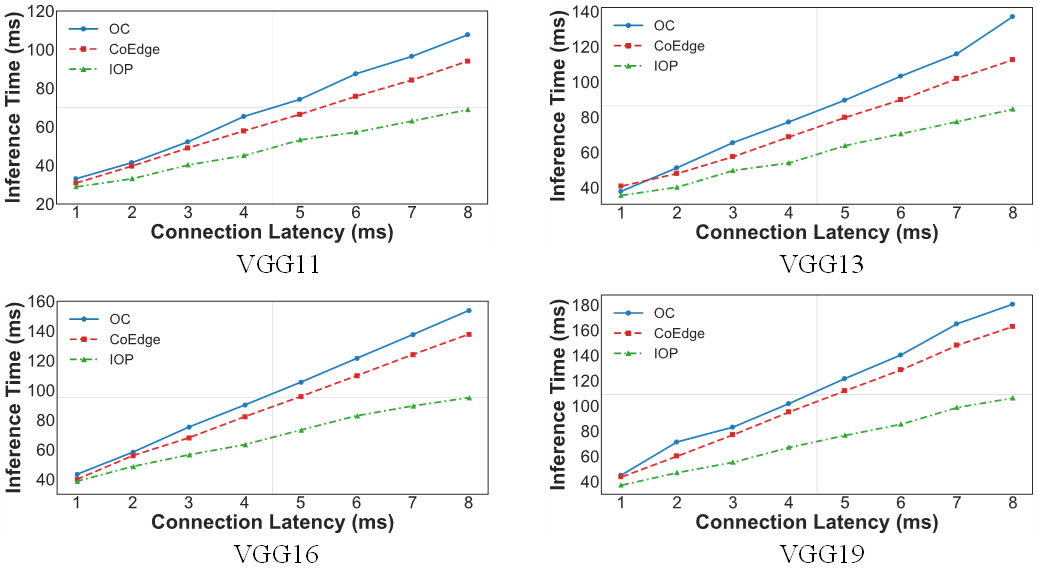
我们针对VGG11、VGG13、VGG16和VGG19,测试了设备间通信连接建立时间从1毫秒到8毫秒情况下的推理延迟。对于VGG11网络,使用IOP的推理延迟减少了14.51%至26.74%。而对于VGG13、VGG16和VGG19,IOP方案的推理延迟分别减少了12.99%至24.99%、3.34%至31.01%和15.01%至34.87%。
结论:
本文介绍了IOP,一种适用于CNN协同推理的低延迟模型划分策略。通过在相邻算子间采用IOP,减少了设备间多次建立通信连接所带来的开销,从而降低了模型推理延迟。我们将IOP最佳划分策略的搜索方案描述为组合优化问题。为有效解决该问题,我们设计了一种算子配对算法,以找到最优的模型划分策略。实验结果表明,对于LeNet、AlexNet和VGG11这三种广泛应用于图像分类的CNN模型,IOP相比最先进的CoEdge方案,实现了6.39%至16.83%的推理加速,并节省了21.22%至49.98%的峰值内存占用。
作者简介:
徐朝农,中国石油大学(北京)人工智能学院教师,主要研究领域为边缘智能、嵌入式系统、无线网络。