
基于双向语义缓解语义漂移的知识图谱多跳问答
中文题目:基于双向语义缓解语义漂移的知识图谱多跳问答
论文题目:Alleviating Semantic Drift in Multi-Hop Question Answering on Knowledge Graphs with Bidirectional Semantics
录用期刊/会议:International Joint Conference on Neural Networks (IJCNN) (CCF C)
作者列表:
1)袁明才 中国石油大学(北京)人工智能学院 计算机科学与技术 硕21
2)鲁 强 中国石油大学(北京)人工智能学院 智能科学与技术系 教师
3)曾显豪 中国石油大学(北京)人工智能学院 计算机技术 硕23
4)Jake Luo University of Wisconsin Milwaukee Department of Health Informatics and Administration Associate Professor
5)李大伟 中国石油勘探开发研究院 高级工程师
摘要:
知识图谱多跳问答利用知识图谱(KG)的结构信息来推断答案。然而,KG在从问题实体到答案实体的推理路径上往往存在边缺失。最近的研究集中在各种KG嵌入方法上,以获得推理路径的语义(称为正向语义)来修复缺失的边。但是,正向语义可能会随着路径变长而漂移。本文提出了一种双向语义嵌入与匹配方法(BSEM)来缓解正向语义漂移问题。BSEM首先利用反向语义来推导推理路径相反方向的语义。然后,BSEM构建了一种两阶段学习方法来联合学习双向语义并找到正确答案。在两阶段学习方法中,联合学习同时学习双向语义,促进两者的交互;对比学习则用来提高反向语义推理区分正向语义推理答案中错误答案的能力。在MetaQA和WebQSP两个基准测试上的实验表明,BSEM优于PullNet、EmQL、LEGO、EmbedKGQA和KGT5五种基准方法。特别是在不完整的KG—WebQSP实验设置中,与除EmQL外的其他四种方法相比,BSEM的准确率分别提高了13.1%、12.0%、5.4%和10.0%。
设计与实现:
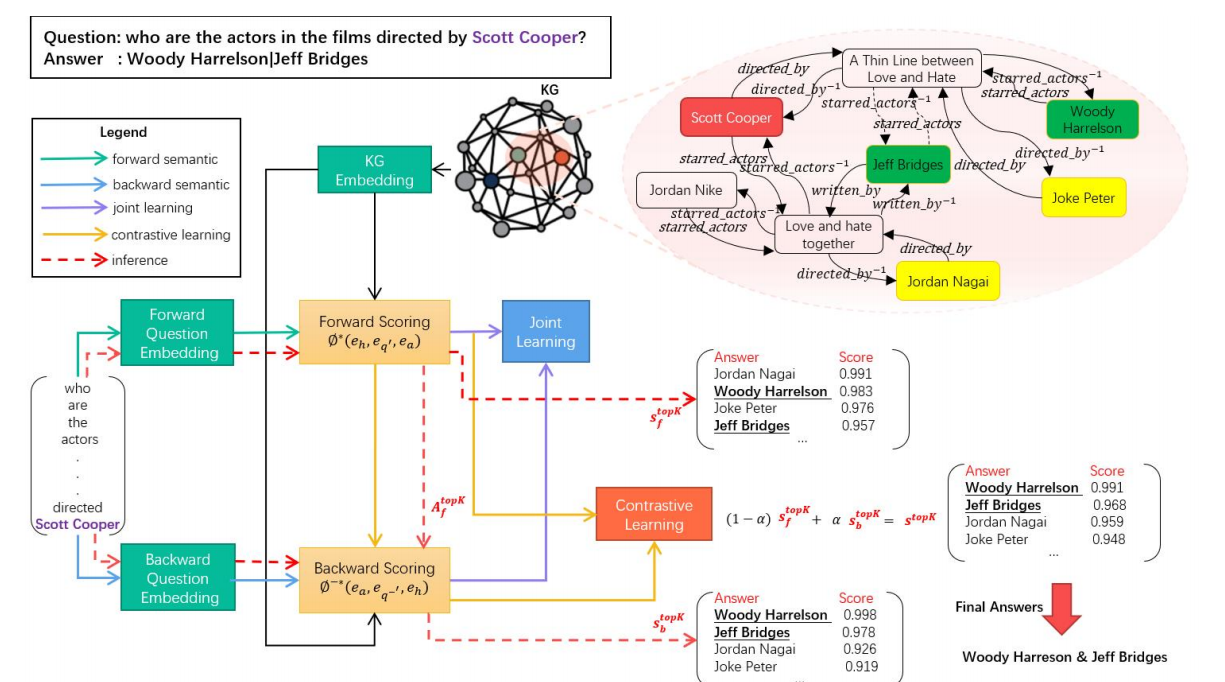
图1 BSEM的模型结构
双向语义嵌入与匹配方法(BSEM)模型结构如图1所示,包括三个模块:知识图谱嵌入模块、问题嵌入模块和语义推理模块。知识图谱嵌入模块利用了一种称为ComplEx的知识图谱嵌入方法,用于学习知识图谱中所有实体和关系的嵌入向量。问题嵌入模块用于生成给定问题的正向和反向语义表示。语义推理模块由正向推理![]() 和反向推理
和反向推理![]() 组成,利用前两个模块生成的语义向量进行推理计算,并对候选答案进行排序。在模型训练阶段,设计了一种两阶段学习方法,采用联合学习和对比学习来训练正向和反向推理。在模型预测阶段,将正向和反向推理结合起来,使用反向推理对正向推理的答案进行反向检验,从而推断出正确的答案。这种方法充分利用了知识图谱中实体之间的正反向推理语义信息,不仅提高了问答系统的性能和准确性,同时答案也具备一定的可解释性。
组成,利用前两个模块生成的语义向量进行推理计算,并对候选答案进行排序。在模型训练阶段,设计了一种两阶段学习方法,采用联合学习和对比学习来训练正向和反向推理。在模型预测阶段,将正向和反向推理结合起来,使用反向推理对正向推理的答案进行反向检验,从而推断出正确的答案。这种方法充分利用了知识图谱中实体之间的正反向推理语义信息,不仅提高了问答系统的性能和准确性,同时答案也具备一定的可解释性。
值得一提的是,当前并没有对应的反向推理问答数据集,同时推理路径中往往缺少反向的边,从而导致反向语义难以学习。为了克服这一困难,本文提出了一种新颖的反向语义推理评分函数,它利用了复数向量内积运算的对称性,将反向计算转换为正向计算。
![]()
其中,![]() 和
和![]() 分别代表答案实体和问句实体的复数嵌入向量,而
分别代表答案实体和问句实体的复数嵌入向量,而![]() 代表问句的反向语义嵌入向量,
代表问句的反向语义嵌入向量,![]() ,
,![]() 则表示共轭复数。
则表示共轭复数。
另外,在联合学习中,本文采用一种新颖的较差者优先评估策略来改进双向语义,其定义如下:
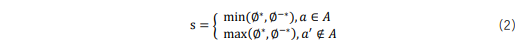
其中,![]() 为评估分数,指的是当前候选节点作为正确答案的得分。具体而言,在训练过程中,当
为评估分数,指的是当前候选节点作为正确答案的得分。具体而言,在训练过程中,当![]() 是正确答案时,评估策略取
是正确答案时,评估策略取![]() 和
和![]() 之间的较小值。相反,当
之间的较小值。相反,当![]() 不是正确答案时,评估策略采用
不是正确答案时,评估策略采用![]() 和
和![]() 之间的较大值。通过优先优化表现较差的方向,使得每次训练迭代都能够获得最大的收益。这样的策略有助于模型更好地学习到正向和反向推理之间的关系,从而提高了模型在推理任务中的性能表现。
之间的较大值。通过优先优化表现较差的方向,使得每次训练迭代都能够获得最大的收益。这样的策略有助于模型更好地学习到正向和反向推理之间的关系,从而提高了模型在推理任务中的性能表现。
同时,在对比学习中,本文利用了一种新颖的对比损失函数。该对比损失函数为每个正样本分配了加权分数,以反映其对反向语义推理![]() 的重要性。原因在于知识图谱存在缺失信息的情况,同一个问句对应的不同正样本与问句的主实体之间的推理路径可能不同,有的甚至缺失了重要的推理信息,导致整体推理的语义信息有强弱之分。该对比损失函数通过为每个正样本分配了不同的加权分数,综合了不同正样本对损失函数的贡献,这里的加权分数由正向语义推理获得,代表了不同正样本推理语义信息的强弱情况。
的重要性。原因在于知识图谱存在缺失信息的情况,同一个问句对应的不同正样本与问句的主实体之间的推理路径可能不同,有的甚至缺失了重要的推理信息,导致整体推理的语义信息有强弱之分。该对比损失函数通过为每个正样本分配了不同的加权分数,综合了不同正样本对损失函数的贡献,这里的加权分数由正向语义推理获得,代表了不同正样本推理语义信息的强弱情况。
该对比损失函数由以下方程定义:
![]()
其中,![]() 是训练数据集中的问题数量,
是训练数据集中的问题数量,![]() (
(![]() )是第
)是第![]() 个问题的正(负)样本集。
个问题的正(负)样本集。![]() 是
是![]() 中第i个实体的权重分数。将从正向语义推理获得的评估分数通过softmax函数传递,得到
中第i个实体的权重分数。将从正向语义推理获得的评估分数通过softmax函数传递,得到![]() 的权重分数
的权重分数![]() ,即:
,即:
![]()
实验结果及分析:
表1 MetaQA和WebQSP数据集的统计信息
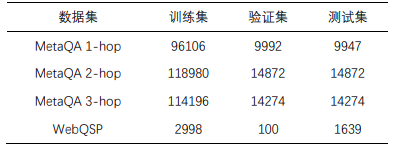
表2 在MetaQA half-KG数据集上的结果
表3 在 WebQSP half-KG 数据集上的结果
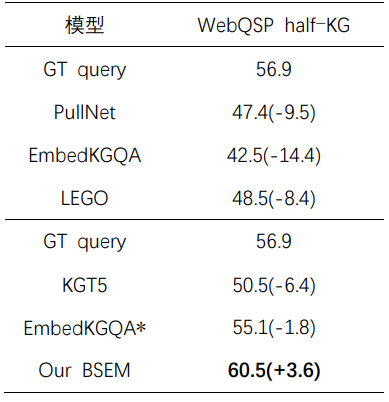
表4 在 WebQSP full-KG 数据集上的结果
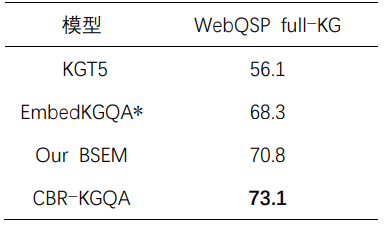
表5 消融实验
其中,“{-JL}”表示BSEM去除了联合学习;“{-CL}”表示去除了对比学习;而“{-JL and -CL}”则删除了联合学习、对比学习和反向语义推理。因此,在“{-JL and -CL}”之后,BSEM退化为仅包含正向语义的EmbedKGQA。
表6 权重分数的消融实验
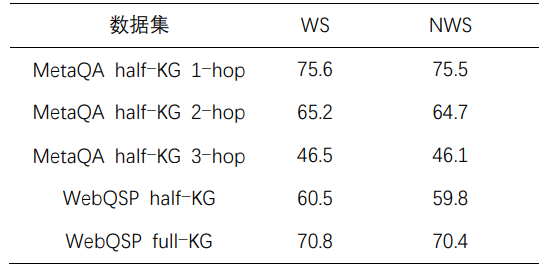
其中,“WS”代表本文方法,而“NWS”表示本文方法在对比学习中没有使用加权分数![]() 。
。
结论:
本章提出了基于双向语义的知识图谱问答方法(BSEM),一种新颖的双向语义嵌入和匹配方法,旨在缓解知识图谱多跳问答中正向语义漂移问题,在提升答案准确率的同时增强可解释性。BSEM利用反向语义推理对正向语义推理的答案进行反向检验,从而推断出更准确的答案。 在MetaQA和WebQSP两个基准测试上的实验表明,BSEM无论在half-KG还是full-KG中都能找到更准确的答案,尤其是在稀疏的知识图谱中,其性能提升显著。而BSEM利用反向语义推理验证正向语义推理答案可信度的过程具备一定的可解释性。
与PullNet、EMQL、LEGO、EmbedKGQA和KGT5等最先进方法相比,BSEM在知识图谱多跳问答中具有最佳的整体性能。然而,BSEM只能缓解推理路径中的语义漂移,而不能防止它。原因在于随着推理路径变得更长或重要信息的缺失,正向和反向语义仍然会漂移。受KGT5模型启发,未来计划探索基于双向语义的编码器-解码器模型,通过语言模型引入更多的外部知识,实现逐步推理校验,以防止语义漂移。
通讯作者简介:
鲁强,副教授,博士生导师。目前主要从事演化计算和符号回归、知识图谱与智能问答、以及轨迹分析与挖掘等方面的研究工作。联系方式:luqiang@cup.edu.cn